 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Compression Meets Model Compression: Memory-Efficient Double Compression for Large Language Models
Feb 21, 2025Large language models (LLMs) exhibit excellent performance in various tasks. However, the memory requirements of LLMs present a great challenge when deploying on memory-limited devices, even for quantized LLMs. This paper introduces a framework to compress LLM after quantization further, achieving about 2.2x compression ratio. A compression-aware quantization is first proposed to enhance model weight compressibility by re-scaling the model parameters before quantization, followed by a pruning method to improve further. Upon this, we notice that decompression can be a bottleneck during practical scenarios. We then give a detailed analysis of the trade-off between memory usage and latency brought by the proposed method. A speed-adaptive method is proposed to overcome it. The experimental results show inference with the compressed model can achieve a 40% reduction in memory size with negligible loss in accuracy and inference speed.
On the Compressibility of Quantized Large Language Models
Mar 03, 2024



Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
Accurate Fine-grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation
Oct 23, 2021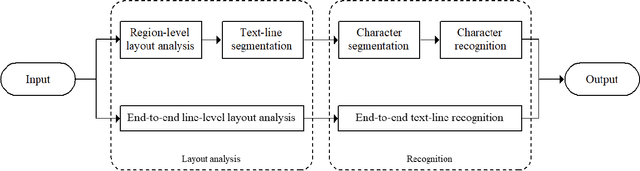



Accurate layout analysis without subsequent text-line segmentation remains an ongoing challenge, especially when facing the Kangyur, a kind of historical Tibetan document featuring considerable touching components and mottled background. Aiming at identifying different regions in document images, layout analysis is indispensable for subsequent procedures such as character recognition. However, there was only a little research being carried out to perform line-level layout analysis which failed to deal with the Kangyur. To obtain the optimal results, a fine-grained sub-line level layout analysis approach is presented. Firstly, we introduced an accelerated method to build the dataset which is dynamic and reliable. Secondly, enhancement had been made to the SOLOv2 according to the characteristics of the Kangyur. Then, we fed the enhanced SOLOv2 with the prepared annotation file during the training phase. Once the network is trained, instances of the text line, sentence, and titles can be segmented and identified during the inference stage. The experimental results show that the proposed method delivers a decent 72.7% AP on our dataset. In general, this preliminary research provides insights into the fine-grained sub-line level layout analysis and testifies the SOLOv2-based approaches. We also believe that the proposed methods can be adopted on other language documents with various layouts.