 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Fine-grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation
Oct 23, 2021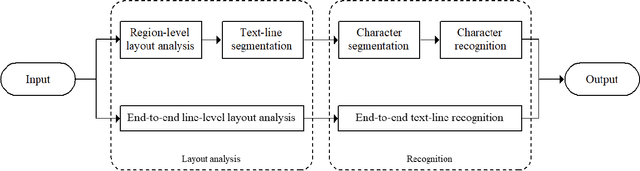



Accurate layout analysis without subsequent text-line segmentation remains an ongoing challenge, especially when facing the Kangyur, a kind of historical Tibetan document featuring considerable touching components and mottled background. Aiming at identifying different regions in document images, layout analysis is indispensable for subsequent procedures such as character recognition. However, there was only a little research being carried out to perform line-level layout analysis which failed to deal with the Kangyur. To obtain the optimal results, a fine-grained sub-line level layout analysis approach is presented. Firstly, we introduced an accelerated method to build the dataset which is dynamic and reliable. Secondly, enhancement had been made to the SOLOv2 according to the characteristics of the Kangyur. Then, we fed the enhanced SOLOv2 with the prepared annotation file during the training phase. Once the network is trained, instances of the text line, sentence, and titles can be segmented and identified during the inference stage. The experimental results show that the proposed method delivers a decent 72.7% AP on our dataset. In general, this preliminary research provides insights into the fine-grained sub-line level layout analysis and testifies the SOLOv2-based approaches. We also believe that the proposed methods can be adopted on other language documents with various layouts.