 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-DREAM: Brain Inspired Hierarchical Diffusion for fMRI Reconstruction via ROI Encoder and visuAl Mapping
Nov 14, 2025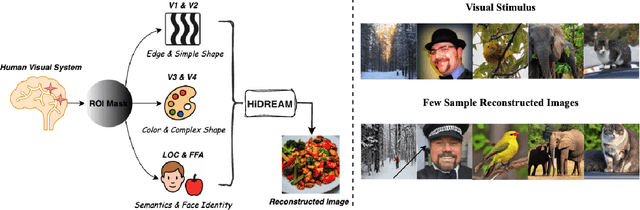
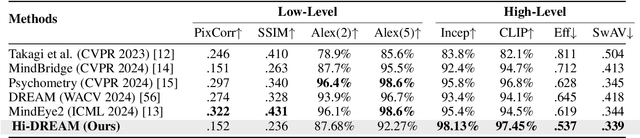
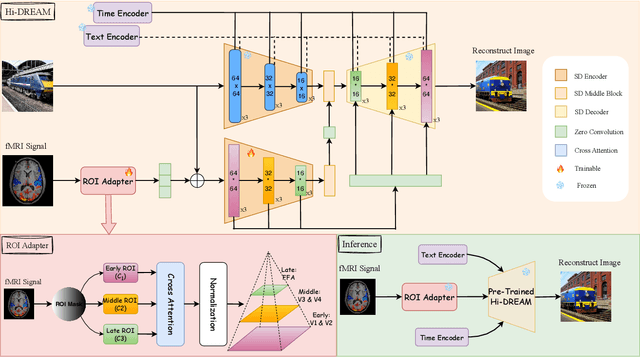
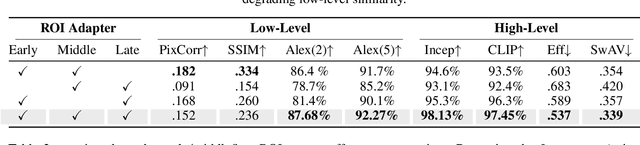
Mapping human brain activity to natural images offers a new window into vision and cognition, yet current diffusion-based decoders face a core difficulty: most condition directly on fMRI features without analyzing how visual information is organized across the cortex. This overlooks the brain's hierarchical processing and blurs the roles of early, middle, and late visual areas. We propose Hi-DREAM, a brain-inspired conditional diffusion framework that makes the cortical organization explicit. A region-of-interest (ROI) adapter groups fMRI into early/mid/late streams and converts them into a multi-scale cortical pyramid aligned with the U-Net depth (shallow scales preserve layout and edges; deeper scales emphasize objects and semantics). A lightweight, depth-matched ControlNet injects these scale-specific hints during denoising. The result is an efficient and interpretable decoder in which each signal plays a brain-like role, allowing the model not only to reconstruct images but also to illuminate functional contributions of different visual areas. Experiments on the Natural Scenes Dataset (NSD) show that Hi-DREAM attains state-of-the-art performance on high-level semantic metrics while maintaining competitive low-level fidelity. These findings suggest that structuring conditioning by cortical hierarchy is a powerful alternative to purely data-driven embeddings and provides a useful lens for studying the visual cortex.
Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
Jan 15, 2024



Enabling robotic manipulation that generalizes to out-of-distribution scenes is a crucial step toward open-world embodied intelligence. For human beings, this ability is rooted in the understanding of semantic correspondence among objects, which naturally transfers the interaction experience of familiar objects to novel ones. Although robots lack such a reservoir of interaction experience, the vast availability of human videos on the Internet may serve as a valuable resource, from which we extract an affordance memory including the contact points. Inspired by the natural way humans think, we propose Robo-ABC: when confronted with unfamiliar objects that require generalization, the robot can acquire affordance by retrieving objects that share visual or semantic similarities from the affordance memory. The next step is to map the contact points of the retrieved objects to the new object. While establishing this correspondence may present formidable challenges at first glance, recent research finds it naturally arises from pre-trained diffusion models, enabling affordance mapping even across disparate object categories. Through the Robo-ABC framework, robots may generalize to manipulate out-of-category objects in a zero-shot manner without any manual annotation, additional training, part segmentation, pre-coded knowledge, or viewpoint restrictions. Quantitatively, Robo-ABC significantly enhances the accuracy of visual affordance retrieval by a large margin of 31.6% compared to state-of-the-art (SOTA) end-to-end affordance models. We also conduct real-world experiments of cross-category object-grasping tasks. Robo-ABC achieved a success rate of 85.7%, proving its capacity for real-world tasks.
A Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022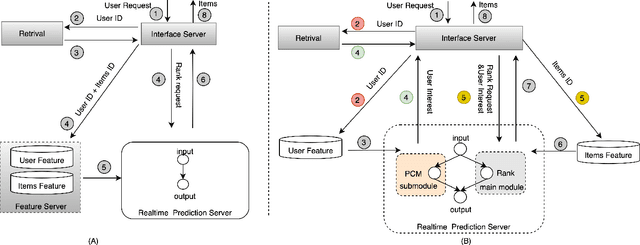

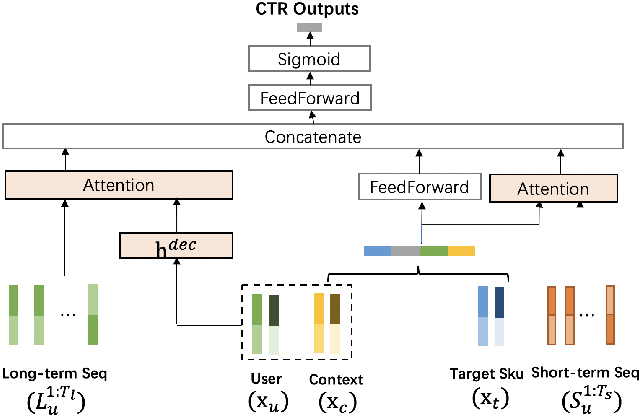
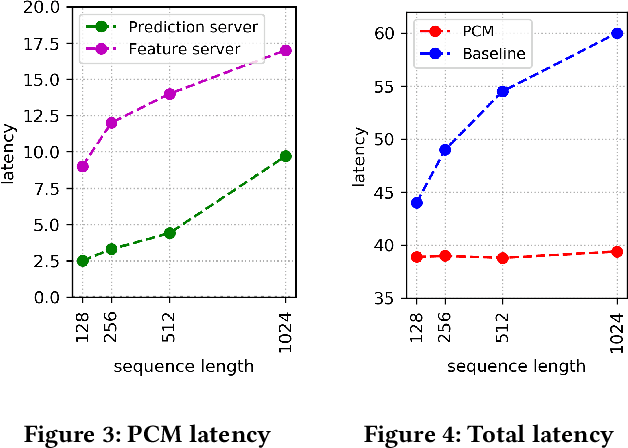
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
Accurate Fine-grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation
Oct 23, 2021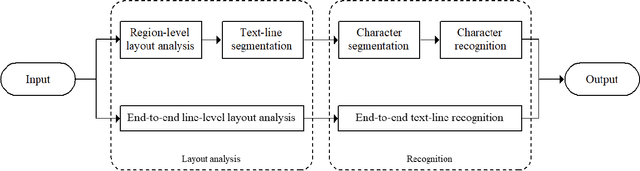



Accurate layout analysis without subsequent text-line segmentation remains an ongoing challenge, especially when facing the Kangyur, a kind of historical Tibetan document featuring considerable touching components and mottled background. Aiming at identifying different regions in document images, layout analysis is indispensable for subsequent procedures such as character recognition. However, there was only a little research being carried out to perform line-level layout analysis which failed to deal with the Kangyur. To obtain the optimal results, a fine-grained sub-line level layout analysis approach is presented. Firstly, we introduced an accelerated method to build the dataset which is dynamic and reliable. Secondly, enhancement had been made to the SOLOv2 according to the characteristics of the Kangyur. Then, we fed the enhanced SOLOv2 with the prepared annotation file during the training phase. Once the network is trained, instances of the text line, sentence, and titles can be segmented and identified during the inference stage. The experimental results show that the proposed method delivers a decent 72.7% AP on our dataset. In general, this preliminary research provides insights into the fine-grained sub-line level layout analysis and testifies the SOLOv2-based approaches. We also believe that the proposed methods can be adopted on other language documents with various layouts.
MBDF-Net: Multi-Branch Deep Fusion Network for 3D Object Detection
Aug 29, 2021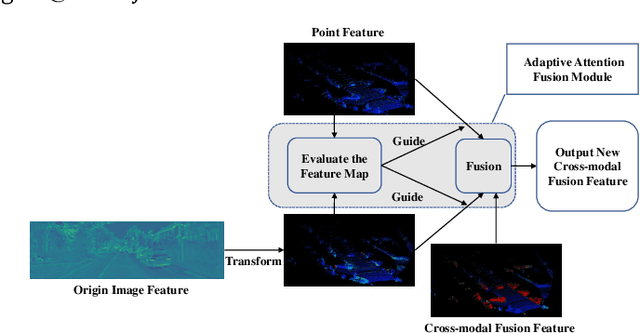
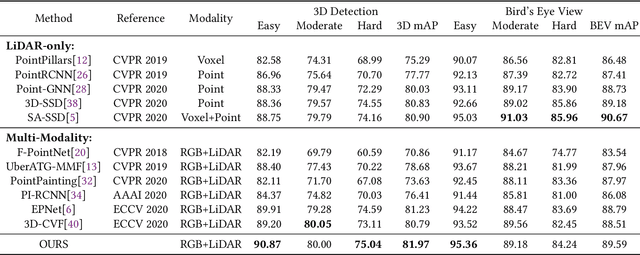
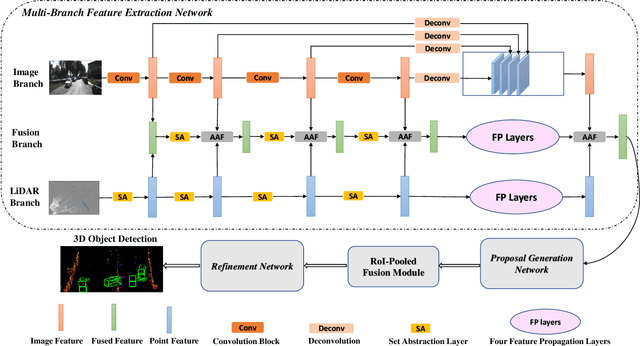
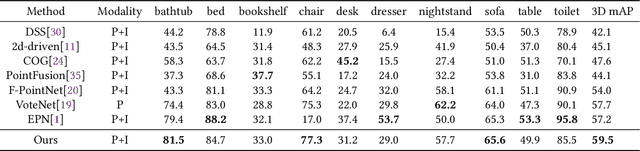
Point clouds and images could provide complementary information when representing 3D objects. Fusing the two kinds of data usually helps to improve the detection results. However, it is challenging to fuse the two data modalities, due to their different characteristics and the interference from the non-interest areas. To solve this problem, we propose a Multi-Branch Deep Fusion Network (MBDF-Net) for 3D object detection. The proposed detector has two stages. In the first stage, our multi-branch feature extraction network utilizes Adaptive Attention Fusion (AAF) modules to produce cross-modal fusion features from single-modal semantic features. In the second stage, we use a region of interest (RoI) -pooled fusion module to generate enhanced local features for refinement. A novel attention-based hybrid sampling strategy is also proposed for selecting key points in the downsampling process. We evaluate our approach on two widely used benchmark datasets including KITTI and SUN-RGBD. The experimental results demonstrate the advantages of our method over state-of-the-art approaches.
GIPA: General Information Propagation Algorithm for Graph Learning
May 13, 2021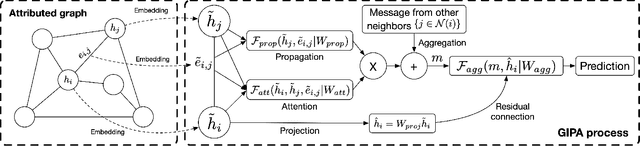
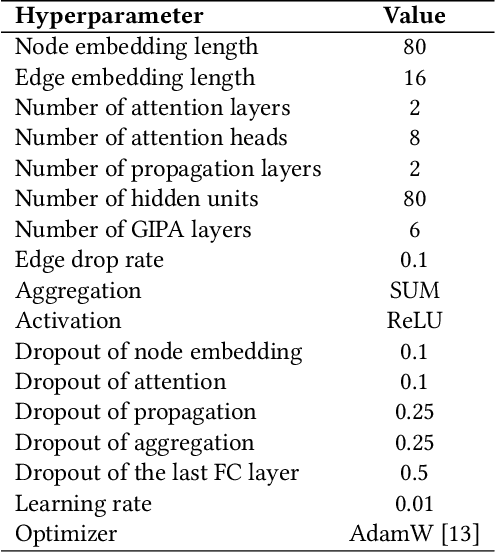
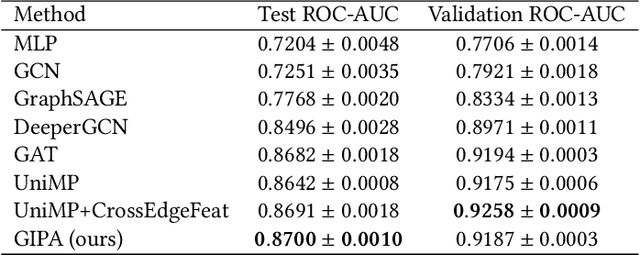
Graph neural networks (GNNs) have been popularly used in analyzing graph-structured data, showing promising results in various applications such as node classification, link prediction and network recommendation. In this paper, we present a new graph attention neural network, namely GIPA, for attributed graph data learning. GIPA consists of three key components: attention, feature propagation and aggregation. Specifically, the attention component introduces a new multi-layer perceptron based multi-head to generate better non-linear feature mapping and representation than conventional implementations such as dot-product. The propagation component considers not only node features but also edge features, which differs from existing GNNs that merely consider node features. The aggregation component uses a residual connection to generate the final embedding. We evaluate the performance of GIPA using the Open Graph Benchmark proteins (ogbn-proteins for short) dataset. The experimental results reveal that GIPA can beat the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8700\pm 0.0010$ and outperforms all the previous methods listed in the ogbn-proteins leaderboard.
GraphTheta: A Distributed Graph Neural Network Learning System With Flexible Training Strategy
Apr 21, 2021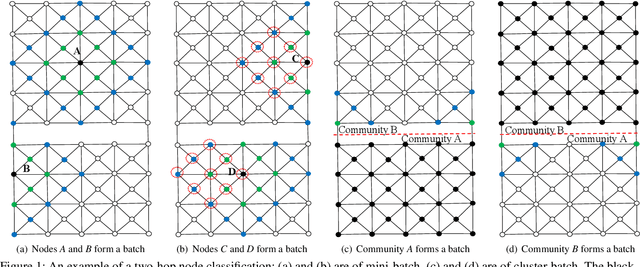
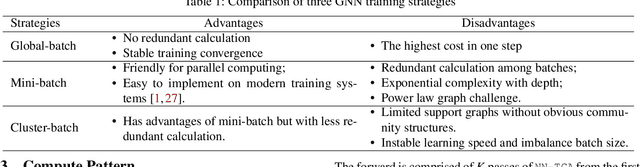
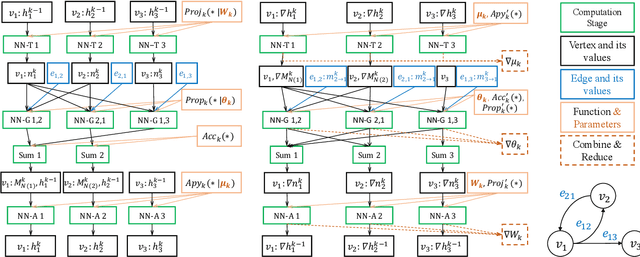
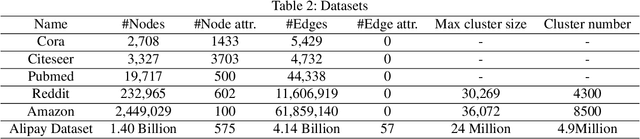
Graph neural networks (GNNs) have been demonstrated as a powerful tool for analysing non-Euclidean graph data. However, the lack of efficient distributed graph learning systems severely hinders applications of GNNs, especially when graphs are big, of high density or with highly skewed node degree distributions. In this paper, we present a new distributed graph learning system GraphTheta, which supports multiple training strategies and enables efficient and scalable learning on big graphs. GraphTheta implements both localized and globalized graph convolutions on graphs, where a new graph learning abstraction NN-TGAR is designed to bridge the gap between graph processing and graph learning frameworks. A distributed graph engine is proposed to conduct the stochastic gradient descent optimization with hybrid-parallel execution. Moreover, we add support for a new cluster-batched training strategy in addition to the conventional global-batched and mini-batched ones. We evaluate GraphTheta using a number of network data with network size ranging from small-, modest- to large-scale. Experimental results show that GraphTheta scales almost linearly to 1,024 workers and trains an in-house developed GNN model within 26 hours on Alipay dataset of 1.4 billion nodes and 4.1 billion attributed edges. Moreover, GraphTheta also obtains better prediction results than the state-of-the-art GNN methods. To the best of our knowledge, this work represents the largest edge-attributed GNN learning task conducted on a billion-scale network in the literature.
A New Unified Deep Learning Approach with Decomposition-Reconstruction-Ensemble Framework for Time Series Forecasting
Feb 22, 2020

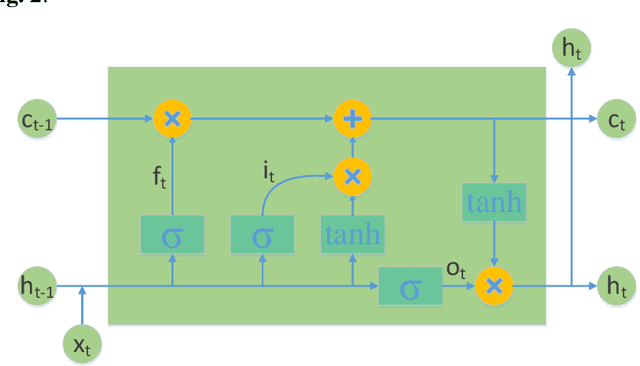
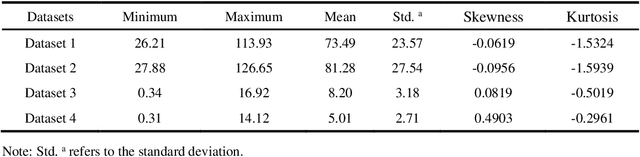
A new variational mode decomposition (VMD) based deep learning approach is proposed in this paper for time series forecasting problem. Firstly, VMD is adopted to decompose the original time series into several sub-signals. Then, a convolutional neural network (CNN) is applied to learn the reconstruction patterns on the decomposed sub-signals to obtain several reconstructed sub-signals. Finally, a long short term memory (LSTM) network is employed to forecast the time series with the decomposed sub-signals and the reconstructed sub-signals as inputs. The proposed VMD-CNN-LSTM approach is originated from the decomposition-reconstruction-ensemble framework, and innovated by embedding the reconstruction, single forecasting, and ensemble steps in a unified deep learning approach. To verify the forecasting performance of the proposed approach, four typical time series datasets are introduced for empirical analysis. The empirical results demonstrate that the proposed approach outperforms consistently the benchmark approaches in terms of forecasting accuracy, and also indicate that the reconstructed sub-signals obtained by CNN is of importance for further improving the forecasting performance.