 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphTheta: A Distributed Graph Neural Network Learning System With Flexible Training Strategy
Apr 21, 2021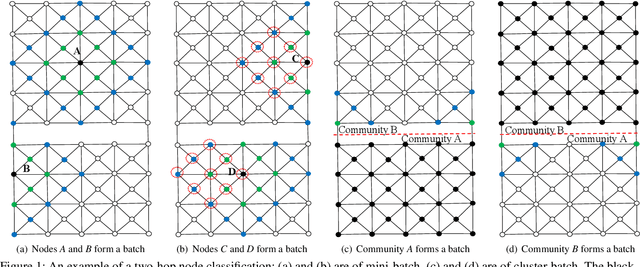
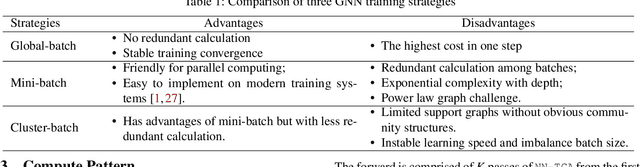
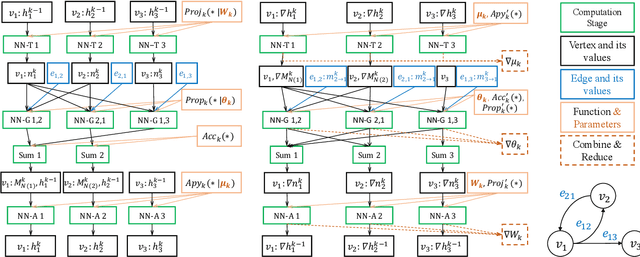
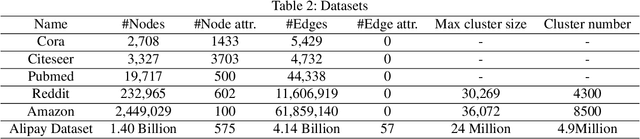
Graph neural networks (GNNs) have been demonstrated as a powerful tool for analysing non-Euclidean graph data. However, the lack of efficient distributed graph learning systems severely hinders applications of GNNs, especially when graphs are big, of high density or with highly skewed node degree distributions. In this paper, we present a new distributed graph learning system GraphTheta, which supports multiple training strategies and enables efficient and scalable learning on big graphs. GraphTheta implements both localized and globalized graph convolutions on graphs, where a new graph learning abstraction NN-TGAR is designed to bridge the gap between graph processing and graph learning frameworks. A distributed graph engine is proposed to conduct the stochastic gradient descent optimization with hybrid-parallel execution. Moreover, we add support for a new cluster-batched training strategy in addition to the conventional global-batched and mini-batched ones. We evaluate GraphTheta using a number of network data with network size ranging from small-, modest- to large-scale. Experimental results show that GraphTheta scales almost linearly to 1,024 workers and trains an in-house developed GNN model within 26 hours on Alipay dataset of 1.4 billion nodes and 4.1 billion attributed edges. Moreover, GraphTheta also obtains better prediction results than the state-of-the-art GNN methods. To the best of our knowledge, this work represents the largest edge-attributed GNN learning task conducted on a billion-scale network in the literature.