 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
GIPA: General Information Propagation Algorithm for Graph Learning
May 13, 2021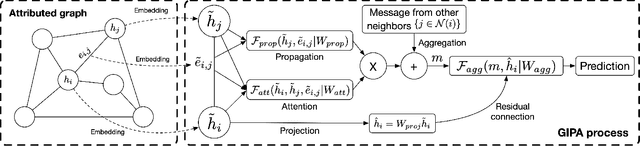
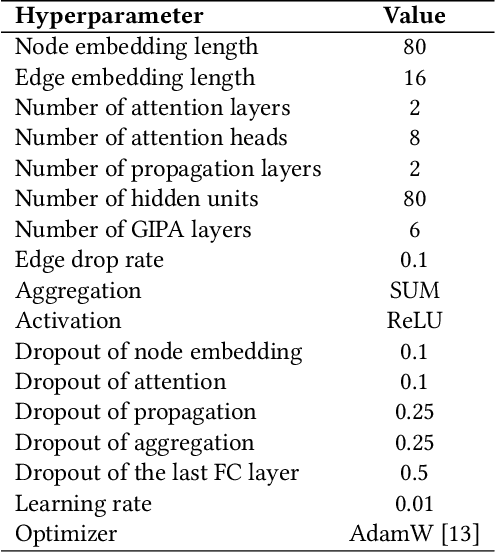
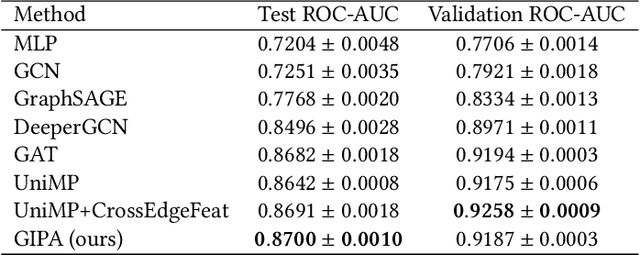
Graph neural networks (GNNs) have been popularly used in analyzing graph-structured data, showing promising results in various applications such as node classification, link prediction and network recommendation. In this paper, we present a new graph attention neural network, namely GIPA, for attributed graph data learning. GIPA consists of three key components: attention, feature propagation and aggregation. Specifically, the attention component introduces a new multi-layer perceptron based multi-head to generate better non-linear feature mapping and representation than conventional implementations such as dot-product. The propagation component considers not only node features but also edge features, which differs from existing GNNs that merely consider node features. The aggregation component uses a residual connection to generate the final embedding. We evaluate the performance of GIPA using the Open Graph Benchmark proteins (ogbn-proteins for short) dataset. The experimental results reveal that GIPA can beat the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8700\pm 0.0010$ and outperforms all the previous methods listed in the ogbn-proteins leaderboard.
GraphTheta: A Distributed Graph Neural Network Learning System With Flexible Training Strategy
Apr 21, 2021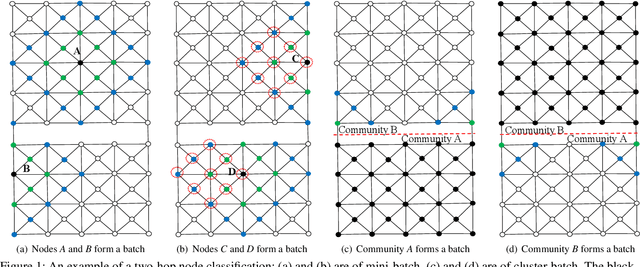
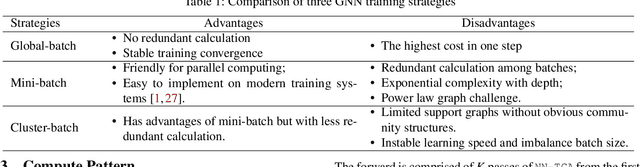
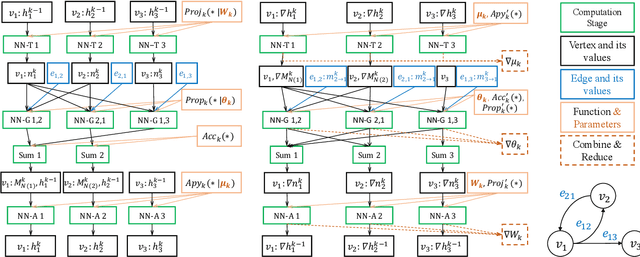
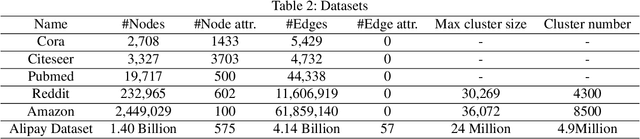
Graph neural networks (GNNs) have been demonstrated as a powerful tool for analysing non-Euclidean graph data. However, the lack of efficient distributed graph learning systems severely hinders applications of GNNs, especially when graphs are big, of high density or with highly skewed node degree distributions. In this paper, we present a new distributed graph learning system GraphTheta, which supports multiple training strategies and enables efficient and scalable learning on big graphs. GraphTheta implements both localized and globalized graph convolutions on graphs, where a new graph learning abstraction NN-TGAR is designed to bridge the gap between graph processing and graph learning frameworks. A distributed graph engine is proposed to conduct the stochastic gradient descent optimization with hybrid-parallel execution. Moreover, we add support for a new cluster-batched training strategy in addition to the conventional global-batched and mini-batched ones. We evaluate GraphTheta using a number of network data with network size ranging from small-, modest- to large-scale. Experimental results show that GraphTheta scales almost linearly to 1,024 workers and trains an in-house developed GNN model within 26 hours on Alipay dataset of 1.4 billion nodes and 4.1 billion attributed edges. Moreover, GraphTheta also obtains better prediction results than the state-of-the-art GNN methods. To the best of our knowledge, this work represents the largest edge-attributed GNN learning task conducted on a billion-scale network in the literature.