 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Multimodal Human Activity Recognition with Limited Labeled Data
Apr 25, 2026Human activity recognition serves as the foundation for various emerging applications. In recent years, researchers have used collaborative sensing of multi-source sensors to capture complex and dynamic human activities. However, multimodal human activity sensing typically encounters highly heterogeneous data across modalities and label scarcity, resulting in an application gap between existing solutions and real-world needs. In this paper, we propose CLMM, a general contrastive learning framework for human activity recognition that achieves effective multimodal recognition with limited labeled data. CLMM employs a novel two-stage training strategy. In the first stage, CLMM employs a CNN-DiffTransformer encoder to capture cross-modal shared information by extracting local and global features. Meanwhile, a hard-positive samples weighting algorithm enhances gradient propagation to reinforce shared learning. In the second stage, a dual-branch architecture combining quality-guided attention and bidirectional gated units captures modality-specific information, while a primary-auxiliary collaborative training strategy fuses both shared and modality-specific information. Experimental results on three public datasets demonstrate that CLMM significantly improves state-of-the-art baselines in both recognition accuracy and convergence performance.
Unlocking Optical Prior: Spectrum-Guided Knowledge Transfer for SAR Generalized Category Discovery
Apr 24, 2026Generalized Category Discovery (GCD) holds significant promise for the label-scarce Synthetic Aperture Radar (SAR) domain, yet its efficacy is severely constrained by the cross-modal incompatibility between the inherent optical prior of the Large Vision Models (LVMs) and SAR imagery. Existing domain adaptation methods often lack an inductive bias that reflects imaging characteristics, consequently failing to effectively transfer optical prior into the SAR domain. To address this issue, the Modal Discrepancy Curve (MDC) is introduced to model cross-modal discrepancy as a structured frequency-domain descriptor derived from spectral energy distributions. Leveraging this formulation, we propose the MDC-guided Cross-modal Prior Transfer (MCPT) framework, a pre-training paradigm that operates on paired optical-SAR data. Within this framework, Adaptive Frequency Tokenization (AFT) converts the MDC into learnable tokens, and Frequency-aware Expert Refinement (FER) performs band-wise discrepancy-aware feature refinement using these tokens. Based on the refined representations, contrastive learning aligns refined embeddings across modalities and internalizes the adaptation pattern. Ultimately, the superior SAR feature representation capability learned during paired pre-training is applied to downstream single-modal SAR-GCD tasks. Extensive experiments demonstrate state-of-the-art performance across multiple mainstream datasets, indicating that frequency-domain discrepancy modeling enables more effective adaptation of optical prior to SAR imagery.
JFTA-Bench: Evaluate LLM's Ability of Tracking and Analyzing Malfunctions Using Fault Trees
Mar 24, 2026In the maintenance of complex systems, fault trees are used to locate problems and provide targeted solutions. To enable fault trees stored as images to be directly processed by large language models, which can assist in tracking and analyzing malfunctions, we propose a novel textual representation of fault trees. Building on it, we construct a benchmark for multi-turn dialogue systems that emphasizes robust interaction in complex environments, evaluating a model's ability to assist in malfunction localization, which contains $3130$ entries and $40.75$ turns per entry on average. We train an end-to-end model to generate vague information to reflect user behavior and introduce long-range rollback and recovery procedures to simulate user error scenarios, enabling assessment of a model's integrated capabilities in task tracking and error recovery, and Gemini 2.5 pro archives the best performance.
Scan Clusters, Not Pixels: A Cluster-Centric Paradigm for Efficient Ultra-high-definition Image Restoration
Feb 25, 2026Ultra-High-Definition (UHD) image restoration is trapped in a scalability crisis: existing models, bound to pixel-wise operations, demand unsustainable computation. While state space models (SSMs) like Mamba promise linear complexity, their pixel-serial scanning remains a fundamental bottleneck for the millions of pixels in UHD content. We ask: must we process every pixel to understand the image? This paper introduces C$^2$SSM, a visual state space model that breaks this taboo by shifting from pixel-serial to cluster-serial scanning. Our core discovery is that the rich feature distribution of a UHD image can be distilled into a sparse set of semantic centroids via a neural-parameterized mixture model. C$^2$SSM leverages this to reformulate global modeling into a novel dual-path process: it scans and reasons over a handful of cluster centers, then diffuses the global context back to all pixels through a principled similarity distribution, all while a lightweight modulator preserves fine details. This cluster-centric paradigm achieves a decisive leap in efficiency, slashing computational costs while establishing new state-of-the-art results across five UHD restoration tasks. More than a solution, C$^2$SSM charts a new course for efficient large-scale vision: scan clusters, not pixels.
MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Feb 16, 2026We present MedXIAOHE, a medical vision-language foundation model designed to advance general-purpose medical understanding and reasoning in real-world clinical applications. MedXIAOHE achieves state-of-the-art performance across diverse medical benchmarks and surpasses leading closed-source multimodal systems on multiple capabilities. To achieve this, we propose an entity-aware continual pretraining framework that organizes heterogeneous medical corpora to broaden knowledge coverage and reduce long-tail gaps (e.g., rare diseases). For medical expert-level reasoning and interaction, MedXIAOHE incorporates diverse medical reasoning patterns via reinforcement learning and tool-augmented agentic training, enabling multi-step diagnostic reasoning with verifiable decision traces. To improve reliability in real-world use, MedXIAOHE integrates user-preference rubrics, evidence-grounded reasoning, and low-hallucination long-form report generation, with improved adherence to medical instructions. We release this report to document our practical design choices, scaling insights, and evaluation framework, hoping to inspire further research.
Muse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control
Jan 08, 2026Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
Blind Super-Resolution via Meta-learning and Markov Chain Monte Carlo Simulation
Jun 13, 2024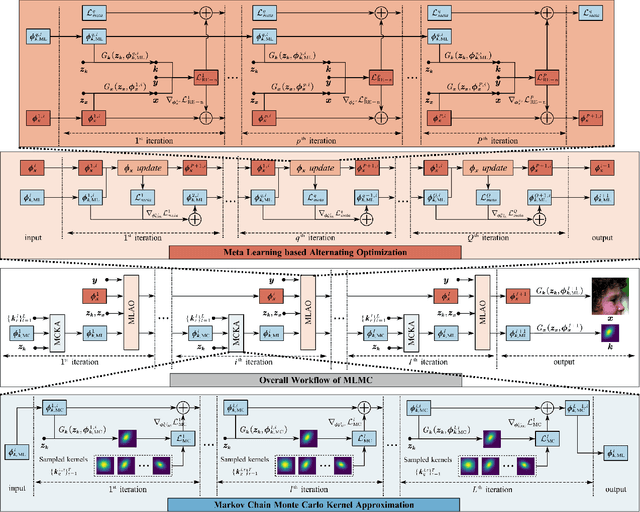
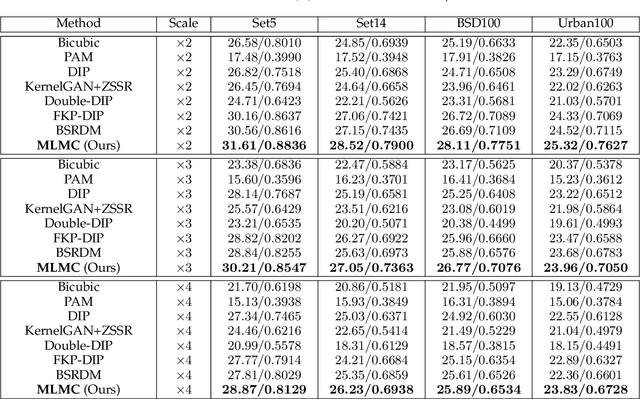
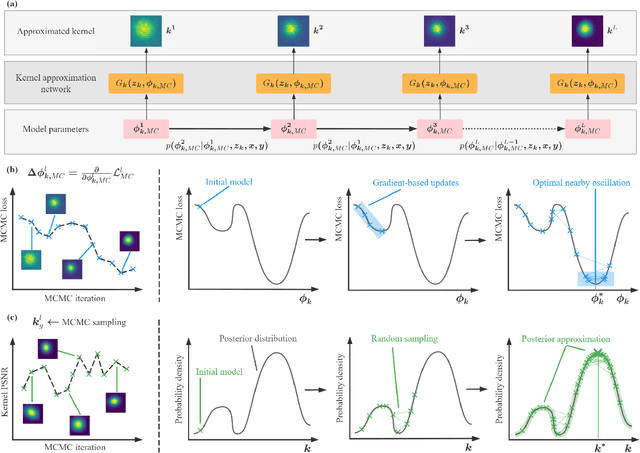
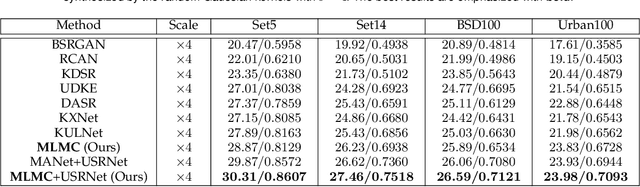
Learning-based approaches have witnessed great successes in blind single image super-resolution (SISR) tasks, however, handcrafted kernel priors and learning based kernel priors are typically required. In this paper, we propose a Meta-learning and Markov Chain Monte Carlo (MCMC) based SISR approach to learn kernel priors from organized randomness. In concrete, a lightweight network is adopted as kernel generator, and is optimized via learning from the MCMC simulation on random Gaussian distributions. This procedure provides an approximation for the rational blur kernel, and introduces a network-level Langevin dynamics into SISR optimization processes, which contributes to preventing bad local optimal solutions for kernel estimation. Meanwhile, a meta-learning-based alternating optimization procedure is proposed to optimize the kernel generator and image restorer, respectively. In contrast to the conventional alternating minimization strategy, a meta-learning-based framework is applied to learn an adaptive optimization strategy, which is less-greedy and results in better convergence performance. These two procedures are iteratively processed in a plug-and-play fashion, for the first time, realizing a learning-based but plug-and-play blind SISR solution in unsupervised inference. Extensive simulations demonstrate the superior performance and generalization ability of the proposed approach when comparing with state-of-the-arts on synthesis and real-world datasets. The code is available at https://github.com/XYLGroup/MLMC.
A Dynamic Kernel Prior Model for Unsupervised Blind Image Super-Resolution
Apr 26, 2024



Deep learning-based methods have achieved significant successes on solving the blind super-resolution (BSR) problem. However, most of them request supervised pre-training on labelled datasets. This paper proposes an unsupervised kernel estimation model, named dynamic kernel prior (DKP), to realize an unsupervised and pre-training-free learning-based algorithm for solving the BSR problem. DKP can adaptively learn dynamic kernel priors to realize real-time kernel estimation, and thereby enables superior HR image restoration performances. This is achieved by a Markov chain Monte Carlo sampling process on random kernel distributions. The learned kernel prior is then assigned to optimize a blur kernel estimation network, which entails a network-based Langevin dynamic optimization strategy. These two techniques ensure the accuracy of the kernel estimation. DKP can be easily used to replace the kernel estimation models in the existing methods, such as Double-DIP and FKP-DIP, or be added to the off-the-shelf image restoration model, such as diffusion model. In this paper, we incorporate our DKP model with DIP and diffusion model, referring to DIP-DKP and Diff-DKP, for validations. Extensive simulations on Gaussian and motion kernel scenarios demonstrate that the proposed DKP model can significantly improve the kernel estimation with comparable runtime and memory usage, leading to state-of-the-art BSR results. The code is available at https://github.com/XYLGroup/DKP.
A Meta-Learning Based Gradient Descent Algorithm for MU-MIMO Beamforming
Oct 27, 2022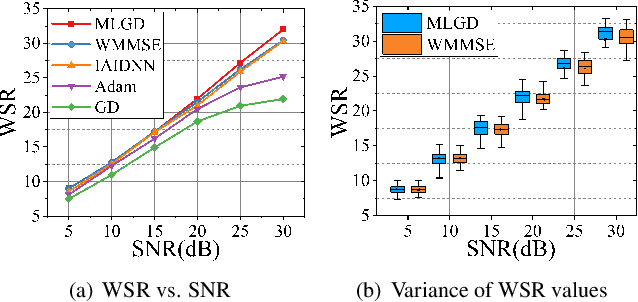

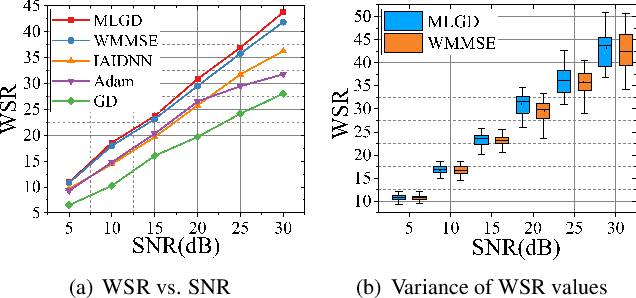
Multi-user multiple-input multiple-output (MU-MIMO) beamforming design is typically formulated as a non-convex weighted sum rate (WSR) maximization problem that is known to be NP-hard. This problem is solved either by iterative algorithms, which suffer from slow convergence, or more recently by using deep learning tools, which require time-consuming pre-training process. In this paper, we propose a low-complexity meta-learning based gradient descent algorithm. A meta network with lightweight architecture is applied to learn an adaptive gradient descent update rule to directly optimize the beamformer. This lightweight network is trained during the iterative optimization process, which we refer to as \emph{training while solving}, which removes both the training process and the data-dependency of existing deep learning based solutions.Extensive simulations show that the proposed method achieves superior WSR performance compared to existing learning-based approaches as well as the conventional WMMSE algorithm, while enjoying much lower computational load.