 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachines Serve Human: A Novel Variable Human-machine Collaborative Compression Framework
Nov 12, 2025


Human-machine collaborative compression has been receiving increasing research efforts for reducing image/video data, serving as the basis for both human perception and machine intelligence. Existing collaborative methods are dominantly built upon the de facto human-vision compression pipeline, witnessing deficiency on complexity and bit-rates when aggregating the machine-vision compression. Indeed, machine vision solely focuses on the core regions within the image/video, requiring much less information compared with the compressed information for human vision. In this paper, we thus set out the first successful attempt by a novel collaborative compression method based on the machine-vision-oriented compression, instead of human-vision pipeline. In other words, machine vision serves as the basis for human vision within collaborative compression. A plug-and-play variable bit-rate strategy is also developed for machine vision tasks. Then, we propose to progressively aggregate the semantics from the machine-vision compression, whilst seamlessly tailing the diffusion prior to restore high-fidelity details for human vision, thus named as diffusion-prior based feature compression for human and machine visions (Diff-FCHM). Experimental results verify the consistently superior performances of our Diff-FCHM, on both machine-vision and human-vision compression with remarkable margins. Our code will be released upon acceptance.
Blind Super-Resolution via Meta-learning and Markov Chain Monte Carlo Simulation
Jun 13, 2024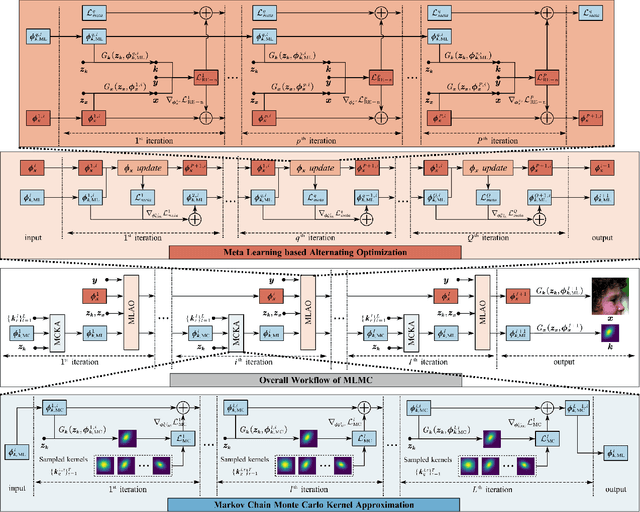
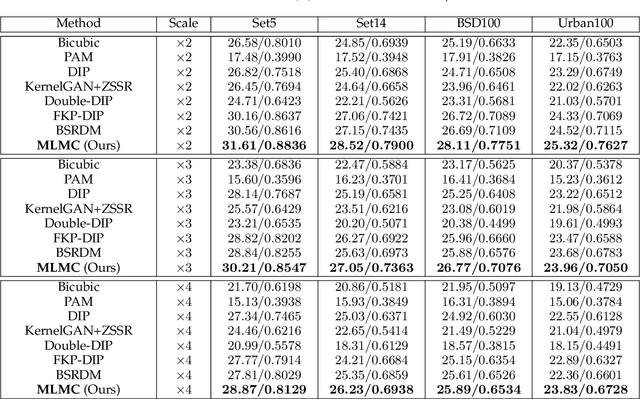
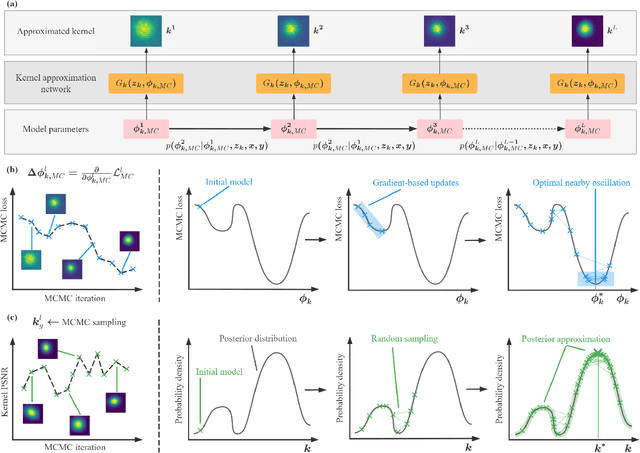
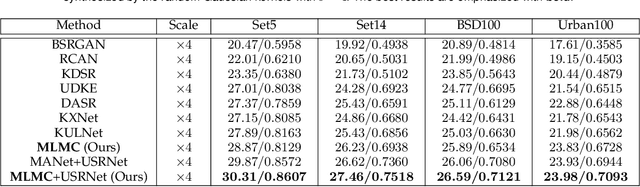
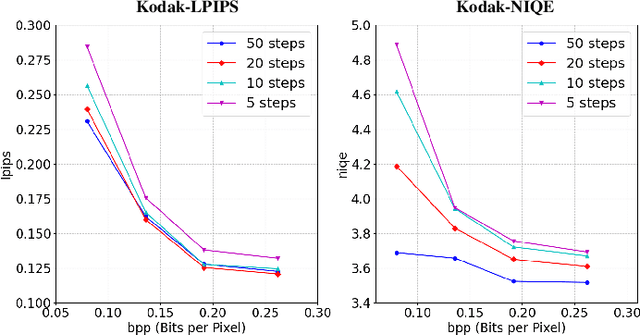
Learning-based approaches have witnessed great successes in blind single image super-resolution (SISR) tasks, however, handcrafted kernel priors and learning based kernel priors are typically required. In this paper, we propose a Meta-learning and Markov Chain Monte Carlo (MCMC) based SISR approach to learn kernel priors from organized randomness. In concrete, a lightweight network is adopted as kernel generator, and is optimized via learning from the MCMC simulation on random Gaussian distributions. This procedure provides an approximation for the rational blur kernel, and introduces a network-level Langevin dynamics into SISR optimization processes, which contributes to preventing bad local optimal solutions for kernel estimation. Meanwhile, a meta-learning-based alternating optimization procedure is proposed to optimize the kernel generator and image restorer, respectively. In contrast to the conventional alternating minimization strategy, a meta-learning-based framework is applied to learn an adaptive optimization strategy, which is less-greedy and results in better convergence performance. These two procedures are iteratively processed in a plug-and-play fashion, for the first time, realizing a learning-based but plug-and-play blind SISR solution in unsupervised inference. Extensive simulations demonstrate the superior performance and generalization ability of the proposed approach when comparing with state-of-the-arts on synthesis and real-world datasets. The code is available at https://github.com/XYLGroup/MLMC.
A Dynamic Kernel Prior Model for Unsupervised Blind Image Super-Resolution
Apr 26, 2024



Deep learning-based methods have achieved significant successes on solving the blind super-resolution (BSR) problem. However, most of them request supervised pre-training on labelled datasets. This paper proposes an unsupervised kernel estimation model, named dynamic kernel prior (DKP), to realize an unsupervised and pre-training-free learning-based algorithm for solving the BSR problem. DKP can adaptively learn dynamic kernel priors to realize real-time kernel estimation, and thereby enables superior HR image restoration performances. This is achieved by a Markov chain Monte Carlo sampling process on random kernel distributions. The learned kernel prior is then assigned to optimize a blur kernel estimation network, which entails a network-based Langevin dynamic optimization strategy. These two techniques ensure the accuracy of the kernel estimation. DKP can be easily used to replace the kernel estimation models in the existing methods, such as Double-DIP and FKP-DIP, or be added to the off-the-shelf image restoration model, such as diffusion model. In this paper, we incorporate our DKP model with DIP and diffusion model, referring to DIP-DKP and Diff-DKP, for validations. Extensive simulations on Gaussian and motion kernel scenarios demonstrate that the proposed DKP model can significantly improve the kernel estimation with comparable runtime and memory usage, leading to state-of-the-art BSR results. The code is available at https://github.com/XYLGroup/DKP.
Towards Assessing the Synthetic-to-Measured Adversarial Vulnerability of SAR ATR
Jan 30, 2024Recently, there has been increasing concern about the vulnerability of deep neural network (DNN)-based synthetic aperture radar (SAR) automatic target recognition (ATR) to adversarial attacks, where a DNN could be easily deceived by clean input with imperceptible but aggressive perturbations. This paper studies the synthetic-to-measured (S2M) transfer setting, where an attacker generates adversarial perturbation based solely on synthetic data and transfers it against victim models trained with measured data. Compared with the current measured-to-measured (M2M) transfer setting, our approach does not need direct access to the victim model or the measured SAR data. We also propose the transferability estimation attack (TEA) to uncover the adversarial risks in this more challenging and practical scenario. The TEA makes full use of the limited similarity between the synthetic and measured data pairs for blind estimation and optimization of S2M transferability, leading to feasible surrogate model enhancement without mastering the victim model and data. Comprehensive evaluations based on the publicly available synthetic and measured paired labeled experiment (SAMPLE) dataset demonstrate that the TEA outperforms state-of-the-art methods and can significantly enhance various attack algorithms in computer vision and remote sensing applications. Codes and data are available at https://github.com/scenarri/S2M-TEA.
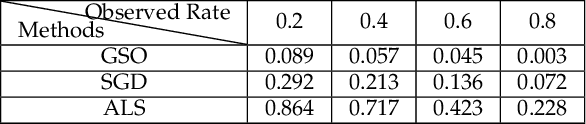
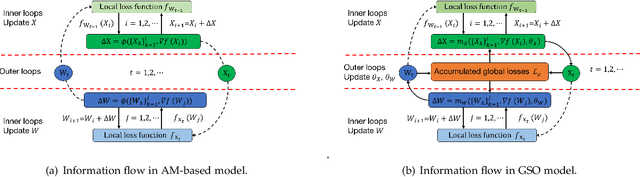
Meta-learning for Multi-variable Non-convex Optimization Problems: Iterating Non-optimums Makes Optimum Possible
Sep 09, 2020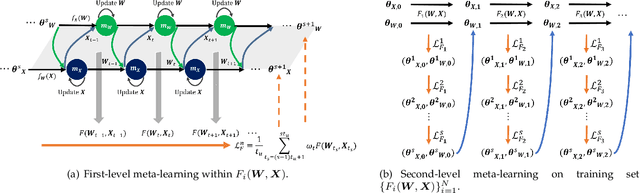

In this paper, we aim to address the problem of solving a non-convex optimization problem over an intersection of multiple variable sets. This kind of problems is typically solved by using an alternating minimization (AM) strategy which splits the overall problem into a set of sub-problems corresponding to each variable, and then iteratively performs minimization over each sub-problem using a fixed updating rule. However, due to the intrinsic non-convexity of the overall problem, the optimization can usually be trapped into bad local minimum even when each sub-problem can be globally optimized at each iteration. To tackle this problem, we propose a meta-learning based Global Scope Optimization (GSO) method. It adaptively generates optimizers for sub-problems via meta-learners and constantly updates these meta-learners with respect to the global loss information of the overall problem. Therefore, the sub-problems are optimized with the objective of minimizing the global loss specifically. We evaluate the proposed model on a number of simulations, including solving bi-linear inverse problems: matrix completion, and non-linear problems: Gaussian mixture models. The experimental results show that our proposed approach outperforms AM-based methods in standard settings, and is able to achieve effective optimization in some challenging cases while other methods would typically fail.