 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Kernel Power K-means: Scalable and Robust Clustering with Random Fourier Features and Possibilistic Method
Nov 13, 2025Kernel power $k$-means (KPKM) leverages a family of means to mitigate local minima issues in kernel $k$-means. However, KPKM faces two key limitations: (1) the computational burden of the full kernel matrix restricts its use on extensive data, and (2) the lack of authentic centroid-sample assignment learning reduces its noise robustness. To overcome these challenges, we propose RFF-KPKM, introducing the first approximation theory for applying random Fourier features (RFF) to KPKM. RFF-KPKM employs RFF to generate efficient, low-dimensional feature maps, bypassing the need for the whole kernel matrix. Crucially, we are the first to establish strong theoretical guarantees for this combination: (1) an excess risk bound of $\mathcal{O}(\sqrt{k^3/n})$, (2) strong consistency with membership values, and (3) a $(1+\varepsilon)$ relative error bound achievable using the RFF of dimension $\mathrm{poly}(\varepsilon^{-1}\log k)$. Furthermore, to improve robustness and the ability to learn multiple kernels, we propose IP-RFF-MKPKM, an improved possibilistic RFF-based multiple kernel power $k$-means. IP-RFF-MKPKM ensures the scalability of MKPKM via RFF and refines cluster assignments by combining the merits of the possibilistic membership and fuzzy membership. Experiments on large-scale datasets demonstrate the superior efficiency and clustering accuracy of the proposed methods compared to the state-of-the-art alternatives.
SMILENet: Unleashing Extra-Large Capacity Image Steganography via a Synergistic Mosaic InvertibLE Hiding Network
Mar 07, 2025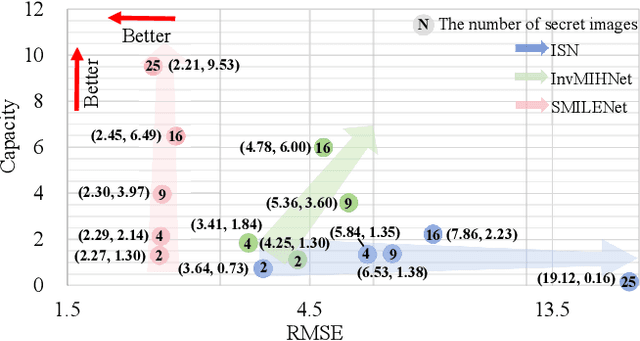
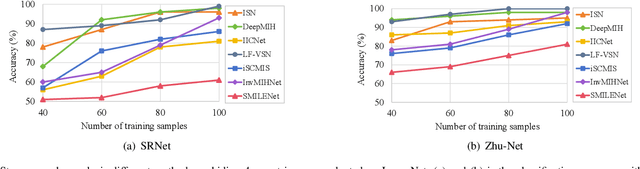

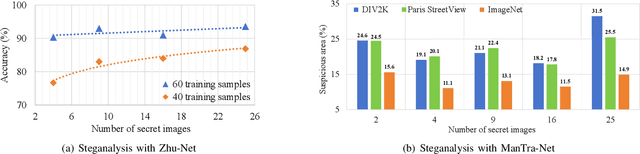
Existing image steganography methods face fundamental limitations in hiding capacity (typically $1\sim7$ images) due to severe information interference and uncoordinated capacity-distortion trade-off. We propose SMILENet, a novel synergistic framework that achieves 25 image hiding through three key innovations: (i) A synergistic network architecture coordinates reversible and non-reversible operations to efficiently exploit information redundancy in both secret and cover images. The reversible Invertible Cover-Driven Mosaic (ICDM) module and Invertible Mosaic Secret Embedding (IMSE) module establish cover-guided mosaic transformations and representation embedding with mathematically guaranteed invertibility for distortion-free embedding. The non-reversible Secret Information Selection (SIS) module and Secret Detail Enhancement (SDE) module implement learnable feature modulation for critical information selection and enhancement. (ii) A unified training strategy that coordinates complementary modules to achieve 3.0x higher capacity than existing methods with superior visual quality. (iii) Last but not least, we introduce a new metric to model Capacity-Distortion Trade-off for evaluating the image steganography algorithms that jointly considers hiding capacity and distortion, and provides a unified evaluation approach for accessing results with different number of secret image. Extensive experiments on DIV2K, Paris StreetView and ImageNet1K show that SMILENet outperforms state-of-the-art methods in terms of hiding capacity, recovery quality as well as security against steganalysis methods.
A Lightweight Deep Exclusion Unfolding Network for Single Image Reflection Removal
Mar 03, 2025Single Image Reflection Removal (SIRR) is a canonical blind source separation problem and refers to the issue of separating a reflection-contaminated image into a transmission and a reflection image. The core challenge lies in minimizing the commonalities among different sources. Existing deep learning approaches either neglect the significance of feature interactions or rely on heuristically designed architectures. In this paper, we propose a novel Deep Exclusion unfolding Network (DExNet), a lightweight, interpretable, and effective network architecture for SIRR. DExNet is principally constructed by unfolding and parameterizing a simple iterative Sparse and Auxiliary Feature Update (i-SAFU) algorithm, which is specifically designed to solve a new model-based SIRR optimization formulation incorporating a general exclusion prior. This general exclusion prior enables the unfolded SAFU module to inherently identify and penalize commonalities between the transmission and reflection features, ensuring more accurate separation. The principled design of DExNet not only enhances its interpretability but also significantly improves its performance. Comprehensive experiments on four benchmark datasets demonstrate that DExNet achieves state-of-the-art visual and quantitative results while utilizing only approximately 8\% of the parameters required by leading methods.
SVASTIN: Sparse Video Adversarial Attack via Spatio-Temporal Invertible Neural Networks
Jun 04, 2024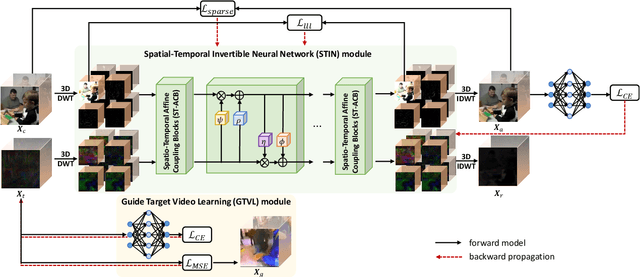

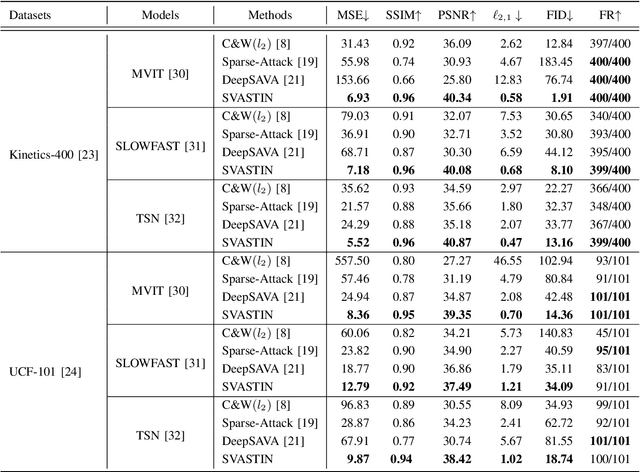
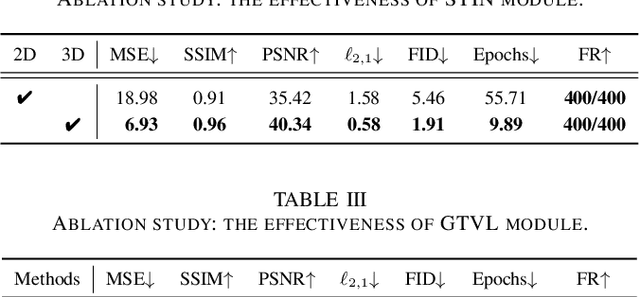
Robust and imperceptible adversarial video attack is challenging due to the spatial and temporal characteristics of videos. The existing video adversarial attack methods mainly take a gradient-based approach and generate adversarial videos with noticeable perturbations. In this paper, we propose a novel Sparse Adversarial Video Attack via Spatio-Temporal Invertible Neural Networks (SVASTIN) to generate adversarial videos through spatio-temporal feature space information exchanging. It consists of a Guided Target Video Learning (GTVL) module to balance the perturbation budget and optimization speed and a Spatio-Temporal Invertible Neural Network (STIN) module to perform spatio-temporal feature space information exchanging between a source video and the target feature tensor learned by GTVL module. Extensive experiments on UCF-101 and Kinetics-400 demonstrate that our proposed SVASTIN can generate adversarial examples with higher imperceptibility than the state-of-the-art methods with the higher fooling rate. Code is available at \href{https://github.com/Brittany-Chen/SVASTIN}{https://github.com/Brittany-Chen/SVASTIN}.
Learning-based Reconstruction of FRI Signals
Dec 16, 2022Finite Rate of Innovation (FRI) sampling theory enables reconstruction of classes of continuous non-bandlimited signals that have a small number of free parameters from their low-rate discrete samples. This task is often translated into a spectral estimation problem that is solved using methods involving estimating signal subspaces, which tend to break down at a certain peak signal-to-noise ratio (PSNR). To avoid this breakdown, we consider alternative approaches that make use of information from labelled data. We propose two model-based learning methods, including deep unfolding the denoising process in spectral estimation, and constructing an encoder-decoder deep neural network that models the acquisition process. Simulation results of both learning algorithms indicate significant improvements of the breakdown PSNR over classical subspace-based methods. While the deep unfolded network achieves similar performance as the classical FRI techniques and outperforms the encoder-decoder network in the low noise regimes, the latter allows to reconstruct the FRI signal even when the sampling kernel is unknown. We also achieve competitive results in detecting pulses from in vivo calcium imaging data in terms of true positive and false positive rate while providing more precise estimations.
A Fast Automatic Method for Deconvoluting Macro X-ray Fluorescence Data Collected from Easel Paintings
Oct 31, 2022Macro X-ray Fluorescence (MA-XRF) scanning is increasingly widely used by researchers in heritage science to analyse easel paintings as one of a suite of non-invasive imaging techniques. The task of processing the resulting MA-XRF datacube generated in order to produce individual chemical element maps is called MA-XRF deconvolution. While there are several existing methods that have been proposed for MA-XRF deconvolution, they require a degree of manual intervention from the user that can affect the final results. The state-of-the-art AFRID approach can automatically deconvolute the datacube without user input, but it has a long processing time and does not exploit spatial dependency. In this paper, we propose two versions of a fast automatic deconvolution (FAD) method for MA-XRF datacubes collected from easel paintings with ADMM (alternating direction method of multipliers) and FISTA (fast iterative shrinkage-thresholding algorithm). The proposed FAD method not only automatically analyses the datacube and produces element distribution maps of high-quality with spatial dependency considered, but also significantly reduces the running time. The results generated on the MA-XRF datacubes collected from two easel paintings from the National Gallery, London, verify the performance of the proposed FAD method.
DURRNet: Deep Unfolded Single Image Reflection Removal Network
Mar 12, 2022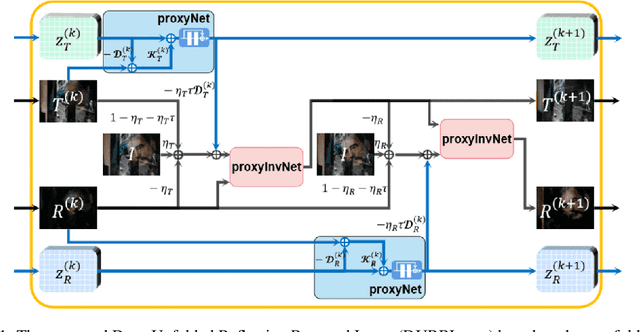

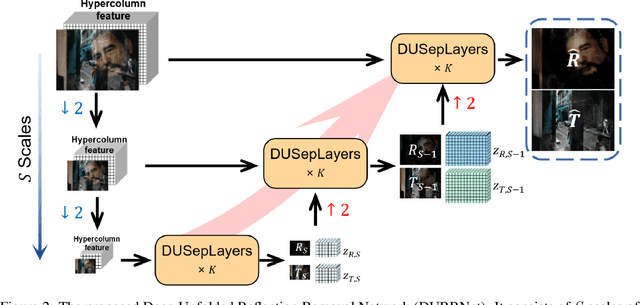

Single image reflection removal problem aims to divide a reflection-contaminated image into a transmission image and a reflection image. It is a canonical blind source separation problem and is highly ill-posed. In this paper, we present a novel deep architecture called deep unfolded single image reflection removal network (DURRNet) which makes an attempt to combine the best features from model-based and learning-based paradigms and therefore leads to a more interpretable deep architecture. Specifically, we first propose a model-based optimization with transform-based exclusion prior and then design an iterative algorithm with simple closed-form solutions for solving each sub-problems. With the deep unrolling technique, we build the DURRNet with ProxNets to model natural image priors and ProxInvNets which are constructed with invertible networks to impose the exclusion prior. Comprehensive experimental results on commonly used datasets demonstrate that the proposed DURRNet achieves state-of-the-art results both visually and quantitatively.
Mixed X-Ray Image Separation for Artworks with Concealed Designs
Jan 23, 2022
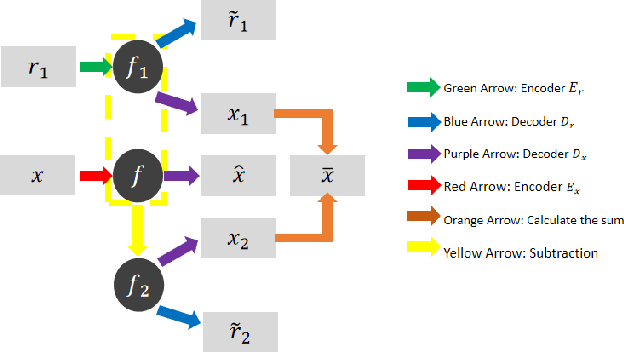
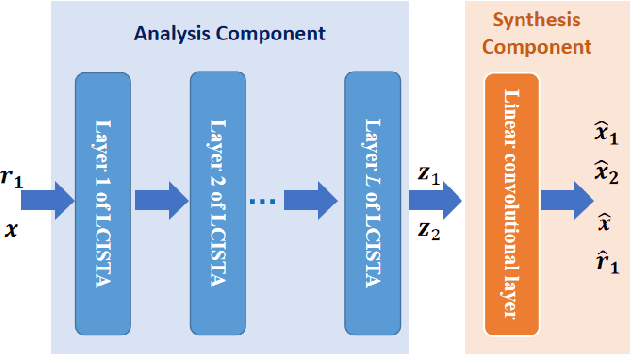
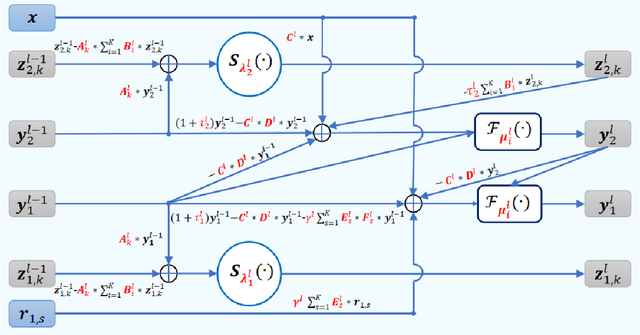
In this paper, we focus on X-ray images of paintings with concealed sub-surface designs (e.g., deriving from reuse of the painting support or revision of a composition by the artist), which include contributions from both the surface painting and the concealed features. In particular, we propose a self-supervised deep learning-based image separation approach that can be applied to the X-ray images from such paintings to separate them into two hypothetical X-ray images. One of these reconstructed images is related to the X-ray image of the concealed painting, while the second one contains only information related to the X-ray of the visible painting. The proposed separation network consists of two components: the analysis and the synthesis sub-networks. The analysis sub-network is based on learned coupled iterative shrinkage thresholding algorithms (LCISTA) designed using algorithm unrolling techniques, and the synthesis sub-network consists of several linear mappings. The learning algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The proposed method is demonstrated on a real painting with concealed content, Do\~na Isabel de Porcel by Francisco de Goya, to show its effectiveness.
WINNet: Wavelet-inspired Invertible Network for Image Denoising
Sep 14, 2021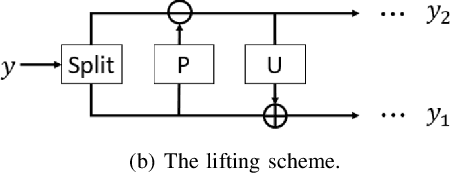
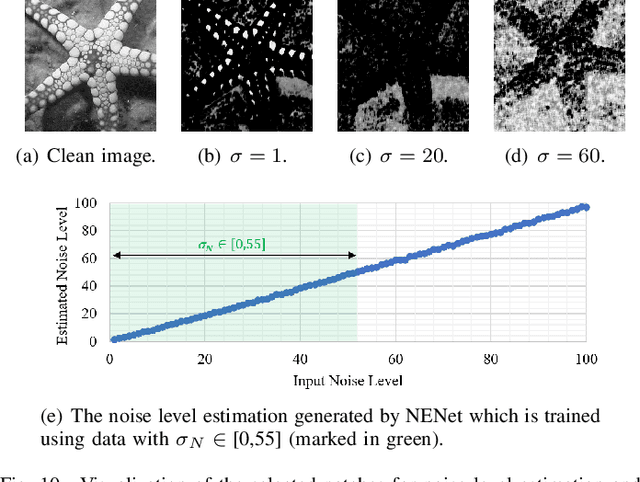
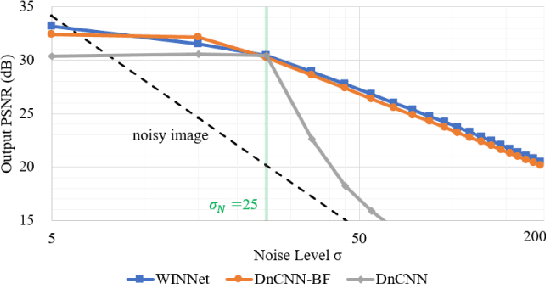

Image denoising aims to restore a clean image from an observed noisy image. The model-based image denoising approaches can achieve good generalization ability over different noise levels and are with high interpretability. Learning-based approaches are able to achieve better results, but usually with weaker generalization ability and interpretability. In this paper, we propose a wavelet-inspired invertible network (WINNet) to combine the merits of the wavelet-based approaches and learningbased approaches. The proposed WINNet consists of K-scale of lifting inspired invertible neural networks (LINNs) and sparsity-driven denoising networks together with a noise estimation network. The network architecture of LINNs is inspired by the lifting scheme in wavelets. LINNs are used to learn a non-linear redundant transform with perfect reconstruction property to facilitate noise removal. The denoising network implements a sparse coding process for denoising. The noise estimation network estimates the noise level from the input image which will be used to adaptively adjust the soft-thresholds in LINNs. The forward transform of LINNs produce a redundant multi-scale representation for denoising. The denoised image is reconstructed using the inverse transform of LINNs with the denoised detail channels and the original coarse channel. The simulation results show that the proposed WINNet method is highly interpretable and has strong generalization ability to unseen noise levels. It also achieves competitive results in the non-blind/blind image denoising and in image deblurring.
Video Summarization through Reinforcement Learning with a 3D Spatio-Temporal U-Net
Jun 19, 2021
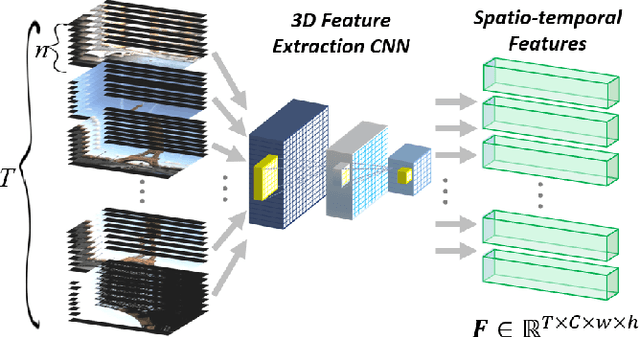
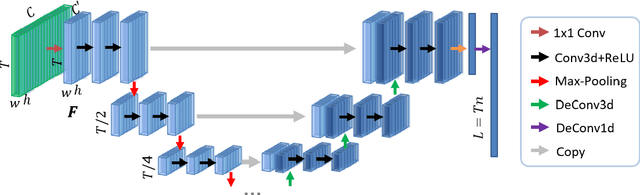
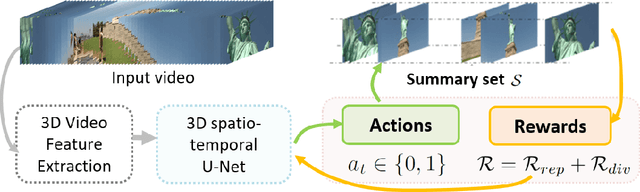
Intelligent video summarization algorithms allow to quickly convey the most relevant information in videos through the identification of the most essential and explanatory content while removing redundant video frames. In this paper, we introduce the 3DST-UNet-RL framework for video summarization. A 3D spatio-temporal U-Net is used to efficiently encode spatio-temporal information of the input videos for downstream reinforcement learning (RL). An RL agent learns from spatio-temporal latent scores and predicts actions for keeping or rejecting a video frame in a video summary. We investigate if real/inflated 3D spatio-temporal CNN features are better suited to learn representations from videos than commonly used 2D image features. Our framework can operate in both, a fully unsupervised mode and a supervised training mode. We analyse the impact of prescribed summary lengths and show experimental evidence for the effectiveness of 3DST-UNet-RL on two commonly used general video summarization benchmarks. We also applied our method on a medical video summarization task. The proposed video summarization method has the potential to save storage costs of ultrasound screening videos as well as to increase efficiency when browsing patient video data during retrospective analysis or audit without loosing essential information