 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMAC: Reference-Based Martian Asymmetrical Image Compression
Jan 26, 2026To expedite space exploration on Mars, it is indispensable to develop an efficient Martian image compression method for transmitting images through the constrained Mars-to-Earth communication channel. Although the existing learned compression methods have achieved promising results for natural images from earth, there remain two critical issues that hinder their effectiveness for Martian image compression: 1) They overlook the highly-limited computational resources on Mars; 2) They do not utilize the strong \textit{inter-image} similarities across Martian images to advance image compression performance. Motivated by our empirical analysis of the strong \textit{intra-} and \textit{inter-image} similarities from the perspective of texture, color, and semantics, we propose a reference-based Martian asymmetrical image compression (REMAC) approach, which shifts computational complexity from the encoder to the resource-rich decoder and simultaneously improves compression performance. To leverage \textit{inter-image} similarities, we propose a reference-guided entropy module and a ref-decoder that utilize useful information from reference images, reducing redundant operations at the encoder and achieving superior compression performance. To exploit \textit{intra-image} similarities, the ref-decoder adopts a deep, multi-scale architecture with enlarged receptive field size to model long-range spatial dependencies. Additionally, we develop a latent feature recycling mechanism to further alleviate the extreme computational constraints on Mars. Experimental results show that REMAC reduces encoder complexity by 43.51\% compared to the state-of-the-art method, while achieving a BD-PSNR gain of 0.2664 dB.
* Accepted for publication in IEEE Transactions on Geoscience and Remote Sensing (TGRS). 2025 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. 18 pages, 20 figures
Burst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025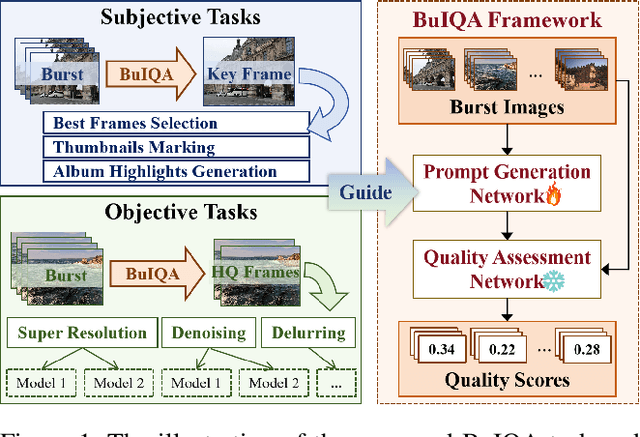
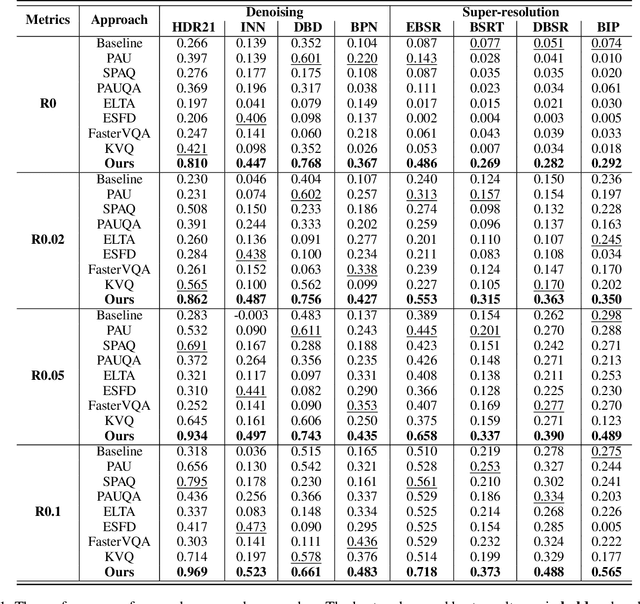

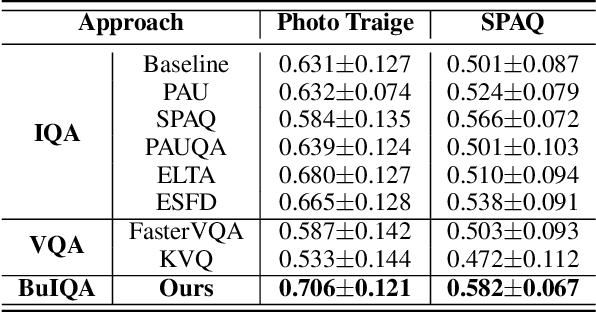
In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
Training-Free ANN-to-SNN Conversion for High-Performance Spiking Transformer
Aug 11, 2025Leveraging the event-driven paradigm, Spiking Neural Networks (SNNs) offer a promising approach for constructing energy-efficient Transformer architectures. Compared to directly trained Spiking Transformers, ANN-to-SNN conversion methods bypass the high training costs. However, existing methods still suffer from notable limitations, failing to effectively handle nonlinear operations in Transformer architectures and requiring additional fine-tuning processes for pre-trained ANNs. To address these issues, we propose a high-performance and training-free ANN-to-SNN conversion framework tailored for Transformer architectures. Specifically, we introduce a Multi-basis Exponential Decay (MBE) neuron, which employs an exponential decay strategy and multi-basis encoding method to efficiently approximate various nonlinear operations. It removes the requirement for weight modifications in pre-trained ANNs. Extensive experiments across diverse tasks (CV, NLU, NLG) and mainstream Transformer architectures (ViT, RoBERTa, GPT-2) demonstrate that our method achieves near-lossless conversion accuracy with significantly lower latency. This provides a promising pathway for the efficient and scalable deployment of Spiking Transformers in real-world applications.
Scene-Adaptive Motion Planning with Explicit Mixture of Experts and Interaction-Oriented Optimization
May 18, 2025



Despite over a decade of development, autonomous driving trajectory planning in complex urban environments continues to encounter significant challenges. These challenges include the difficulty in accommodating the multi-modal nature of trajectories, the limitations of single expert in managing diverse scenarios, and insufficient consideration of environmental interactions. To address these issues, this paper introduces the EMoE-Planner, which incorporates three innovative approaches. Firstly, the Explicit MoE (Mixture of Experts) dynamically selects specialized experts based on scenario-specific information through a shared scene router. Secondly, the planner utilizes scene-specific queries to provide multi-modal priors, directing the model's focus towards relevant target areas. Lastly, it enhances the prediction model and loss calculation by considering the interactions between the ego vehicle and other agents, thereby significantly boosting planning performance. Comparative experiments were conducted using the Nuplan dataset against the state-of-the-art methods. The simulation results demonstrate that our model consistently outperforms SOTA models across nearly all test scenarios.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
SMILENet: Unleashing Extra-Large Capacity Image Steganography via a Synergistic Mosaic InvertibLE Hiding Network
Mar 07, 2025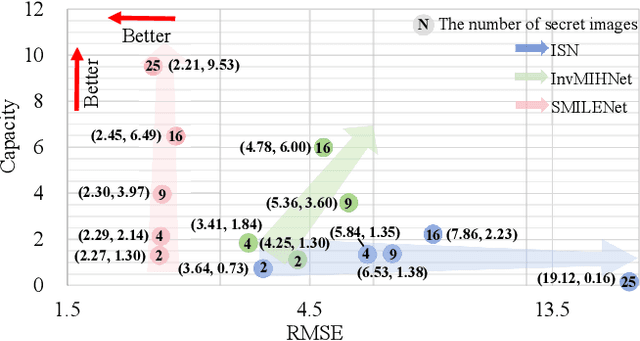
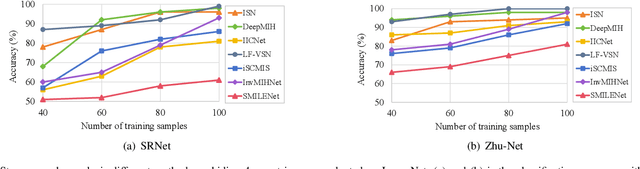

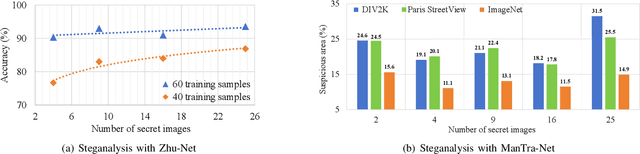
Existing image steganography methods face fundamental limitations in hiding capacity (typically $1\sim7$ images) due to severe information interference and uncoordinated capacity-distortion trade-off. We propose SMILENet, a novel synergistic framework that achieves 25 image hiding through three key innovations: (i) A synergistic network architecture coordinates reversible and non-reversible operations to efficiently exploit information redundancy in both secret and cover images. The reversible Invertible Cover-Driven Mosaic (ICDM) module and Invertible Mosaic Secret Embedding (IMSE) module establish cover-guided mosaic transformations and representation embedding with mathematically guaranteed invertibility for distortion-free embedding. The non-reversible Secret Information Selection (SIS) module and Secret Detail Enhancement (SDE) module implement learnable feature modulation for critical information selection and enhancement. (ii) A unified training strategy that coordinates complementary modules to achieve 3.0x higher capacity than existing methods with superior visual quality. (iii) Last but not least, we introduce a new metric to model Capacity-Distortion Trade-off for evaluating the image steganography algorithms that jointly considers hiding capacity and distortion, and provides a unified evaluation approach for accessing results with different number of secret image. Extensive experiments on DIV2K, Paris StreetView and ImageNet1K show that SMILENet outperforms state-of-the-art methods in terms of hiding capacity, recovery quality as well as security against steganalysis methods.
Causal Context Adjustment Loss for Learned Image Compression
Oct 07, 2024



In recent years, learned image compression (LIC) technologies have surpassed conventional methods notably in terms of rate-distortion (RD) performance. Most present learned techniques are VAE-based with an autoregressive entropy model, which obviously promotes the RD performance by utilizing the decoded causal context. However, extant methods are highly dependent on the fixed hand-crafted causal context. The question of how to guide the auto-encoder to generate a more effective causal context benefit for the autoregressive entropy models is worth exploring. In this paper, we make the first attempt in investigating the way to explicitly adjust the causal context with our proposed Causal Context Adjustment loss (CCA-loss). By imposing the CCA-loss, we enable the neural network to spontaneously adjust important information into the early stage of the autoregressive entropy model. Furthermore, as transformer technology develops remarkably, variants of which have been adopted by many state-of-the-art (SOTA) LIC techniques. The existing computing devices have not adapted the calculation of the attention mechanism well, which leads to a burden on computation quantity and inference latency. To overcome it, we establish a convolutional neural network (CNN) image compression model and adopt the unevenly channel-wise grouped strategy for high efficiency. Ultimately, the proposed CNN-based LIC network trained with our Causal Context Adjustment loss attains a great trade-off between inference latency and rate-distortion performance.
HiGraphDTI: Hierarchical Graph Representation Learning for Drug-Target Interaction Prediction
Apr 16, 2024The discovery of drug-target interactions (DTIs) plays a crucial role in pharmaceutical development. The deep learning model achieves more accurate results in DTI prediction due to its ability to extract robust and expressive features from drug and target chemical structures. However, existing deep learning methods typically generate drug features via aggregating molecular atom representations, ignoring the chemical properties carried by motifs, i.e., substructures of the molecular graph. The atom-drug double-level molecular representation learning can not fully exploit structure information and fails to interpret the DTI mechanism from the motif perspective. In addition, sequential model-based target feature extraction either fuses limited contextual information or requires expensive computational resources. To tackle the above issues, we propose a hierarchical graph representation learning-based DTI prediction method (HiGraphDTI). Specifically, HiGraphDTI learns hierarchical drug representations from triple-level molecular graphs to thoroughly exploit chemical information embedded in atoms, motifs, and molecules. Then, an attentional feature fusion module incorporates information from different receptive fields to extract expressive target features.Last, the hierarchical attention mechanism identifies crucial molecular segments, which offers complementary views for interpreting interaction mechanisms. The experiment results not only demonstrate the superiority of HiGraphDTI to the state-of-the-art methods, but also confirm the practical ability of our model in interaction interpretation and new DTI discovery.
Enhancing Quality of Compressed Images by Mitigating Enhancement Bias Towards Compression Domain
Mar 10, 2024Existing quality enhancement methods for compressed images focus on aligning the enhancement domain with the raw domain to yield realistic images. However, these methods exhibit a pervasive enhancement bias towards the compression domain, inadvertently regarding it as more realistic than the raw domain. This bias makes enhanced images closely resemble their compressed counterparts, thus degrading their perceptual quality. In this paper, we propose a simple yet effective method to mitigate this bias and enhance the quality of compressed images. Our method employs a conditional discriminator with the compressed image as a key condition, and then incorporates a domain-divergence regularization to actively distance the enhancement domain from the compression domain. Through this dual strategy, our method enables the discrimination against the compression domain, and brings the enhancement domain closer to the raw domain. Comprehensive quality evaluations confirm the superiority of our method over other state-of-the-art methods without incurring inference overheads.
Pixel Adapter: A Graph-Based Post-Processing Approach for Scene Text Image Super-Resolution
Sep 16, 2023



Current Scene text image super-resolution approaches primarily focus on extracting robust features, acquiring text information, and complex training strategies to generate super-resolution images. However, the upsampling module, which is crucial in the process of converting low-resolution images to high-resolution ones, has received little attention in existing works. To address this issue, we propose the Pixel Adapter Module (PAM) based on graph attention to address pixel distortion caused by upsampling. The PAM effectively captures local structural information by allowing each pixel to interact with its neighbors and update features. Unlike previous graph attention mechanisms, our approach achieves 2-3 orders of magnitude improvement in efficiency and memory utilization by eliminating the dependency on sparse adjacency matrices and introducing a sliding window approach for efficient parallel computation. Additionally, we introduce the MLP-based Sequential Residual Block (MSRB) for robust feature extraction from text images, and a Local Contour Awareness loss ($\mathcal{L}_{lca}$) to enhance the model's perception of details. Comprehensive experiments on TextZoom demonstrate that our proposed method generates high-quality super-resolution images, surpassing existing methods in recognition accuracy. For single-stage and multi-stage strategies, we achieved improvements of 0.7\% and 2.6\%, respectively, increasing the performance from 52.6\% and 53.7\% to 53.3\% and 56.3\%. The code is available at https://github.com/wenyu1009/RTSRN.