 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALI: A Workload-Aware Offloading Framework for Efficient MoE Inference on Local PCs
Feb 03, 2026Mixture of Experts (MoE) architectures significantly enhance the capacity of LLMs without proportional increases in computation, but at the cost of a vast parameter size. Offloading MoE expert parameters to host memory and leveraging both CPU and GPU computation has recently emerged as a promising direction to support such models on resourceconstrained local PC platforms. While promising, we notice that existing approaches mismatch the dynamic nature of expert workloads, which leads to three fundamental inefficiencies: (1) Static expert assignment causes severe CPUGPU load imbalance, underutilizing CPU and GPU resources; (2) Existing prefetching techniques fail to accurately predict high-workload experts, leading to costly inaccurate prefetches; (3) GPU cache policies neglect workload dynamics, resulting in poor hit rates and limited effectiveness. To address these challenges, we propose DALI, a workloaDAware offLoadIng framework for efficient MoE inference on local PCs. To fully utilize hardware resources, DALI first dynamically assigns experts to CPU or GPU by modeling assignment as a 0-1 integer optimization problem and solving it efficiently using a Greedy Assignment strategy at runtime. To improve prefetching accuracy, we develop a Residual-Based Prefetching method leveraging inter-layer residual information to accurately predict high-workload experts. Additionally, we introduce a Workload-Aware Cache Replacement policy that exploits temporal correlation in expert activations to improve GPU cache efficiency. By evaluating across various MoE models and settings, DALI achieves significant speedups in the both prefill and decoding phases over the state-of-the-art offloading frameworks.
Scene-Adaptive Motion Planning with Explicit Mixture of Experts and Interaction-Oriented Optimization
May 18, 2025



Despite over a decade of development, autonomous driving trajectory planning in complex urban environments continues to encounter significant challenges. These challenges include the difficulty in accommodating the multi-modal nature of trajectories, the limitations of single expert in managing diverse scenarios, and insufficient consideration of environmental interactions. To address these issues, this paper introduces the EMoE-Planner, which incorporates three innovative approaches. Firstly, the Explicit MoE (Mixture of Experts) dynamically selects specialized experts based on scenario-specific information through a shared scene router. Secondly, the planner utilizes scene-specific queries to provide multi-modal priors, directing the model's focus towards relevant target areas. Lastly, it enhances the prediction model and loss calculation by considering the interactions between the ego vehicle and other agents, thereby significantly boosting planning performance. Comparative experiments were conducted using the Nuplan dataset against the state-of-the-art methods. The simulation results demonstrate that our model consistently outperforms SOTA models across nearly all test scenarios.
MEGA: A Memory-Efficient GNN Accelerator Exploiting Degree-Aware Mixed-Precision Quantization
Nov 16, 2023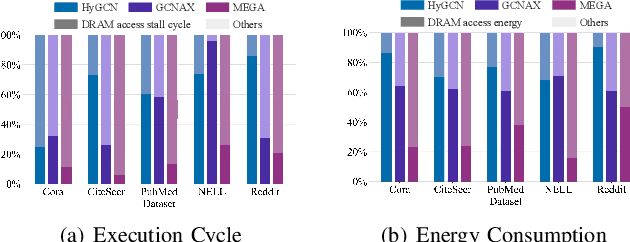
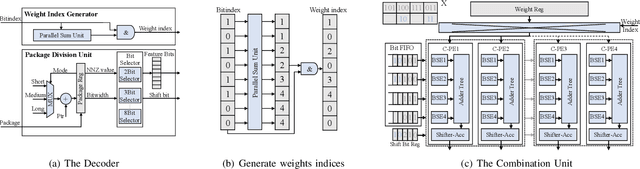
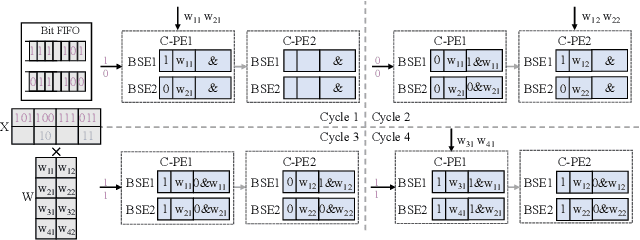

Graph Neural Networks (GNNs) are becoming a promising technique in various domains due to their excellent capabilities in modeling non-Euclidean data. Although a spectrum of accelerators has been proposed to accelerate the inference of GNNs, our analysis demonstrates that the latency and energy consumption induced by DRAM access still significantly impedes the improvement of performance and energy efficiency. To address this issue, we propose a Memory-Efficient GNN Accelerator (MEGA) through algorithm and hardware co-design in this work. Specifically, at the algorithm level, through an in-depth analysis of the node property, we observe that the data-independent quantization in previous works is not optimal in terms of accuracy and memory efficiency. This motivates us to propose the Degree-Aware mixed-precision quantization method, in which a proper bitwidth is learned and allocated to a node according to its in-degree to compress GNNs as much as possible while maintaining accuracy. At the hardware level, we employ a heterogeneous architecture design in which the aggregation and combination phases are implemented separately with different dataflows. In order to boost the performance and energy efficiency, we also present an Adaptive-Package format to alleviate the storage overhead caused by the fine-grained bitwidth and diverse sparsity, and a Condense-Edge scheduling method to enhance the data locality and further alleviate the access irregularity induced by the extremely sparse adjacency matrix in the graph. We implement our MEGA accelerator in a 28nm technology node. Extensive experiments demonstrate that MEGA can achieve an average speedup of 38.3x, 7.1x, 4.0x, 3.6x and 47.6x, 7.2x, 5.4x, 4.5x energy savings over four state-of-the-art GNN accelerators, HyGCN, GCNAX, GROW, and SGCN, respectively, while retaining task accuracy.
$\rm A^2Q$: Aggregation-Aware Quantization for Graph Neural Networks
Feb 01, 2023

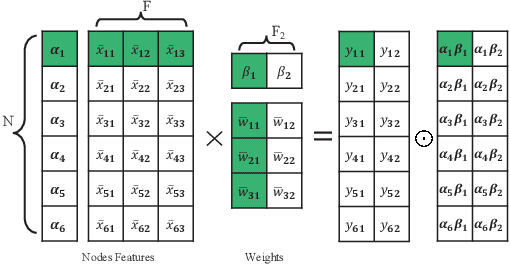
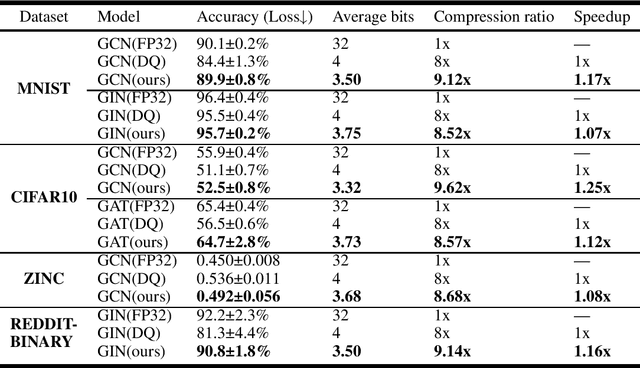
As graph data size increases, the vast latency and memory consumption during inference pose a significant challenge to the real-world deployment of Graph Neural Networks (GNNs). While quantization is a powerful approach to reducing GNNs complexity, most previous works on GNNs quantization fail to exploit the unique characteristics of GNNs, suffering from severe accuracy degradation. Through an in-depth analysis of the topology of GNNs, we observe that the topology of the graph leads to significant differences between nodes, and most of the nodes in a graph appear to have a small aggregation value. Motivated by this, in this paper, we propose the Aggregation-Aware mixed-precision Quantization ($\rm A^2Q$) for GNNs, where an appropriate bitwidth is automatically learned and assigned to each node in the graph. To mitigate the vanishing gradient problem caused by sparse connections between nodes, we propose a Local Gradient method to serve the quantization error of the node features as the supervision during training. We also develop a Nearest Neighbor Strategy to deal with the generalization on unseen graphs. Extensive experiments on eight public node-level and graph-level datasets demonstrate the generality and robustness of our proposed method. Compared to the FP32 models, our method can achieve up to a 18.6x (i.e., 1.70bit) compression ratio with negligible accuracy degradation. Morever, compared to the state-of-the-art quantization method, our method can achieve up to 11.4\% and 9.5\% accuracy improvements on the node-level and graph-level tasks, respectively, and up to 2x speedup on a dedicated hardware accelerator.
BayesFT: Bayesian Optimization for Fault Tolerant Neural Network Architecture
Sep 30, 2022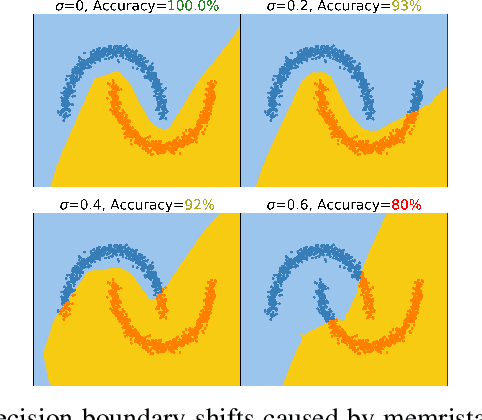
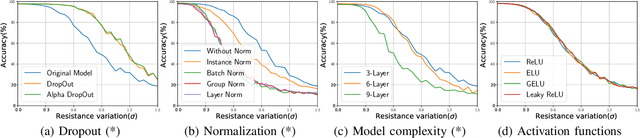
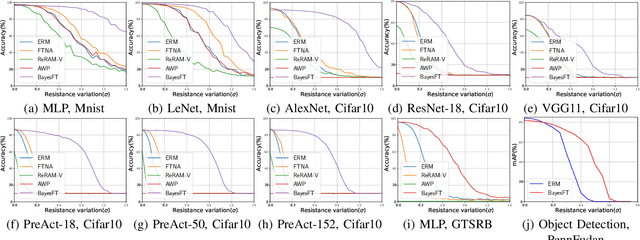

To deploy deep learning algorithms on resource-limited scenarios, an emerging device-resistive random access memory (ReRAM) has been regarded as promising via analog computing. However, the practicability of ReRAM is primarily limited due to the weight drifting of ReRAM neural networks due to multi-factor reasons, including manufacturing, thermal noises, and etc. In this paper, we propose a novel Bayesian optimization method for fault tolerant neural network architecture (BayesFT). For neural architecture search space design, instead of conducting neural architecture search on the whole feasible neural architecture search space, we first systematically explore the weight drifting tolerance of different neural network components, such as dropout, normalization, number of layers, and activation functions in which dropout is found to be able to improve the neural network robustness to weight drifting. Based on our analysis, we propose an efficient search space by only searching for dropout rates for each layer. Then, we use Bayesian optimization to search for the optimal neural architecture robust to weight drifting. Empirical experiments demonstrate that our algorithmic framework has outperformed the state-of-the-art methods by up to 10 times on various tasks, such as image classification and object detection.
DNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Mar 11, 2022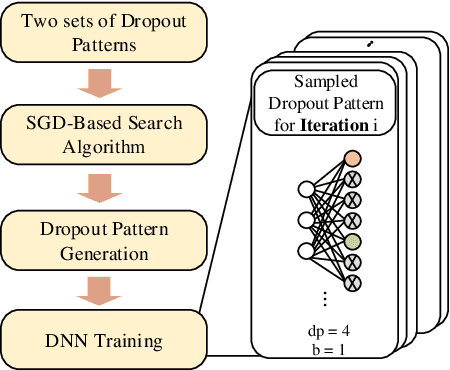
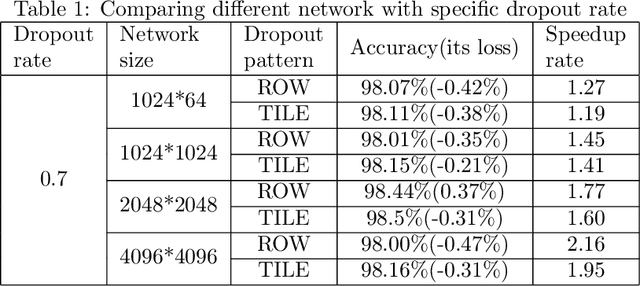
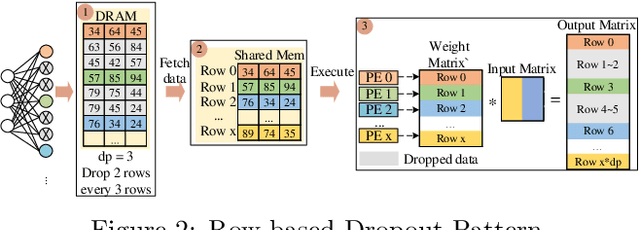
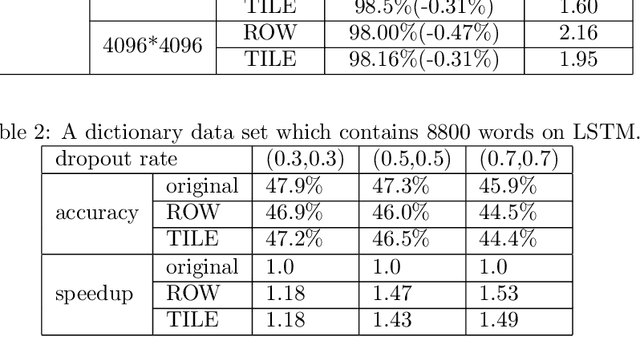
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.
CP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
Mar 09, 2022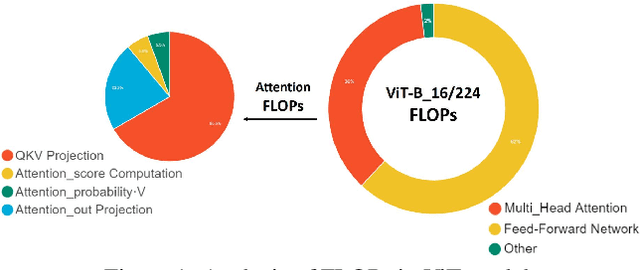
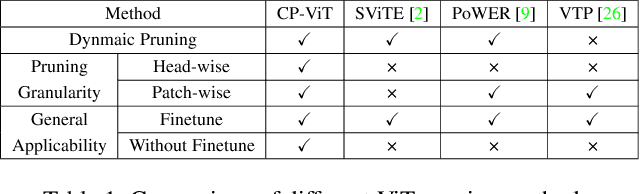
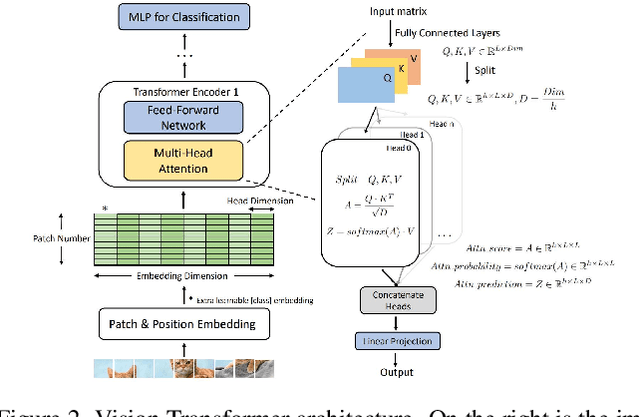
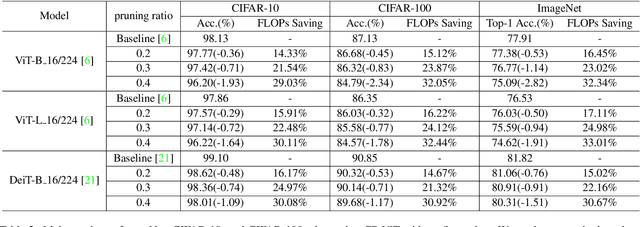
Vision transformer (ViT) has achieved competitive accuracy on a variety of computer vision applications, but its computational cost impedes the deployment on resource-limited mobile devices. We explore the sparsity in ViT and observe that informative patches and heads are sufficient for accurate image recognition. In this paper, we propose a cascade pruning framework named CP-ViT by predicting sparsity in ViT models progressively and dynamically to reduce computational redundancy while minimizing the accuracy loss. Specifically, we define the cumulative score to reserve the informative patches and heads across the ViT model for better accuracy. We also propose the dynamic pruning ratio adjustment technique based on layer-aware attention range. CP-ViT has great general applicability for practical deployment, which can be applied to a wide range of ViT models and can achieve superior accuracy with or without fine-tuning. Extensive experiments on ImageNet, CIFAR-10, and CIFAR-100 with various pre-trained models have demonstrated the effectiveness and efficiency of CP-ViT. By progressively pruning 50\% patches, our CP-ViT method reduces over 40\% FLOPs while maintaining accuracy loss within 1\%.
N3H-Core: Neuron-designed Neural Network Accelerator via FPGA-based Heterogeneous Computing Cores
Dec 15, 2021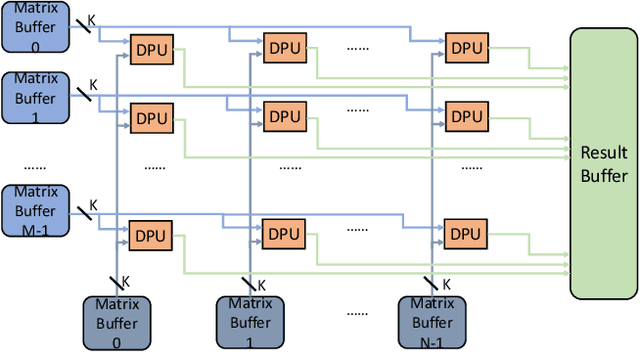
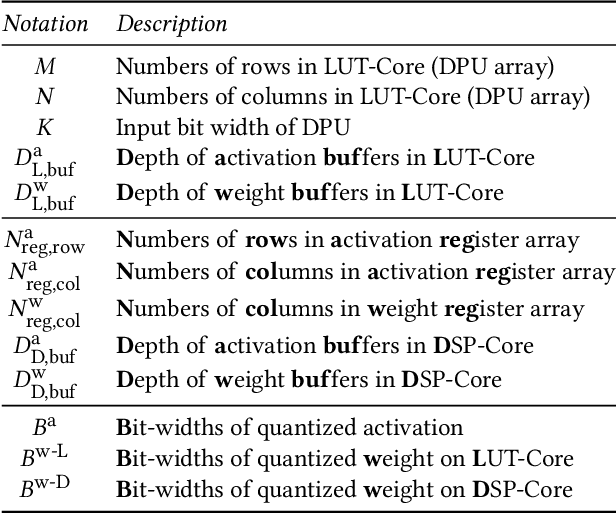
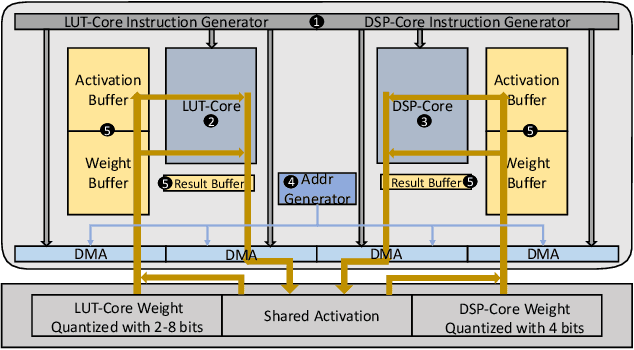
Accelerating the neural network inference by FPGA has emerged as a popular option, since the reconfigurability and high performance computing capability of FPGA intrinsically satisfies the computation demand of the fast-evolving neural algorithms. However, the popular neural accelerators on FPGA (e.g., Xilinx DPU) mainly utilize the DSP resources for constructing their processing units, while the rich LUT resources are not well exploited. Via the software-hardware co-design approach, in this work, we develop an FPGA-based heterogeneous computing system for neural network acceleration. From the hardware perspective, the proposed accelerator consists of DSP- and LUT-based GEneral Matrix-Multiplication (GEMM) computing cores, which forms the entire computing system in a heterogeneous fashion. The DSP- and LUT-based GEMM cores are computed w.r.t a unified Instruction Set Architecture (ISA) and unified buffers. Along the data flow of the neural network inference path, the computation of the convolution/fully-connected layer is split into two portions, handled by the DSP- and LUT-based GEMM cores asynchronously. From the software perspective, we mathematically and systematically model the latency and resource utilization of the proposed heterogeneous accelerator, regarding varying system design configurations. Through leveraging the reinforcement learning technique, we construct a framework to achieve end-to-end selection and optimization of the design specification of target heterogeneous accelerator, including workload split strategy, mixed-precision quantization scheme, and resource allocation of DSP- and LUT-core. In virtue of the proposed design framework and heterogeneous computing system, our design outperforms the state-of-the-art Mix&Match design with latency reduced by 1.12-1.32x with higher inference accuracy. The N3H-core is open-sourced at: https://github.com/elliothe/N3H_Core.
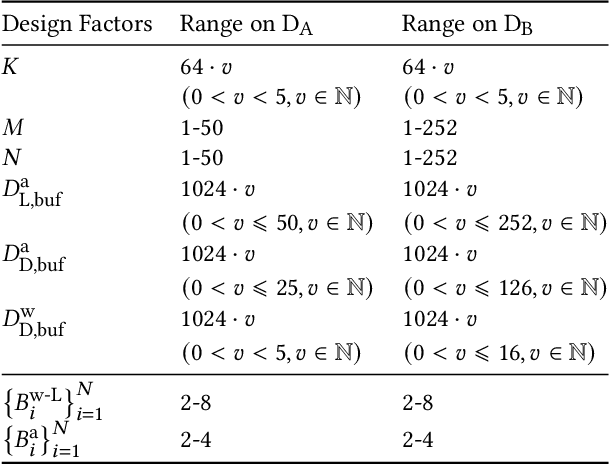
SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021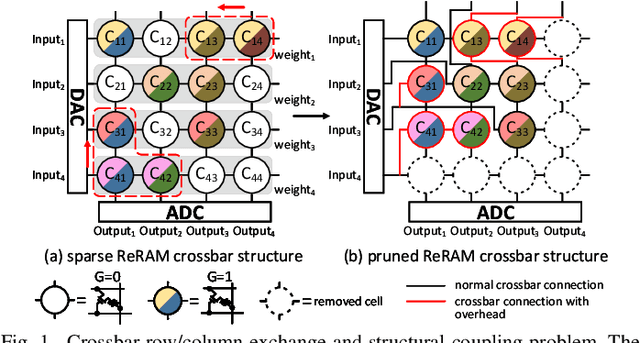
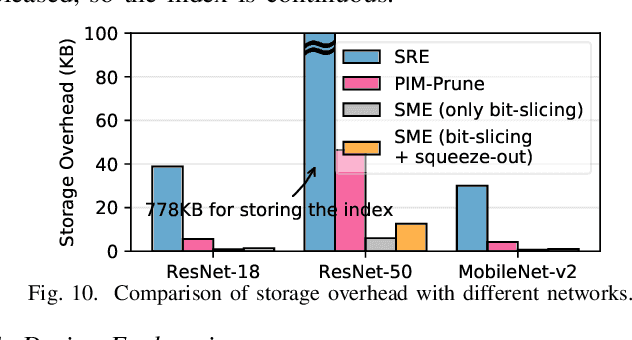
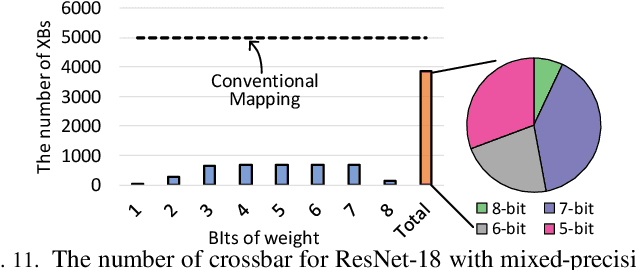
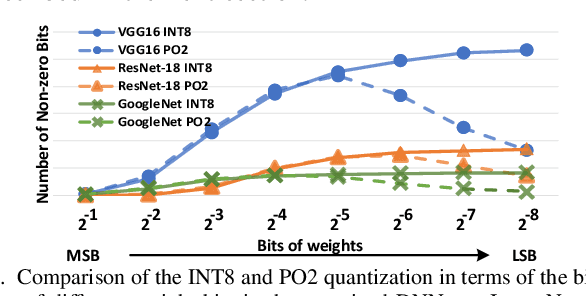
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.
Invocation-driven Neural Approximate Computing with a Multiclass-Classifier and Multiple Approximators
Oct 19, 2018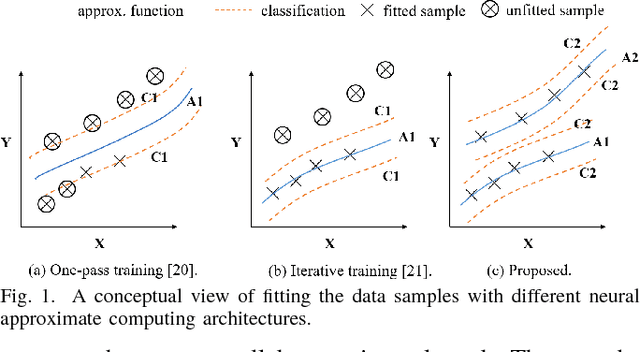
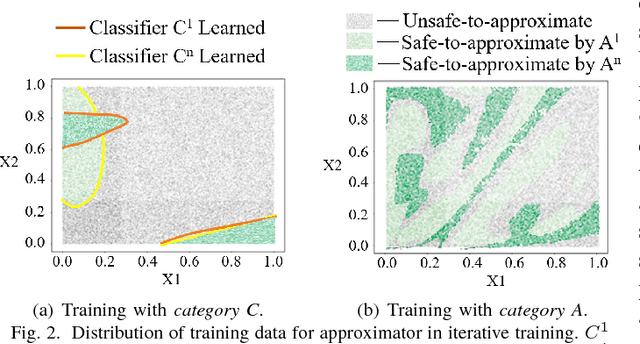
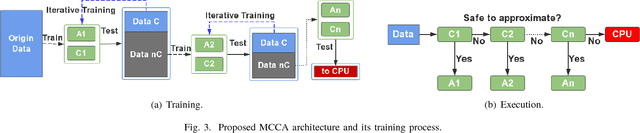
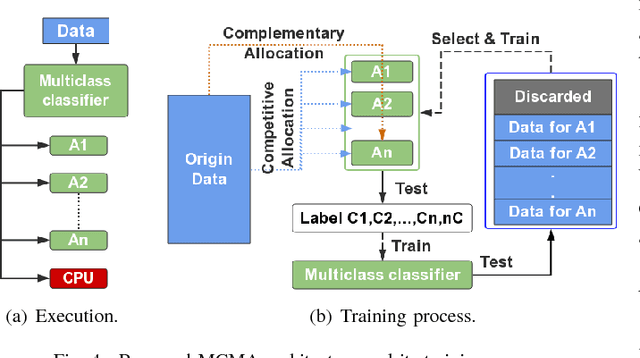
Neural approximate computing gains enormous energy-efficiency at the cost of tolerable quality-loss. A neural approximator can map the input data to output while a classifier determines whether the input data are safe to approximate with quality guarantee. However, existing works cannot maximize the invocation of the approximator, resulting in limited speedup and energy saving. By exploring the mapping space of those target functions, in this paper, we observe a nonuniform distribution of the approximation error incurred by the same approximator. We thus propose a novel approximate computing architecture with a Multiclass-Classifier and Multiple Approximators (MCMA). These approximators have identical network topologies and thus can share the same hardware resource in a neural processing unit(NPU) clip. In the runtime, MCMA can swap in the invoked approximator by merely shipping the synapse weights from the on-chip memory to the buffers near MAC within a cycle. We also propose efficient co-training methods for such MCMA architecture. Experimental results show a more substantial invocation of MCMA as well as the gain of energy-efficiency.