 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving on Registers
Jan 08, 2026We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
Tracking-Aware Deformation Field Estimation for Non-rigid 3D Reconstruction in Robotic Surgeries
Mar 04, 2025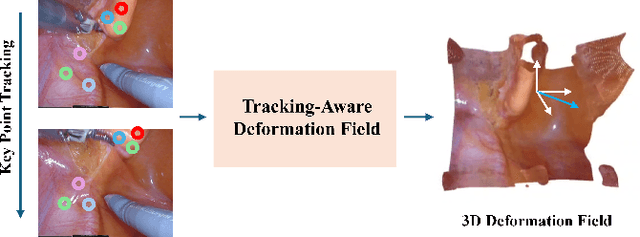



Minimally invasive procedures have been advanced rapidly by the robotic laparoscopic surgery. The latter greatly assists surgeons in sophisticated and precise operations with reduced invasiveness. Nevertheless, it is still safety critical to be aware of even the least tissue deformation during instrument-tissue interactions, especially in 3D space. To address this, recent works rely on NeRF to render 2D videos from different perspectives and eliminate occlusions. However, most of the methods fail to predict the accurate 3D shapes and associated deformation estimates robustly. Differently, we propose Tracking-Aware Deformation Field (TADF), a novel framework which reconstructs the 3D mesh along with the 3D tissue deformation simultaneously. It first tracks the key points of soft tissue by a foundation vision model, providing an accurate 2D deformation field. Then, the 2D deformation field is smoothly incorporated with a neural implicit reconstruction network to obtain tissue deformation in the 3D space. Finally, we experimentally demonstrate that the proposed method provides more accurate deformation estimation compared with other 3D neural reconstruction methods in two public datasets.
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
PPT: Pre-Training with Pseudo-Labeled Trajectories for Motion Forecasting
Dec 09, 2024Motion forecasting (MF) for autonomous driving aims at anticipating trajectories of surrounding agents in complex urban scenarios. In this work, we investigate a mixed strategy in MF training that first pre-train motion forecasters on pseudo-labeled data, then fine-tune them on annotated data. To obtain pseudo-labeled trajectories, we propose a simple pipeline that leverages off-the-shelf single-frame 3D object detectors and non-learning trackers. The whole pre-training strategy including pseudo-labeling is coined as PPT. Our extensive experiments demonstrate that: (1) combining PPT with supervised fine-tuning on annotated data achieves superior performance on diverse testbeds, especially under annotation-efficient regimes, (2) scaling up to multiple datasets improves the previous state-of-the-art and (3) PPT helps enhance cross-dataset generalization. Our findings showcase PPT as a promising pre-training solution for robust motion forecasting in diverse autonomous driving contexts.
Annealed Winner-Takes-All for Motion Forecasting
Sep 18, 2024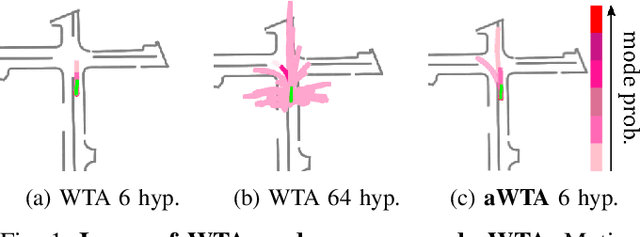
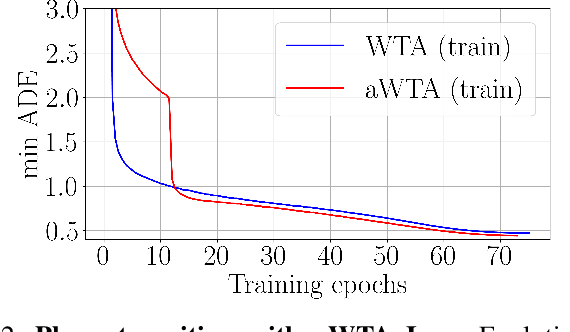
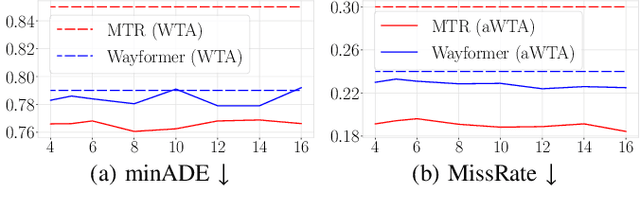
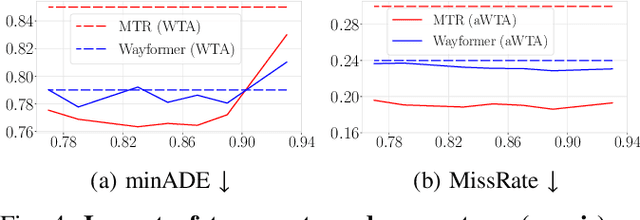
In autonomous driving, motion prediction aims at forecasting the future trajectories of nearby agents, helping the ego vehicle to anticipate behaviors and drive safely. A key challenge is generating a diverse set of future predictions, commonly addressed using data-driven models with Multiple Choice Learning (MCL) architectures and Winner-Takes-All (WTA) training objectives. However, these methods face initialization sensitivity and training instabilities. Additionally, to compensate for limited performance, some approaches rely on training with a large set of hypotheses, requiring a post-selection step during inference to significantly reduce the number of predictions. To tackle these issues, we take inspiration from annealed MCL, a recently introduced technique that improves the convergence properties of MCL methods through an annealed Winner-Takes-All loss (aWTA). In this paper, we demonstrate how the aWTA loss can be integrated with state-of-the-art motion forecasting models to enhance their performance using only a minimal set of hypotheses, eliminating the need for the cumbersome post-selection step. Our approach can be easily incorporated into any trajectory prediction model normally trained using WTA and yields significant improvements. To facilitate the application of our approach to future motion forecasting models, the code will be made publicly available upon acceptance: https://github.com/valeoai/MF_aWTA.
Lost and Found: Overcoming Detector Failures in Online Multi-Object Tracking
Jul 16, 2024Multi-object tracking (MOT) endeavors to precisely estimate the positions and identities of multiple objects over time. The prevailing approach, tracking-by-detection (TbD), first detects objects and then links detections, resulting in a simple yet effective method. However, contemporary detectors may occasionally miss some objects in certain frames, causing trackers to cease tracking prematurely. To tackle this issue, we propose BUSCA, meaning `to search', a versatile framework compatible with any online TbD system, enhancing its ability to persistently track those objects missed by the detector, primarily due to occlusions. Remarkably, this is accomplished without modifying past tracking results or accessing future frames, i.e., in a fully online manner. BUSCA generates proposals based on neighboring tracks, motion, and learned tokens. Utilizing a decision Transformer that integrates multimodal visual and spatiotemporal information, it addresses the object-proposal association as a multi-choice question-answering task. BUSCA is trained independently of the underlying tracker, solely on synthetic data, without requiring fine-tuning. Through BUSCA, we showcase consistent performance enhancements across five different trackers and establish a new state-of-the-art baseline across three different benchmarks. Code available at: https://github.com/lorenzovaquero/BUSCA.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024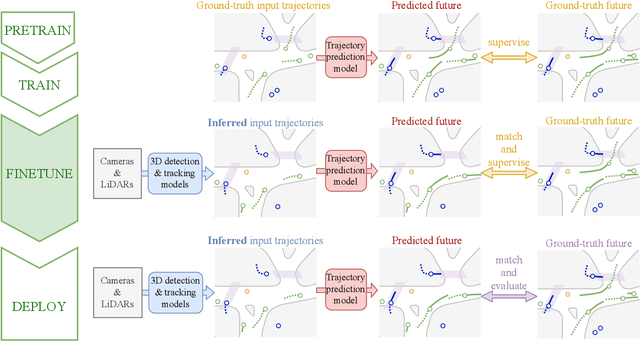
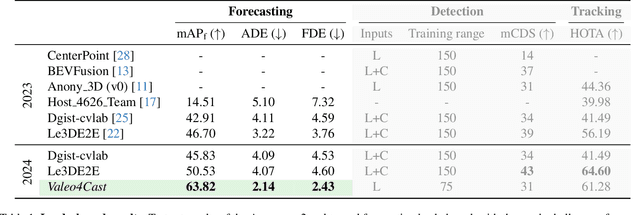
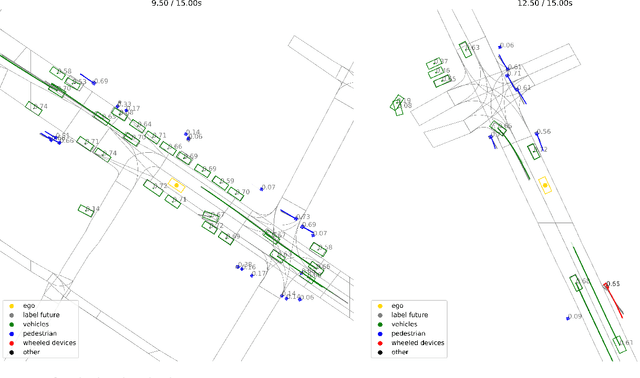
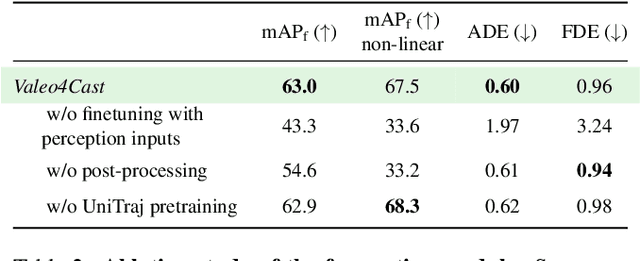
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
Learning Kernel-Modulated Neural Representation for Efficient Light Field Compression
Jul 12, 2023



Light field is a type of image data that captures the 3D scene information by recording light rays emitted from a scene at various orientations. It offers a more immersive perception than classic 2D images but at the cost of huge data volume. In this paper, we draw inspiration from the visual characteristics of Sub-Aperture Images (SAIs) of light field and design a compact neural network representation for the light field compression task. The network backbone takes randomly initialized noise as input and is supervised on the SAIs of the target light field. It is composed of two types of complementary kernels: descriptive kernels (descriptors) that store scene description information learned during training, and modulatory kernels (modulators) that control the rendering of different SAIs from the queried perspectives. To further enhance compactness of the network meanwhile retain high quality of the decoded light field, we accordingly introduce modulator allocation and kernel tensor decomposition mechanisms, followed by non-uniform quantization and lossless entropy coding techniques, to finally form an efficient compression pipeline. Extensive experiments demonstrate that our method outperforms other state-of-the-art (SOTA) methods by a significant margin in the light field compression task. Moreover, after aligning descriptors, the modulators learned from one light field can be transferred to new light fields for rendering dense views, indicating a potential solution for view synthesis task.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Jun 15, 2023Motion forecasting plays a critical role in enabling robots to anticipate future trajectories of surrounding agents and plan accordingly. However, existing forecasting methods often rely on curated datasets that are not faithful to what real-world perception pipelines can provide. In reality, upstream modules that are responsible for detecting and tracking agents, and those that gather road information to build the map, can introduce various errors, including misdetections, tracking errors, and difficulties in being accurate for distant agents and road elements. This paper aims to uncover the challenges of bringing motion forecasting models to this more realistic setting where inputs are provided by perception modules. In particular, we quantify the impacts of the domain gap through extensive evaluation. Furthermore, we design synthetic perturbations to better characterize their consequences, thus providing insights into areas that require improvement in upstream perception modules and guidance toward the development of more robust forecasting methods.
Learning-based Spatial and Angular Information Separation for Light Field Compression
Apr 13, 2023



Light fields are a type of image data that capture both spatial and angular scene information by recording light rays emitted by a scene from different orientations. In this context, spatial information is defined as features that remain static regardless of perspectives, while angular information refers to features that vary between viewpoints. We propose a novel neural network that, by design, can separate angular and spatial information of a light field. The network represents spatial information using spatial kernels shared among all Sub-Aperture Images (SAIs), and angular information using sets of angular kernels for each SAI. To further improve the representation capability of the network without increasing parameter number, we also introduce angular kernel allocation and kernel tensor decomposition mechanisms. Extensive experiments demonstrate the benefits of information separation: when applied to the compression task, our network outperforms other state-of-the-art methods by a large margin. And angular information can be easily transferred to other scenes for rendering dense views, showing the successful separation and the potential use case for the view synthesis task. We plan to release the code upon acceptance of the paper to encourage further research on this topic.