 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeclareAligner: A Leap Towards Efficient Optimal Alignments for Declarative Process Model Conformance Checking
Mar 13, 2025In many engineering applications, processes must be followed precisely, making conformance checking between event logs and declarative process models crucial for ensuring adherence to desired behaviors. This is a critical area where Artificial Intelligence (AI) plays a pivotal role in driving effective process improvement. However, computing optimal alignments poses significant computational challenges due to the vast search space inherent in these models. Consequently, existing approaches often struggle with scalability and efficiency, limiting their applicability in real-world settings. This paper introduces DeclareAligner, a novel algorithm that uses the A* search algorithm, an established AI pathfinding technique, to tackle the problem from a fresh perspective leveraging the flexibility of declarative models. Key features of DeclareAligner include only performing actions that actively contribute to fixing constraint violations, utilizing a tailored heuristic to navigate towards optimal solutions, and employing early pruning to eliminate unproductive branches, while also streamlining the process through preprocessing and consolidating multiple fixes into unified actions. The proposed method is evaluated using 8,054 synthetic and real-life alignment problems, demonstrating its ability to efficiently compute optimal alignments by significantly outperforming the current state of the art. By enabling process analysts to more effectively identify and understand conformance issues, DeclareAligner has the potential to drive meaningful process improvement and management.
TVBench: Redesigning Video-Language Evaluation
Oct 10, 2024


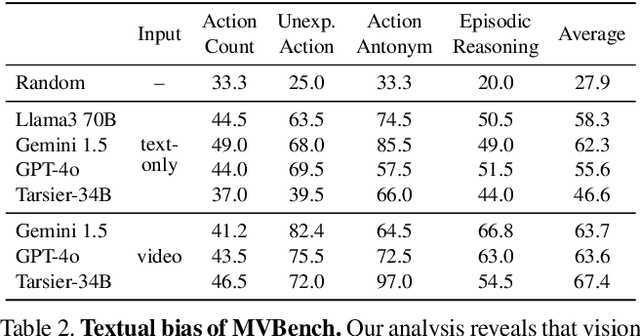
Large language models have demonstrated impressive performance when integrated with vision models even enabling video understanding. However, evaluating these video models presents its own unique challenges, for which several benchmarks have been proposed. In this paper, we show that the currently most used video-language benchmarks can be solved without requiring much temporal reasoning. We identified three main issues in existing datasets: (i) static information from single frames is often sufficient to solve the tasks (ii) the text of the questions and candidate answers is overly informative, allowing models to answer correctly without relying on any visual input (iii) world knowledge alone can answer many of the questions, making the benchmarks a test of knowledge replication rather than visual reasoning. In addition, we found that open-ended question-answering benchmarks for video understanding suffer from similar issues while the automatic evaluation process with LLMs is unreliable, making it an unsuitable alternative. As a solution, we propose TVBench, a novel open-source video multiple-choice question-answering benchmark, and demonstrate through extensive evaluations that it requires a high level of temporal understanding. Surprisingly, we find that most recent state-of-the-art video-language models perform similarly to random performance on TVBench, with only Gemini-Pro and Tarsier clearly surpassing this baseline.
Lost and Found: Overcoming Detector Failures in Online Multi-Object Tracking
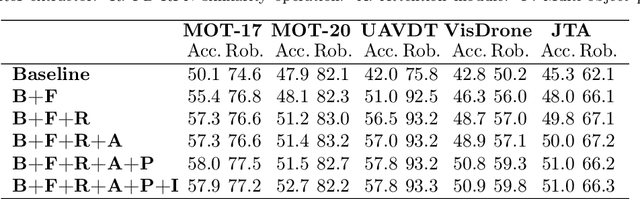
Jul 16, 2024Multi-object tracking (MOT) endeavors to precisely estimate the positions and identities of multiple objects over time. The prevailing approach, tracking-by-detection (TbD), first detects objects and then links detections, resulting in a simple yet effective method. However, contemporary detectors may occasionally miss some objects in certain frames, causing trackers to cease tracking prematurely. To tackle this issue, we propose BUSCA, meaning `to search', a versatile framework compatible with any online TbD system, enhancing its ability to persistently track those objects missed by the detector, primarily due to occlusions. Remarkably, this is accomplished without modifying past tracking results or accessing future frames, i.e., in a fully online manner. BUSCA generates proposals based on neighboring tracks, motion, and learned tokens. Utilizing a decision Transformer that integrates multimodal visual and spatiotemporal information, it addresses the object-proposal association as a multi-choice question-answering task. BUSCA is trained independently of the underlying tracker, solely on synthetic data, without requiring fine-tuning. Through BUSCA, we showcase consistent performance enhancements across five different trackers and establish a new state-of-the-art baseline across three different benchmarks. Code available at: https://github.com/lorenzovaquero/BUSCA.
Depth Estimation and Image Restoration by Deep Learning from Defocused Images
Feb 21, 2023



Monocular depth estimation and image deblurring are two fundamental tasks in computer vision, given their crucial role in understanding 3D scenes. Performing any of them by relying on a single image is an ill-posed problem. The recent advances in the field of deep convolutional neural networks (DNNs) have revolutionized many tasks in computer vision, including depth estimation and image deblurring. When it comes to using defocused images, the depth estimation and the recovery of the All-in-Focus (Aif) image become related problems due to defocus physics. In spite of this, most of the existing models treat them separately. There are, however, recent models that solve these problems simultaneously by concatenating two networks in a sequence to first estimate the depth or defocus map and then reconstruct the focused image based on it. We propose a DNN that solves the depth estimation and image deblurring in parallel. Our Two-headed Depth Estimation and Deblurring Network (2HDED:NET) extends a conventional Depth from Defocus (DFD) network with a deblurring branch that shares the same encoder as the depth branch. The proposed method has been successfully tested on two benchmarks, one for indoor and the other for outdoor scenes: NYU-v2 and Make3D. Extensive experiments with 2HDED:NET on these benchmarks have demonstrated superior or close performances to those of the state-of-the-art models for depth estimation and image deblurring.
Real-Time Siamese Multiple Object Tracker with Enhanced Proposals
Feb 10, 2022
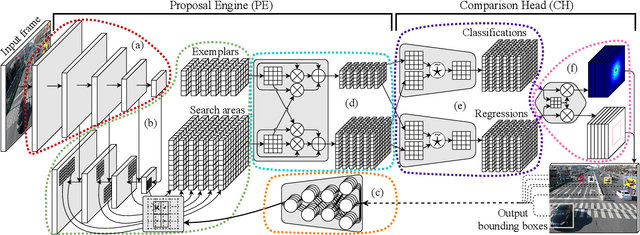

Maintaining the identity of multiple objects in real-time video is a challenging task, as it is not always possible to run a detector on every frame. Thus, motion estimation systems are often employed, which either do not scale well with the number of targets or produce features with limited semantic information. To solve the aforementioned problems and allow the tracking of dozens of arbitrary objects in real-time, we propose SiamMOTION. SiamMOTION includes a novel proposal engine that produces quality features through an attention mechanism and a region-of-interest extractor fed by an inertia module and powered by a feature pyramid network. Finally, the extracted tensors enter a comparison head that efficiently matches pairs of exemplars and search areas, generating quality predictions via a pairwise depthwise region proposal network and a multi-object penalization module. SiamMOTION has been validated on five public benchmarks, achieving leading performance against current state-of-the-art trackers.
Spatio-temporal Tubelet Feature Aggregation and Object Linking in Videos
Apr 01, 2020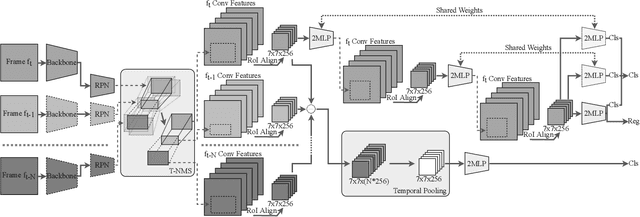


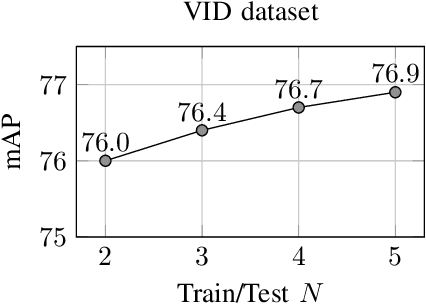
This paper addresses the problem of how to exploit spatio-temporal information available in videos to improve the object detection precision. We propose a two stage object detector called FANet based on short-term spatio-temporal feature aggregation to give a first detection set, and long-term object linking to refine these detections. Firstly, we generate a set of short tubelet proposals containing the object in $N$ consecutive frames. Then, we aggregate RoI pooled deep features through the tubelet using a temporal pooling operator that summarizes the information with a fixed size output independent of the number of input frames. On top of that, we define a double head implementation that we feed with spatio-temporal aggregated information for spatio-temporal object classification, and with spatial information extracted from the current frame for object localization and spatial classification. Furthermore, we also specialize each head branch architecture to better perform in each task taking into account the input data. Finally, a long-term linking method builds long tubes using the previously calculated short tubelets to overcome detection errors. We have evaluated our model in the widely used ImageNet VID dataset achieving a 80.9% mAP, which is the new state-of-the-art result for single models. Also, in the challenging small object detection dataset USC-GRAD-STDdb, our proposal outperforms the single frame baseline by 5.4% mAP.
Graduated Fidelity Lattices for Motion Planning under Uncertainty
May 31, 2019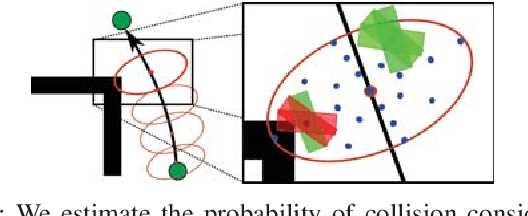
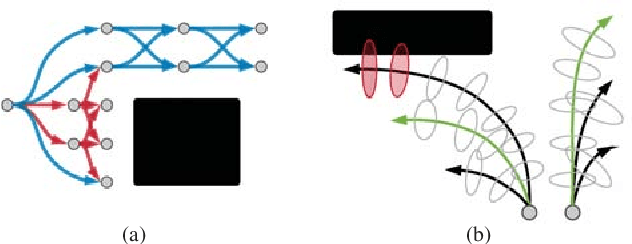

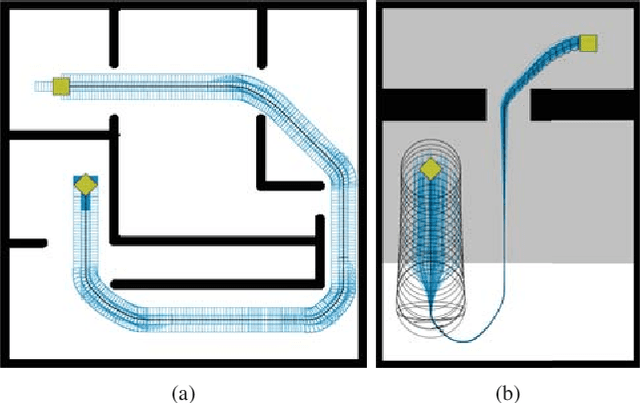
We present a novel approach for motion planning in mobile robotics under sensing and motion uncertainty based on state lattices with graduated fidelity. The probability of collision is reliably estimated considering the robot shape, and the fidelity adapts to the complexity of the environment, improving the planning efficiency while maintaining the performance. Safe and optimal paths are found with an informed search algorithm, for which a novel multi-resolution heuristic is presented. Results for different scenarios and robot shapes are given, showing the validity of the proposed methods.
Mining Frequent Patterns in Process Models
Oct 11, 2017
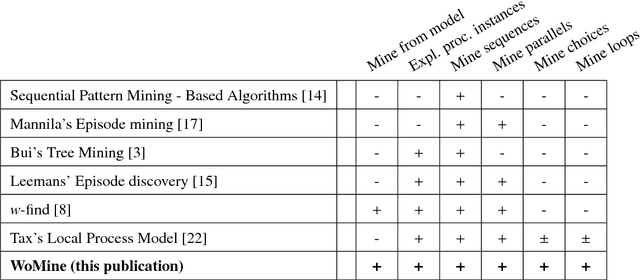

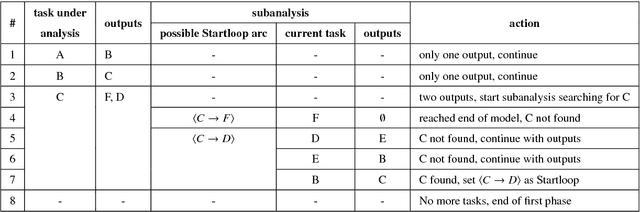
Process mining has emerged as a way to analyze the behavior of an organization by extracting knowledge from event logs and by offering techniques to discover, monitor and enhance real processes. In the discovery of process models, retrieving a complex one, i.e., a hardly readable process model, can hinder the extraction of information. Even in well-structured process models, there is information that cannot be obtained with the current techniques. In this paper, we present WoMine, an algorithm to retrieve frequent behavioural patterns from the model. Our approach searches in process models extracting structures with sequences, selections, parallels and loops, which are frequently executed in the logs. This proposal has been validated with a set of process models, including some from BPI Challenges, and compared with the state of the art techniques. Experiments have validated that WoMine can find all types of patterns, extracting information that cannot be mined with the state of the art techniques.
Hybrid Optimization Algorithm for Large-Scale QoS-Aware Service Composition
Sep 21, 2015
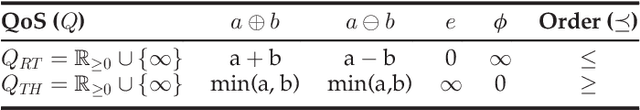
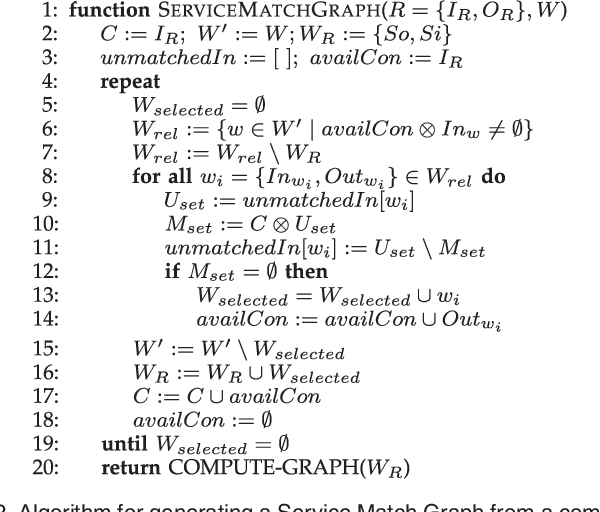
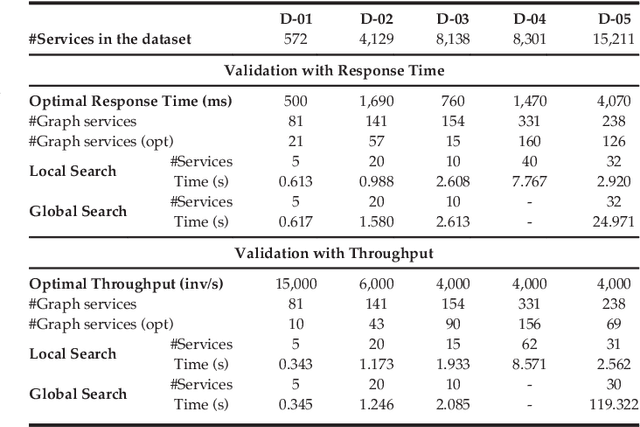
In this paper we present a hybrid approach for automatic composition of Web services that generates semantic input-output based compositions with optimal end-to-end QoS, minimizing the number of services of the resulting composition. The proposed approach has four main steps: 1) generation of the composition graph for a request; 2) computation of the optimal composition that minimizes a single objective QoS function; 3) multi-step optimizations to reduce the search space by identifying equivalent and dominated services; and 4) hybrid local-global search to extract the optimal QoS with the minimum number of services. An extensive validation with the datasets of the Web Service Challenge 2009-2010 and randomly generated datasets shows that: 1) the combination of local and global optimization is a general and powerful technique to extract optimal compositions in diverse scenarios; and 2) the hybrid strategy performs better than the state-of-the-art, obtaining solutions with less services and optimal QoS.
An Integrated Semantic Web Service Discovery and Composition Framework
Feb 10, 2015
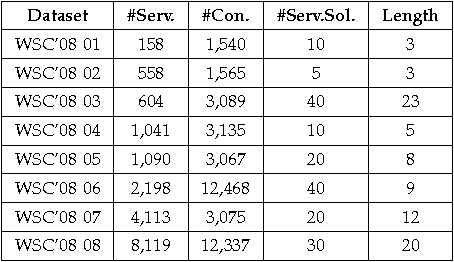

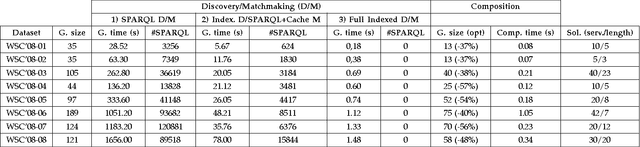
In this paper we present a theoretical analysis of graph-based service composition in terms of its dependency with service discovery. Driven by this analysis we define a composition framework by means of integration with fine-grained I/O service discovery that enables the generation of a graph-based composition which contains the set of services that are semantically relevant for an input-output request. The proposed framework also includes an optimal composition search algorithm to extract the best composition from the graph minimising the length and the number of services, and different graph optimisations to improve the scalability of the system. A practical implementation used for the empirical analysis is also provided. This analysis proves the scalability and flexibility of our proposal and provides insights on how integrated composition systems can be designed in order to achieve good performance in real scenarios for the Web.