 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cardiac Risk Prediction Using Data Generation Techniques
Dec 19, 2025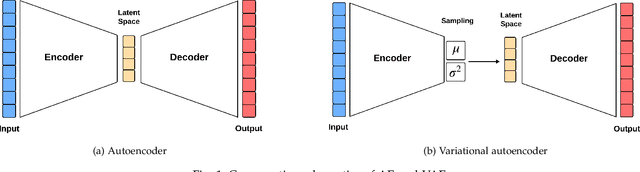

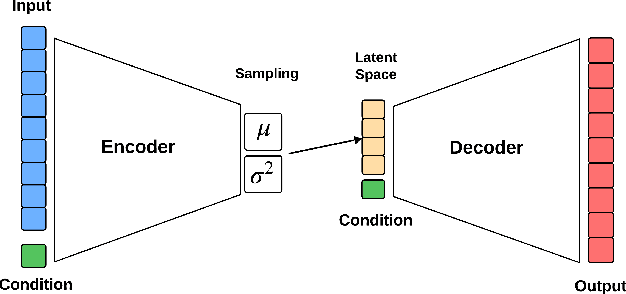
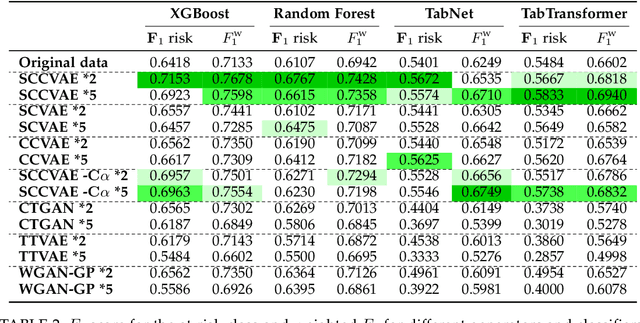
Cardiac rehabilitation constitutes a structured clinical process involving multiple interdependent phases, individualized medical decisions, and the coordinated participation of diverse healthcare professionals. This sequential and adaptive nature enables the program to be modeled as a business process, thereby facilitating its analysis. Nevertheless, studies in this context face significant limitations inherent to real-world medical databases: data are often scarce due to both economic costs and the time required for collection; many existing records are not suitable for specific analytical purposes; and, finally, there is a high prevalence of missing values, as not all patients undergo the same diagnostic tests. To address these limitations, this work proposes an architecture based on a Conditional Variational Autoencoder (CVAE) for the synthesis of realistic clinical records that are coherent with real-world observations. The primary objective is to increase the size and diversity of the available datasets in order to enhance the performance of cardiac risk prediction models and to reduce the need for potentially hazardous diagnostic procedures, such as exercise stress testing. The results demonstrate that the proposed architecture is capable of generating coherent and realistic synthetic data, whose use improves the accuracy of the various classifiers employed for cardiac risk detection, outperforming state-of-the-art deep learning approaches for synthetic data generation.
DeclareAligner: A Leap Towards Efficient Optimal Alignments for Declarative Process Model Conformance Checking
Mar 13, 2025In many engineering applications, processes must be followed precisely, making conformance checking between event logs and declarative process models crucial for ensuring adherence to desired behaviors. This is a critical area where Artificial Intelligence (AI) plays a pivotal role in driving effective process improvement. However, computing optimal alignments poses significant computational challenges due to the vast search space inherent in these models. Consequently, existing approaches often struggle with scalability and efficiency, limiting their applicability in real-world settings. This paper introduces DeclareAligner, a novel algorithm that uses the A* search algorithm, an established AI pathfinding technique, to tackle the problem from a fresh perspective leveraging the flexibility of declarative models. Key features of DeclareAligner include only performing actions that actively contribute to fixing constraint violations, utilizing a tailored heuristic to navigate towards optimal solutions, and employing early pruning to eliminate unproductive branches, while also streamlining the process through preprocessing and consolidating multiple fixes into unified actions. The proposed method is evaluated using 8,054 synthetic and real-life alignment problems, demonstrating its ability to efficiently compute optimal alignments by significantly outperforming the current state of the art. By enabling process analysts to more effectively identify and understand conformance issues, DeclareAligner has the potential to drive meaningful process improvement and management.
Prompting LLMs with content plans to enhance the summarization of scientific articles
Dec 15, 2023



This paper presents novel prompting techniques to improve the performance of automatic summarization systems for scientific articles. Scientific article summarization is highly challenging due to the length and complexity of these documents. We conceive, implement, and evaluate prompting techniques that provide additional contextual information to guide summarization systems. Specifically, we feed summarizers with lists of key terms extracted from articles, such as author keywords or automatically generated keywords. Our techniques are tested with various summarization models and input texts. Results show performance gains, especially for smaller models summarizing sections separately. This evidences that prompting is a promising approach to overcoming the limitations of less powerful systems. Our findings introduce a new research direction of using prompts to aid smaller models.
Process-To-Text: A Framework for the Quantitative Description of Processes in Natural Language
May 23, 2023In this paper we present the Process-To-Text (P2T) framework for the automatic generation of textual descriptive explanations of processes. P2T integrates three AI paradigms: process mining for extracting temporal and structural information from a process, fuzzy linguistic protoforms for modelling uncertain terms, and natural language generation for building the explanations. A real use-case in the cardiology domain is presented, showing the potential of P2T for providing natural language explanations addressed to specialists.
Fuzzy Temporal Protoforms for the Quantitative Description of Processes in Natural Language
May 16, 2023In this paper, we propose a series of fuzzy temporal protoforms in the framework of the automatic generation of quantitative and qualitative natural language descriptions of processes. The model includes temporal and causal information from processes and attributes, quantifies attributes in time during the process life-span and recalls causal relations and temporal distances between events, among other features. Through integrating process mining techniques and fuzzy sets within the usual Data-to-Text architecture, our framework is able to extract relevant quantitative temporal as well as structural information from a process and describe it in natural language involving uncertain terms. A real use-case in the cardiology domain is presented, showing the potential of our model for providing natural language explanations addressed to domain experts.
Encoder-Decoder Model for Suffix Prediction in Predictive Monitoring
Nov 29, 2022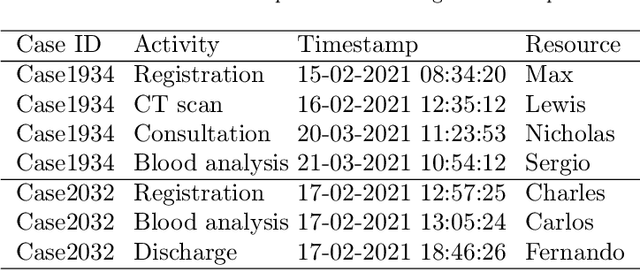
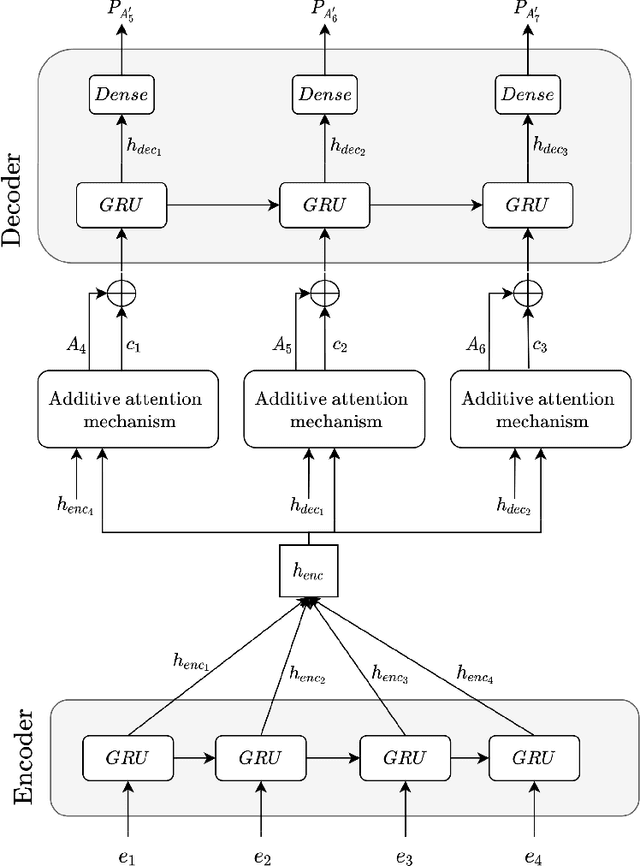

Predictive monitoring is a subfield of process mining that aims to predict how a running case will unfold in the future. One of its main challenges is forecasting the sequence of activities that will occur from a given point in time -- suffix prediction -- . Most approaches to the suffix prediction problem learn to predict the suffix by learning how to predict the next activity only, not learning from the whole suffix during the training phase. This paper proposes a novel architecture based on an encoder-decoder model with an attention mechanism that decouples the representation learning of the prefixes from the inference phase, predicting only the activities of the suffix. During the inference phase, this architecture is extended with a heuristic search algorithm that improves the selection of the activity for each index of the suffix. Our approach has been tested using 12 public event logs against 6 different state-of-the-art proposals, showing that it significantly outperforms these proposals.
Gradual Drift Detection in Process Models Using Conformance Metrics
Jul 22, 2022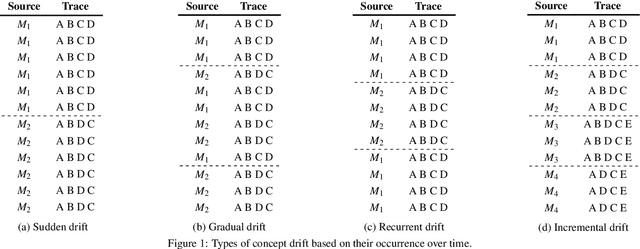


Changes, planned or unexpected, are common during the execution of real-life processes. Detecting these changes is a must for optimizing the performance of organizations running such processes. Most of the algorithms present in the state-of-the-art focus on the detection of sudden changes, leaving aside other types of changes. In this paper, we will focus on the automatic detection of gradual drifts, a special type of change, in which the cases of two models overlap during a period of time. The proposed algorithm relies on conformance checking metrics to carry out the automatic detection of the changes, performing also a fully automatic classification of these changes into sudden or gradual. The approach has been validated with a synthetic dataset consisting of 120 logs with different distributions of changes, getting better results in terms of detection and classification accuracy, delay and change region overlapping than the main state-of-the-art algorithms.
Embedding Graph Convolutional Networks in Recurrent Neural Networks for Predictive Monitoring
Dec 23, 2021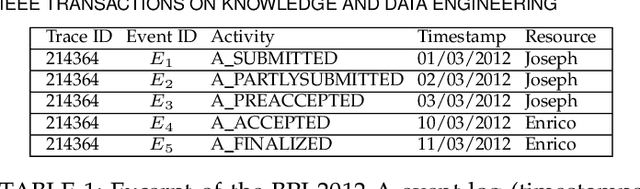

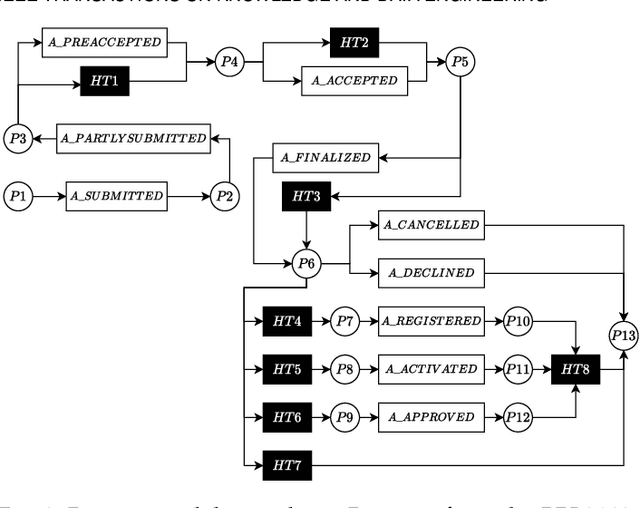

Predictive monitoring of business processes is a subfield of process mining that aims to predict, among other things, the characteristics of the next event or the sequence of next events. Although multiple approaches based on deep learning have been proposed, mainly recurrent neural networks and convolutional neural networks, none of them really exploit the structural information available in process models. This paper proposes an approach based on graph convolutional networks and recurrent neural networks that uses information directly from the process model. An experimental evaluation on real-life event logs shows that our approach is more consistent and outperforms the current state-of-the-art approaches.
Deep Learning for Predictive Business Process Monitoring: Review and Benchmark
Sep 24, 2020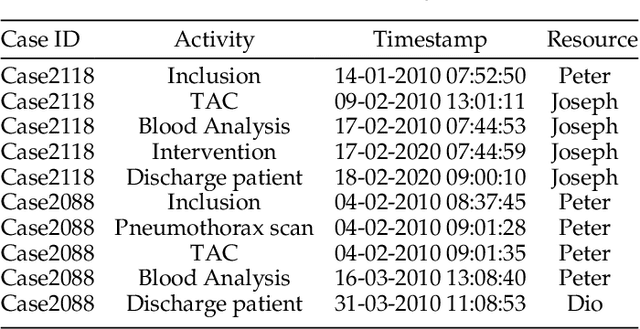
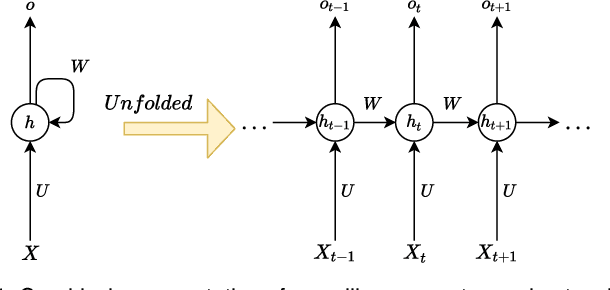
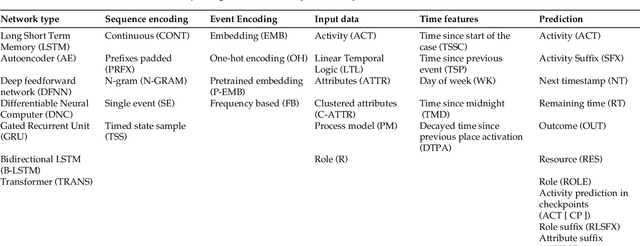
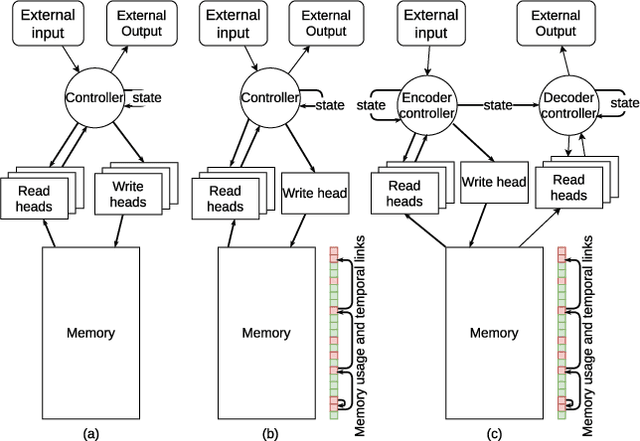
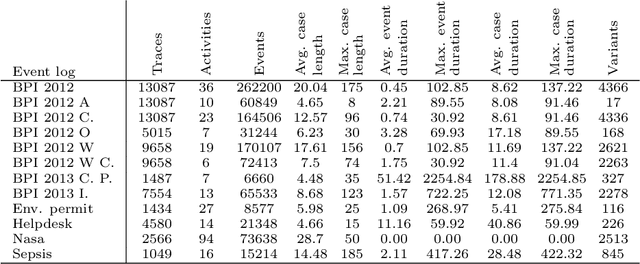
Predictive monitoring of business processes is concerned with the prediction of ongoing cases on a business process. Lately, the popularity of deep learning techniques has propitiated an ever-growing set of approaches focused on predictive monitoring based on these techniques. However, the high disparity of process logs and experimental setups used to evaluate these approaches makes it especially difficult to make a fair comparison. Furthermore, it also difficults the selection of the most suitable approach to solve a specific problem. In this paper, we provide both a systematic literature review of approaches that use deep learning to tackle the predictive monitoring tasks. In addition, we performed an exhaustive experimental evaluation of 10 different approaches over 12 publicly available process logs.
A Conformance Checking-based Approach for Drift Detection in Business Processes
Jul 09, 2019
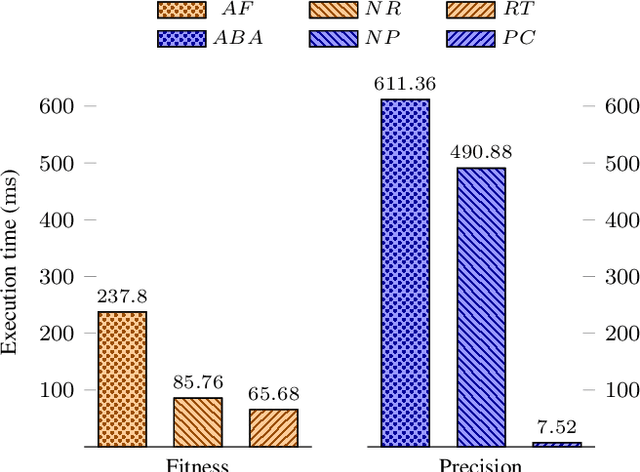
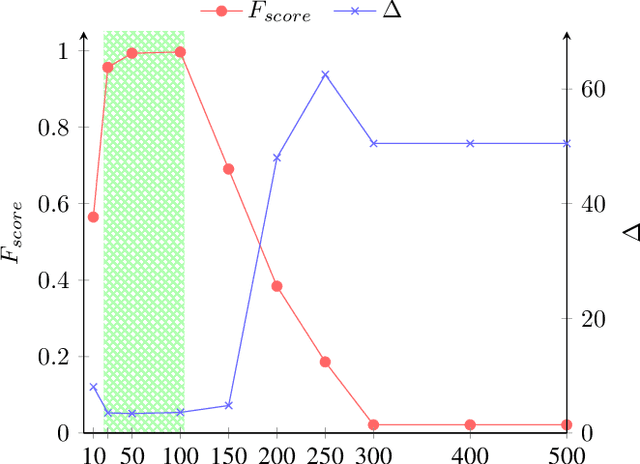
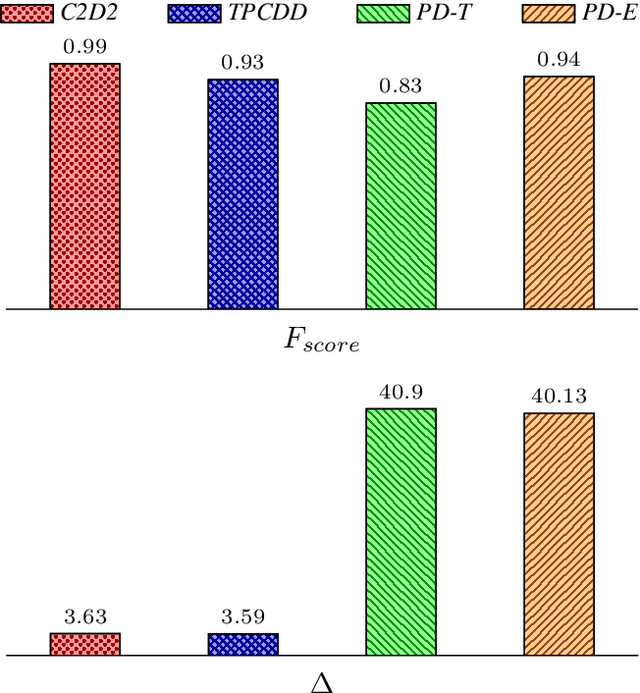
Real life business processes change over time, in both planned and unexpected ways. The detection of these changes is crucial for organizations to ensure that the expected and the real behavior are as similar as possible. These changes over time are called concept drift and its detection is a big challenge in process mining since the inherent complexity of the data makes difficult distinguishing between a change and an anomalous execution. In this paper, we present C2D2 (Conformance Checking-based Drift Detection), a new approach to detect sudden control-flow changes in the process models from event traces. C2D2 combines discovery techniques with conformance checking methods to perform an offline detection. Our approach has been validated with a synthetic benchmarking dataset formed by 68 logs, showing an improvement in the accuracy while maintaining a minimum delay in the drift detection.