 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVBench: Redesigning Video-Language Evaluation
Oct 10, 2024Large language models have demonstrated impressive performance when integrated with vision models even enabling video understanding. However, evaluating these video models presents its own unique challenges, for which several benchmarks have been proposed. In this paper, we show that the currently most used video-language benchmarks can be solved without requiring much temporal reasoning. We identified three main issues in existing datasets: (i) static information from single frames is often sufficient to solve the tasks (ii) the text of the questions and candidate answers is overly informative, allowing models to answer correctly without relying on any visual input (iii) world knowledge alone can answer many of the questions, making the benchmarks a test of knowledge replication rather than visual reasoning. In addition, we found that open-ended question-answering benchmarks for video understanding suffer from similar issues while the automatic evaluation process with LLMs is unreliable, making it an unsuitable alternative. As a solution, we propose TVBench, a novel open-source video multiple-choice question-answering benchmark, and demonstrate through extensive evaluations that it requires a high level of temporal understanding. Surprisingly, we find that most recent state-of-the-art video-language models perform similarly to random performance on TVBench, with only Gemini-Pro and Tarsier clearly surpassing this baseline.
Spatio-temporal Tubelet Feature Aggregation and Object Linking in Videos
Apr 01, 2020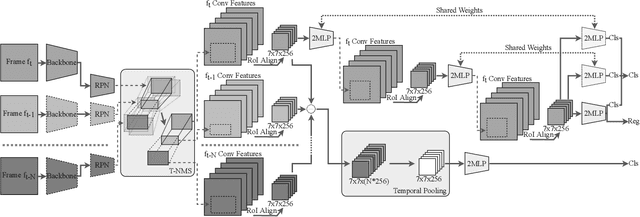


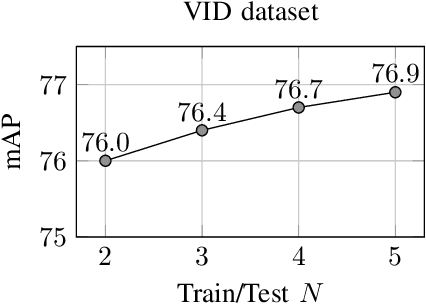
This paper addresses the problem of how to exploit spatio-temporal information available in videos to improve the object detection precision. We propose a two stage object detector called FANet based on short-term spatio-temporal feature aggregation to give a first detection set, and long-term object linking to refine these detections. Firstly, we generate a set of short tubelet proposals containing the object in $N$ consecutive frames. Then, we aggregate RoI pooled deep features through the tubelet using a temporal pooling operator that summarizes the information with a fixed size output independent of the number of input frames. On top of that, we define a double head implementation that we feed with spatio-temporal aggregated information for spatio-temporal object classification, and with spatial information extracted from the current frame for object localization and spatial classification. Furthermore, we also specialize each head branch architecture to better perform in each task taking into account the input data. Finally, a long-term linking method builds long tubes using the previously calculated short tubelets to overcome detection errors. We have evaluated our model in the widely used ImageNet VID dataset achieving a 80.9% mAP, which is the new state-of-the-art result for single models. Also, in the challenging small object detection dataset USC-GRAD-STDdb, our proposal outperforms the single frame baseline by 5.4% mAP.