 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Estimation and Image Restoration by Deep Learning from Defocused Images
Feb 21, 2023



Monocular depth estimation and image deblurring are two fundamental tasks in computer vision, given their crucial role in understanding 3D scenes. Performing any of them by relying on a single image is an ill-posed problem. The recent advances in the field of deep convolutional neural networks (DNNs) have revolutionized many tasks in computer vision, including depth estimation and image deblurring. When it comes to using defocused images, the depth estimation and the recovery of the All-in-Focus (Aif) image become related problems due to defocus physics. In spite of this, most of the existing models treat them separately. There are, however, recent models that solve these problems simultaneously by concatenating two networks in a sequence to first estimate the depth or defocus map and then reconstruct the focused image based on it. We propose a DNN that solves the depth estimation and image deblurring in parallel. Our Two-headed Depth Estimation and Deblurring Network (2HDED:NET) extends a conventional Depth from Defocus (DFD) network with a deblurring branch that shares the same encoder as the depth branch. The proposed method has been successfully tested on two benchmarks, one for indoor and the other for outdoor scenes: NYU-v2 and Make3D. Extensive experiments with 2HDED:NET on these benchmarks have demonstrated superior or close performances to those of the state-of-the-art models for depth estimation and image deblurring.
Real-Time Siamese Multiple Object Tracker with Enhanced Proposals
Feb 10, 2022
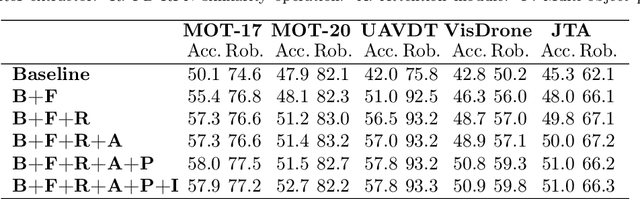
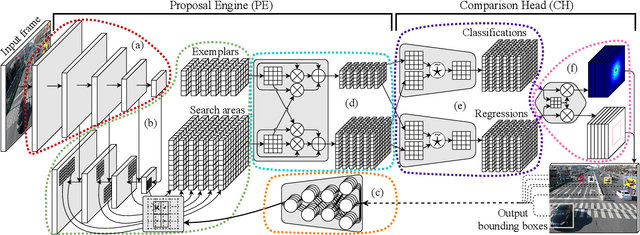

Maintaining the identity of multiple objects in real-time video is a challenging task, as it is not always possible to run a detector on every frame. Thus, motion estimation systems are often employed, which either do not scale well with the number of targets or produce features with limited semantic information. To solve the aforementioned problems and allow the tracking of dozens of arbitrary objects in real-time, we propose SiamMOTION. SiamMOTION includes a novel proposal engine that produces quality features through an attention mechanism and a region-of-interest extractor fed by an inertia module and powered by a feature pyramid network. Finally, the extracted tensors enter a comparison head that efficiently matches pairs of exemplars and search areas, generating quality predictions via a pairwise depthwise region proposal network and a multi-object penalization module. SiamMOTION has been validated on five public benchmarks, achieving leading performance against current state-of-the-art trackers.
Spatio-temporal Tubelet Feature Aggregation and Object Linking in Videos
Apr 01, 2020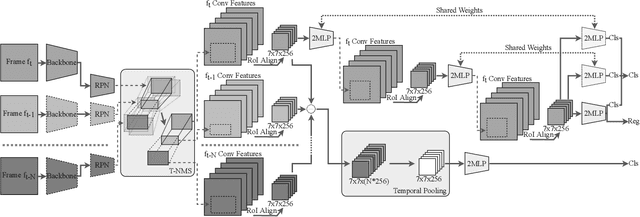


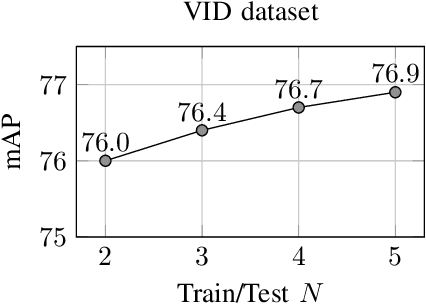
This paper addresses the problem of how to exploit spatio-temporal information available in videos to improve the object detection precision. We propose a two stage object detector called FANet based on short-term spatio-temporal feature aggregation to give a first detection set, and long-term object linking to refine these detections. Firstly, we generate a set of short tubelet proposals containing the object in $N$ consecutive frames. Then, we aggregate RoI pooled deep features through the tubelet using a temporal pooling operator that summarizes the information with a fixed size output independent of the number of input frames. On top of that, we define a double head implementation that we feed with spatio-temporal aggregated information for spatio-temporal object classification, and with spatial information extracted from the current frame for object localization and spatial classification. Furthermore, we also specialize each head branch architecture to better perform in each task taking into account the input data. Finally, a long-term linking method builds long tubes using the previously calculated short tubelets to overcome detection errors. We have evaluated our model in the widely used ImageNet VID dataset achieving a 80.9% mAP, which is the new state-of-the-art result for single models. Also, in the challenging small object detection dataset USC-GRAD-STDdb, our proposal outperforms the single frame baseline by 5.4% mAP.
Deep Learning-Based Multiple Object Visual Tracking on Embedded System for IoT and Mobile Edge Computing Applications
Jul 31, 2018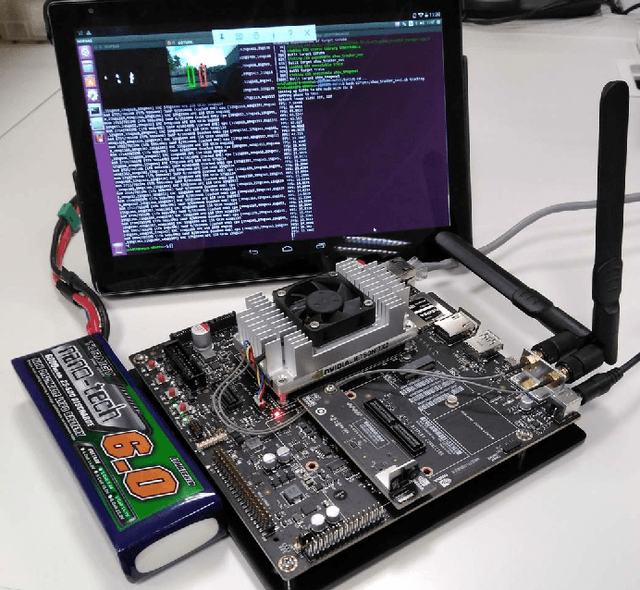



Compute and memory demands of state-of-the-art deep learning methods are still a shortcoming that must be addressed to make them useful at IoT end-nodes. In particular, recent results depict a hopeful prospect for image processing using Convolutional Neural Netwoks, CNNs, but the gap between software and hardware implementations is already considerable for IoT and mobile edge computing applications due to their high power consumption. This proposal performs low-power and real time deep learning-based multiple object visual tracking implemented on an NVIDIA Jetson TX2 development kit. It includes a camera and wireless connection capability and it is battery powered for mobile and outdoor applications. A collection of representative sequences captured with the on-board camera, dETRUSC video dataset, is used to exemplify the performance of the proposed algorithm and to facilitate benchmarking. The results in terms of power consumption and frame rate demonstrate the feasibility of deep learning algorithms on embedded platforms although more effort to joint algorithm and hardware design of CNNs is needed.