 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Simulating Cross-game Operations in Playable Environments for FPS World Models
May 28, 2026Interactive world models for first-person shooter (FPS) games must resolve high-frequency overlapping control signals at every frame without disrupting unaffected regions. Existing methods inject actions globally and train on single titles, failing under dense FPS inputs. We observe that FPS actions are spatially selective: discrete events such as firing or reloading affect only a localized region around the weapon (the scope), while continuous camera and movement signals govern stable surroundings. We propose SCOPE, which inserts a conditioning module into each transformer block of a pretrained video diffusion model. It reshapes features into per-pixel temporal sequences so that each position computes its action response from local visual content. This separates in-scope effects from out-of-scope generation without segmentation labels. We also introduce CrossFPS, the first multi-game FPS dataset with frame-aligned action telemetry. It comprises 69K clips from 7 titles with 10-DoF controller signals, curated to remove gameplay bias. The model learns general visual-to-action mappings rather than game-specific patterns, enabling zero-shot transfer to unseen scenes. Experiments confirm strong action responsiveness, precise scope separation, and effective cross-game generalization.
Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
May 18, 2026Modern interactive video world models have achieved impressive visual fidelity, yet lack fine-grained multi-entity control and cross-entity, cross-world generalization. We trace this gap to the action interface: standard control protocols (e.g. animation IDs, device inputs, scene-level captions) bind action semantics to specific entities or engines at design time. We propose natural language as the interface to unlock expressiveness that no prior interface can achieve, and we present Incantation, the first interactive video world model with per-latent-frame (0.25 s) natural-language conditioning that supports simultaneous multi-entity control and concept-level cross-entity transfer beyond any fixed rendering pipeline. We pair a pretrained bidirectional video backbone with frame-local text cross-attention, and enable real-time long-horizon streaming through ODE-initialized Self-Forcing distillation with a RoPE-decoupled sliding KV-cache. We surpass the Action-Index baseline on cross-entity transfer (89% vs. 43%) and out-of-vocabulary prompts (90% vs. 0%), and our 2-step student sustains 19.7 FPS at 480p with stable FVD over 2-hour rollouts. We further apply the same architecture and training recipe to The King of Fighters, changing only the per-entity action vocabulary slots. We have released a preview subset of the Incantation dataset at https://huggingface.co/datasets/zhush/incantation-elden-ring-scenes, containing manually collected Elden Ring player-boss combat clips with structured action-oriented metadata. Larger-scale Elden Ring and KOF data will be released with the full project.
From Pixels to Concepts: Do Segmentation Models Understand What They Segment?
May 10, 2026Segmentation is a fundamental vision task underlying numerous downstream applications. Recent promptable segmentation models, such as Segment Anything Model 3 (SAM3), extend segmentation from category-agnostic mask prediction to concept-guided localization conditioned on high-level textual prompts. However, existing benchmarks primarily evaluate mask accuracy or object presence, leaving unclear whether these models faithfully ground the queried concept or instead rely on visually salient but semantically misleading cues. We introduce CAFE: \textbf{C}ounterfactual \textbf{A}ttribute \textbf{F}actuality \textbf{E}valuation, a novel benchmark for evaluating concept-faithful segmentation in promptable segmentation models. Our \textbf{CAFE} is built on attribute-level counterfactual manipulation: the target region and ground-truth mask are preserved, while attributes such as surface appearance, context, or material composition are modified to introduce misleading semantic cues. The benchmark contains 2,146 paired test samples, each consisting of a target image, a ground-truth mask, a positive prompt, and a misleading negative prompt. These samples cover three counterfactual categories: Superficial Mimicry (\textbf{SM}), Context Conflict (\textbf{CC}), and Ontological Conflict (\textbf{OC}). We evaluate various model types and sizes on our CAFE. Experiments reveal a systematic gap between localization quality and concept discrimination: models often generate accurate masks even for misleading prompts, suggesting that strong mask prediction does not necessarily imply faithful semantic grounding. Our CAFE provides a controlled benchmark for diagnosing whether promptable segmentation models perform concept-faithful grounding rather than shortcut-driven mask retrieval.
Can LLMs Act as Historians? Evaluating Historical Research Capabilities of LLMs via the Chinese Imperial Examination
Apr 27, 2026While Large Language Models (LLMs) have increasingly assisted in historical tasks such as text processing, their capacity for professional-level historical reasoning remains underexplored. Existing benchmarks primarily assess basic knowledge breadth or lexical understanding, failing to capture the higher-order skills, such as evidentiary reasoning,that are central to historical research. To fill this gap, we introduce ProHist-Bench, a novel benchmark anchored in the Chinese Imperial Examination (Keju) system, a comprehensive microcosm of East Asian political, social, and intellectual history spanning over 1,300 years. Developed through deep interdisciplinary collaboration, ProHist-Bench features 400 challenging, expert-curated questions across eight dynasties, accompanied by 10,891 fine-grained evaluation rubrics. Through a rigorous evaluation of 18 LLMs, we reveal a significant proficiency gap: even state-of-the-art LLMs struggle with complex historical research questions. We hope ProHist-Bench will facilitate the development of domain-specific reasoning LLMs, advance computational historical research, and further uncover the untapped potential of LLMs. We release ProHist-Bench at https://github.com/inclusionAI/ABench/tree/main/ProHist-Bench.
SpotEdit: Selective Region Editing in Diffusion Transformers
Dec 26, 2025Diffusion Transformer models have significantly advanced image editing by encoding conditional images and integrating them into transformer layers. However, most edits involve modifying only small regions, while current methods uniformly process and denoise all tokens at every timestep, causing redundant computation and potentially degrading unchanged areas. This raises a fundamental question: Is it truly necessary to regenerate every region during editing? To address this, we propose SpotEdit, a training-free diffusion editing framework that selectively updates only the modified regions. SpotEdit comprises two key components: SpotSelector identifies stable regions via perceptual similarity and skips their computation by reusing conditional image features; SpotFusion adaptively blends these features with edited tokens through a dynamic fusion mechanism, preserving contextual coherence and editing quality. By reducing unnecessary computation and maintaining high fidelity in unmodified areas, SpotEdit achieves efficient and precise image editing.
MICo-150K: A Comprehensive Dataset Advancing Multi-Image Composition
Dec 08, 2025



In controllable image generation, synthesizing coherent and consistent images from multiple reference inputs, i.e., Multi-Image Composition (MICo), remains a challenging problem, partly hindered by the lack of high-quality training data. To bridge this gap, we conduct a systematic study of MICo, categorizing it into 7 representative tasks and curate a large-scale collection of high-quality source images and construct diverse MICo prompts. Leveraging powerful proprietary models, we synthesize a rich amount of balanced composite images, followed by human-in-the-loop filtering and refinement, resulting in MICo-150K, a comprehensive dataset for MICo with identity consistency. We further build a Decomposition-and-Recomposition (De&Re) subset, where 11K real-world complex images are decomposed into components and recomposed, enabling both real and synthetic compositions. To enable comprehensive evaluation, we construct MICo-Bench with 100 cases per task and 300 challenging De&Re cases, and further introduce a new metric, Weighted-Ref-VIEScore, specifically tailored for MICo evaluation. Finally, we fine-tune multiple models on MICo-150K and evaluate them on MICo-Bench. The results show that MICo-150K effectively equips models without MICo capability and further enhances those with existing skills. Notably, our baseline model, Qwen-MICo, fine-tuned from Qwen-Image-Edit, matches Qwen-Image-2509 in 3-image composition while supporting arbitrary multi-image inputs beyond the latter's limitation. Our dataset, benchmark, and baseline collectively offer valuable resources for further research on Multi-Image Composition.
Minute-Long Videos with Dual Parallelisms
May 29, 2025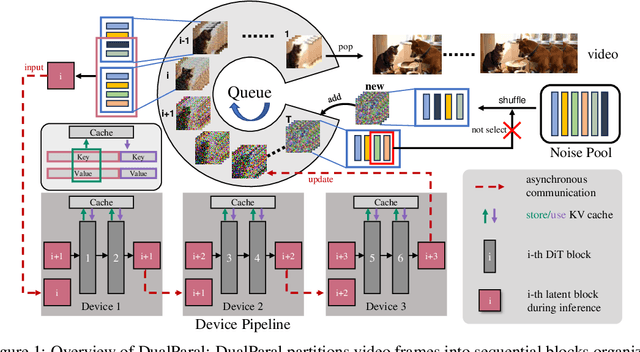



Diffusion Transformer (DiT)-based video diffusion models generate high-quality videos at scale but incur prohibitive processing latency and memory costs for long videos. To address this, we propose a novel distributed inference strategy, termed DualParal. The core idea is that, instead of generating an entire video on a single GPU, we parallelize both temporal frames and model layers across GPUs. However, a naive implementation of this division faces a key limitation: since diffusion models require synchronized noise levels across frames, this implementation leads to the serialization of original parallelisms. We leverage a block-wise denoising scheme to handle this. Namely, we process a sequence of frame blocks through the pipeline with progressively decreasing noise levels. Each GPU handles a specific block and layer subset while passing previous results to the next GPU, enabling asynchronous computation and communication. To further optimize performance, we incorporate two key enhancements. Firstly, a feature cache is implemented on each GPU to store and reuse features from the prior block as context, minimizing inter-GPU communication and redundant computation. Secondly, we employ a coordinated noise initialization strategy, ensuring globally consistent temporal dynamics by sharing initial noise patterns across GPUs without extra resource costs. Together, these enable fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generator, our method efficiently produces 1,025-frame videos with up to 6.54$\times$ lower latency and 1.48$\times$ lower memory cost on 8$\times$RTX 4090 GPUs.
TimeCausality: Evaluating the Causal Ability in Time Dimension for Vision Language Models
May 21, 2025



Reasoning about temporal causality, particularly irreversible transformations of objects governed by real-world knowledge (e.g., fruit decay and human aging), is a fundamental aspect of human visual understanding. Unlike temporal perception based on simple event sequences, this form of reasoning requires a deeper comprehension of how object states change over time. Although the current powerful Vision-Language Models (VLMs) have demonstrated impressive performance on a wide range of downstream tasks, their capacity to reason about temporal causality remains underexplored. To address this gap, we introduce \textbf{TimeCausality}, a novel benchmark specifically designed to evaluate the causal reasoning ability of VLMs in the temporal dimension. Based on our TimeCausality, we find that while the current SOTA open-source VLMs have achieved performance levels comparable to closed-source models like GPT-4o on various standard visual question answering tasks, they fall significantly behind on our benchmark compared with their closed-source competitors. Furthermore, even GPT-4o exhibits a marked drop in performance on TimeCausality compared to its results on other tasks. These findings underscore the critical need to incorporate temporal causality into the evaluation and development of VLMs, and they highlight an important challenge for the open-source VLM community moving forward. Code and Data are available at \href{https://github.com/Zeqing-Wang/TimeCausality }{TimeCausality}.
Tracking-Aware Deformation Field Estimation for Non-rigid 3D Reconstruction in Robotic Surgeries
Mar 04, 2025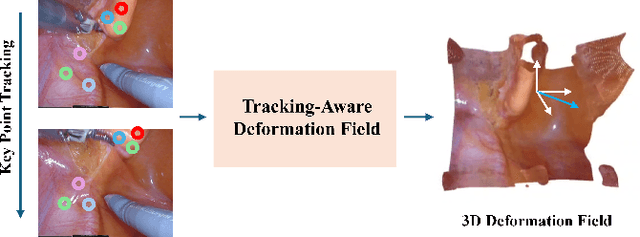



Minimally invasive procedures have been advanced rapidly by the robotic laparoscopic surgery. The latter greatly assists surgeons in sophisticated and precise operations with reduced invasiveness. Nevertheless, it is still safety critical to be aware of even the least tissue deformation during instrument-tissue interactions, especially in 3D space. To address this, recent works rely on NeRF to render 2D videos from different perspectives and eliminate occlusions. However, most of the methods fail to predict the accurate 3D shapes and associated deformation estimates robustly. Differently, we propose Tracking-Aware Deformation Field (TADF), a novel framework which reconstructs the 3D mesh along with the 3D tissue deformation simultaneously. It first tracks the key points of soft tissue by a foundation vision model, providing an accurate 2D deformation field. Then, the 2D deformation field is smoothly incorporated with a neural implicit reconstruction network to obtain tissue deformation in the 3D space. Finally, we experimentally demonstrate that the proposed method provides more accurate deformation estimation compared with other 3D neural reconstruction methods in two public datasets.
SAMCL: Empowering SAM to Continually Learn from Dynamic Domains
Dec 06, 2024Segment Anything Model (SAM) struggles with segmenting objects in the open world, especially across diverse and dynamic domains. Continual segmentation (CS) is a potential technique to solve this issue, but a significant obstacle is the intractable balance between previous domains (stability) and new domains (plasticity) during CS. Furthermore, how to utilize two kinds of features of SAM, images and prompts, in an efficient and effective CS manner remains a significant hurdle. In this work, we propose a novel CS method, termed SAMCL, to address these challenges. It is the first study to empower SAM with the CS ability across dynamic domains. SAMCL decouples stability and plasticity during CS by two components: $\textit{AugModule}$ and $\textit{Module Selector}$. Specifically, SAMCL leverages individual $\textit{AugModule}$ to effectively and efficiently learn new relationships between images and prompts in each domain. $\textit{Module Selector}$ selects the appropriate module during testing, based on the inherent ability of SAM to distinguish between different domains. These two components enable SAMCL to realize a task-agnostic method without any interference across different domains. Experimental results demonstrate that SAMCL outperforms state-of-the-art methods, achieving an exceptionally low average forgetting of just $0.5$%, along with at least a $2.5$% improvement in transferring to unseen domains. Moreover, the tunable parameter consumption in AugModule is about $0.236$MB, marking at least a $23.3$% reduction compared to other fine-tuning methods.