 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirMoE: Dirichlet-routed Mixture of Experts
Feb 09, 2026Mixture-of-Experts (MoE) models have demonstrated exceptional performance in large-scale language models. Existing routers typically rely on non-differentiable Top-$k$+Softmax, limiting their performance and scalability. We argue that two distinct decisions, which experts to activate and how to distribute expert contributions among them, are conflated in standard Top-$k$+Softmax. We introduce Dirichlet-Routed MoE (DirMoE), a novel end-to-end differentiable routing mechanism built on a Dirichlet variational autoencoder framework. This design fundamentally disentangles the core routing problems: expert selection, modeled by a Bernoulli component, and expert contribution among chosen experts, handled by a Dirichlet component. The entire forward pass remains fully differentiable through the use of Gumbel-Sigmoid relaxation for the expert selection and implicit reparameterization for the Dirichlet distribution. Our training objective, a variational ELBO, includes a direct sparsity penalty that precisely controls the number of active experts in expectation, alongside a schedule for key hyperparameters that guides the model from an exploratory to a definitive routing state. Moreover, our DirMoE router matches or exceeds other methods while improving expert specialization.
WorldWarp: Propagating 3D Geometry with Asynchronous Video Diffusion
Dec 22, 2025Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, state-of-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly warping historical content into novel views, this cache acts as a structural scaffold, ensuring each new frame respects prior geometry. However, static warping inevitably leaves holes and artifacts due to occlusions. We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a "fill-and-revise" objective. Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement. By dynamically updating the 3D cache at every step, WorldWarp maintains consistency across video chunks. Consequently, it achieves state-of-the-art fidelity by ensuring that 3D logic guides structure while diffusion logic perfects texture. Project page: \href{https://hyokong.github.io/worldwarp-page/}{https://hyokong.github.io/worldwarp-page/}.
DeContext as Defense: Safe Image Editing in Diffusion Transformers
Dec 19, 2025In-context diffusion models allow users to modify images with remarkable ease and realism. However, the same power raises serious privacy concerns: personal images can be easily manipulated for identity impersonation, misinformation, or other malicious uses, all without the owner's consent. While prior work has explored input perturbations to protect against misuse in personalized text-to-image generation, the robustness of modern, large-scale in-context DiT-based models remains largely unexamined. In this paper, we propose DeContext, a new method to safeguard input images from unauthorized in-context editing. Our key insight is that contextual information from the source image propagates to the output primarily through multimodal attention layers. By injecting small, targeted perturbations that weaken these cross-attention pathways, DeContext breaks this flow, effectively decouples the link between input and output. This simple defense is both efficient and robust. We further show that early denoising steps and specific transformer blocks dominate context propagation, which allows us to concentrate perturbations where they matter most. Experiments on Flux Kontext and Step1X-Edit show that DeContext consistently blocks unwanted image edits while preserving visual quality. These results highlight the effectiveness of attention-based perturbations as a powerful defense against image manipulation. Code is available at https://github.com/LinghuiiShen/DeContext.
C4D: 4D Made from 3D through Dual Correspondences
Oct 16, 2025Recovering 4D from monocular video, which jointly estimates dynamic geometry and camera poses, is an inevitably challenging problem. While recent pointmap-based 3D reconstruction methods (e.g., DUSt3R) have made great progress in reconstructing static scenes, directly applying them to dynamic scenes leads to inaccurate results. This discrepancy arises because moving objects violate multi-view geometric constraints, disrupting the reconstruction. To address this, we introduce C4D, a framework that leverages temporal Correspondences to extend existing 3D reconstruction formulation to 4D. Specifically, apart from predicting pointmaps, C4D captures two types of correspondences: short-term optical flow and long-term point tracking. We train a dynamic-aware point tracker that provides additional mobility information, facilitating the estimation of motion masks to separate moving elements from the static background, thus offering more reliable guidance for dynamic scenes. Furthermore, we introduce a set of dynamic scene optimization objectives to recover per-frame 3D geometry and camera parameters. Simultaneously, the correspondences lift 2D trajectories into smooth 3D trajectories, enabling fully integrated 4D reconstruction. Experiments show that our framework achieves complete 4D recovery and demonstrates strong performance across multiple downstream tasks, including depth estimation, camera pose estimation, and point tracking. Project Page: https://littlepure2333.github.io/C4D
Don't Forget the Nonlinearity: Unlocking Activation Functions in Efficient Fine-Tuning
Sep 16, 2025Existing parameter-efficient fine-tuning (PEFT) methods primarily adapt weight matrices while keeping activation functions fixed. We introduce \textbf{NoRA}, the first PEFT framework that directly adapts nonlinear activation functions in pretrained transformer-based models. NoRA replaces fixed activations with learnable rational functions and applies structured low-rank updates to numerator and denominator coefficients, with a group-wise design that localizes adaptation and improves stability at minimal cost. On vision transformers trained on CIFAR-10 and CIFAR-100, NoRA matches or exceeds full fine-tuning while updating only 0.4\% of parameters (0.02M), achieving accuracy gains of +0.17\% and +0.27\%. When combined with LoRA (\textbf{NoRA++}), it outperforms LoRA and DoRA under matched training budgets by adding fewer trainable parameters. On LLaMA3-8B instruction tuning, NoRA++ consistently improves generation quality, yielding average MMLU gains of +0.3\%--0.8\%, including +1.6\% on STEM (Alpaca) and +1.3\% on OpenOrca. We further show that NoRA constrains adaptation to a low-dimensional functional subspace, implicitly regularizing update magnitude and direction. These results establish activation-space tuning as a complementary and highly parameter-efficient alternative to weight-based PEFT, positioning activation functions as first-class objects for model adaptation.
Test3R: Learning to Reconstruct 3D at Test Time
Jun 16, 2025



Dense matching methods like DUSt3R regress pairwise pointmaps for 3D reconstruction. However, the reliance on pairwise prediction and the limited generalization capability inherently restrict the global geometric consistency. In this work, we introduce Test3R, a surprisingly simple test-time learning technique that significantly boosts geometric accuracy. Using image triplets ($I_1,I_2,I_3$), Test3R generates reconstructions from pairs ($I_1,I_2$) and ($I_1,I_3$). The core idea is to optimize the network at test time via a self-supervised objective: maximizing the geometric consistency between these two reconstructions relative to the common image $I_1$. This ensures the model produces cross-pair consistent outputs, regardless of the inputs. Extensive experiments demonstrate that our technique significantly outperforms previous state-of-the-art methods on the 3D reconstruction and multi-view depth estimation tasks. Moreover, it is universally applicable and nearly cost-free, making it easily applied to other models and implemented with minimal test-time training overhead and parameter footprint. Code is available at https://github.com/nopQAQ/Test3R.
Image Editing As Programs with Diffusion Models
Jun 04, 2025While diffusion models have achieved remarkable success in text-to-image generation, they encounter significant challenges with instruction-driven image editing. Our research highlights a key challenge: these models particularly struggle with structurally inconsistent edits that involve substantial layout changes. To mitigate this gap, we introduce Image Editing As Programs (IEAP), a unified image editing framework built upon the Diffusion Transformer (DiT) architecture. At its core, IEAP approaches instructional editing through a reductionist lens, decomposing complex editing instructions into sequences of atomic operations. Each operation is implemented via a lightweight adapter sharing the same DiT backbone and is specialized for a specific type of edit. Programmed by a vision-language model (VLM)-based agent, these operations collaboratively support arbitrary and structurally inconsistent transformations. By modularizing and sequencing edits in this way, IEAP generalizes robustly across a wide range of editing tasks, from simple adjustments to substantial structural changes. Extensive experiments demonstrate that IEAP significantly outperforms state-of-the-art methods on standard benchmarks across various editing scenarios. In these evaluations, our framework delivers superior accuracy and semantic fidelity, particularly for complex, multi-step instructions. Codes are available at https://github.com/YujiaHu1109/IEAP.
Minute-Long Videos with Dual Parallelisms
May 29, 2025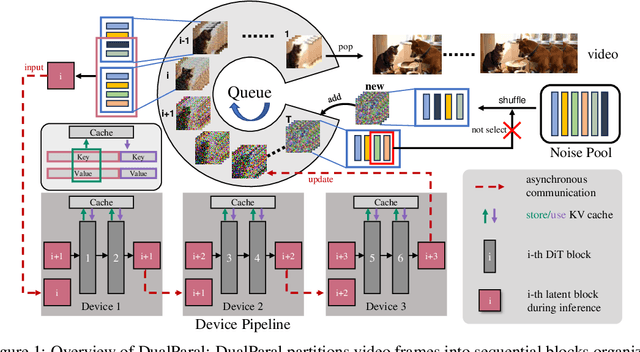



Diffusion Transformer (DiT)-based video diffusion models generate high-quality videos at scale but incur prohibitive processing latency and memory costs for long videos. To address this, we propose a novel distributed inference strategy, termed DualParal. The core idea is that, instead of generating an entire video on a single GPU, we parallelize both temporal frames and model layers across GPUs. However, a naive implementation of this division faces a key limitation: since diffusion models require synchronized noise levels across frames, this implementation leads to the serialization of original parallelisms. We leverage a block-wise denoising scheme to handle this. Namely, we process a sequence of frame blocks through the pipeline with progressively decreasing noise levels. Each GPU handles a specific block and layer subset while passing previous results to the next GPU, enabling asynchronous computation and communication. To further optimize performance, we incorporate two key enhancements. Firstly, a feature cache is implemented on each GPU to store and reuse features from the prior block as context, minimizing inter-GPU communication and redundant computation. Secondly, we employ a coordinated noise initialization strategy, ensuring globally consistent temporal dynamics by sharing initial noise patterns across GPUs without extra resource costs. Together, these enable fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generator, our method efficiently produces 1,025-frame videos with up to 6.54$\times$ lower latency and 1.48$\times$ lower memory cost on 8$\times$RTX 4090 GPUs.
Flash Sculptor: Modular 3D Worlds from Objects
Apr 08, 2025Existing text-to-3D and image-to-3D models often struggle with complex scenes involving multiple objects and intricate interactions. Although some recent attempts have explored such compositional scenarios, they still require an extensive process of optimizing the entire layout, which is highly cumbersome if not infeasible at all. To overcome these challenges, we propose Flash Sculptor in this paper, a simple yet effective framework for compositional 3D scene/object reconstruction from a single image. At the heart of Flash Sculptor lies a divide-and-conquer strategy, which decouples compositional scene reconstruction into a sequence of sub-tasks, including handling the appearance, rotation, scale, and translation of each individual instance. Specifically, for rotation, we introduce a coarse-to-fine scheme that brings the best of both worlds--efficiency and accuracy--while for translation, we develop an outlier-removal-based algorithm that ensures robust and precise parameters in a single step, without any iterative optimization. Extensive experiments demonstrate that Flash Sculptor achieves at least a 3 times speedup over existing compositional 3D methods, while setting new benchmarks in compositional 3D reconstruction performance. Codes are available at https://github.com/YujiaHu1109/Flash-Sculptor.
1000+ FPS 4D Gaussian Splatting for Dynamic Scene Rendering
Mar 20, 2025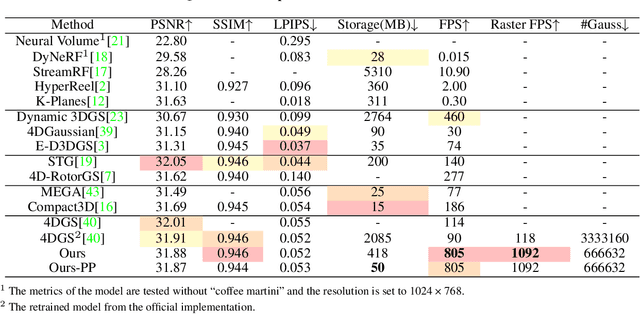
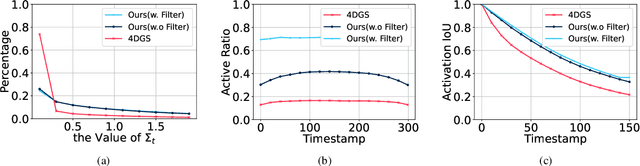
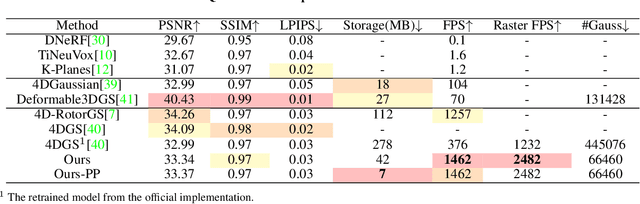

4D Gaussian Splatting (4DGS) has recently gained considerable attention as a method for reconstructing dynamic scenes. Despite achieving superior quality, 4DGS typically requires substantial storage and suffers from slow rendering speed. In this work, we delve into these issues and identify two key sources of temporal redundancy. (Q1) \textbf{Short-Lifespan Gaussians}: 4DGS uses a large portion of Gaussians with short temporal span to represent scene dynamics, leading to an excessive number of Gaussians. (Q2) \textbf{Inactive Gaussians}: When rendering, only a small subset of Gaussians contributes to each frame. Despite this, all Gaussians are processed during rasterization, resulting in redundant computation overhead. To address these redundancies, we present \textbf{4DGS-1K}, which runs at over 1000 FPS on modern GPUs. For Q1, we introduce the Spatial-Temporal Variation Score, a new pruning criterion that effectively removes short-lifespan Gaussians while encouraging 4DGS to capture scene dynamics using Gaussians with longer temporal spans. For Q2, we store a mask for active Gaussians across consecutive frames, significantly reducing redundant computations in rendering. Compared to vanilla 4DGS, our method achieves a $41\times$ reduction in storage and $9\times$ faster rasterization speed on complex dynamic scenes, while maintaining comparable visual quality. Please see our project page at https://4DGS-1K.github.io.