 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHACMatch Semi-Supervised Rotation Regression with Hardness-Aware Curriculum Pseudo Labeling
Mar 23, 2026Regressing 3D rotations of objects from 2D images is a crucial yet challenging task, with broad applications in autonomous driving, virtual reality, and robotic control. Existing rotation regression models often rely on large amounts of labeled data for training or require additional information beyond 2D images, such as point clouds or CAD models. Therefore, exploring semi-supervised rotation regression using only a limited number of labeled 2D images is highly valuable. While recent work FisherMatch introduces semi-supervised learning to rotation regression, it suffers from rigid entropy-based pseudo-label filtering that fails to effectively distinguish between reliable and unreliable unlabeled samples. To address this limitation, we propose a hardness-aware curriculum learning framework that dynamically selects pseudo-labeled samples based on their difficulty, progressing from easy to complex examples. We introduce both multi-stage and adaptive curriculum strategies to replace fixed-threshold filtering with more flexible, hardness-aware mechanisms. Additionally, we present a novel structured data augmentation strategy specifically tailored for rotation estimation, which assembles composite images from augmented patches to introduce feature diversity while preserving critical geometric integrity. Comprehensive experiments on PASCAL3D+ and ObjectNet3D demonstrate that our method outperforms existing supervised and semi-supervised baselines, particularly in low-data regimes, validating the effectiveness of our curriculum learning framework and structured augmentation approach.
* This is an accepted manuscript of an article published in Computer Vision and Image Understanding
MORE: Multi-Organ Medical Image REconstruction Dataset
Oct 30, 2025CT reconstruction provides radiologists with images for diagnosis and treatment, yet current deep learning methods are typically limited to specific anatomies and datasets, hindering generalization ability to unseen anatomies and lesions. To address this, we introduce the Multi-Organ medical image REconstruction (MORE) dataset, comprising CT scans across 9 diverse anatomies with 15 lesion types. This dataset serves two key purposes: (1) enabling robust training of deep learning models on extensive, heterogeneous data, and (2) facilitating rigorous evaluation of model generalization for CT reconstruction. We further establish a strong baseline solution that outperforms prior approaches under these challenging conditions. Our results demonstrate that: (1) a comprehensive dataset helps improve the generalization capability of models, and (2) optimization-based methods offer enhanced robustness for unseen anatomies. The MORE dataset is freely accessible under CC-BY-NC 4.0 at our project page https://more-med.github.io/
BECAME: BayEsian Continual Learning with Adaptive Model MErging
Apr 03, 2025Continual Learning (CL) strives to learn incrementally across tasks while mitigating catastrophic forgetting. A key challenge in CL is balancing stability (retaining prior knowledge) and plasticity (learning new tasks). While representative gradient projection methods ensure stability, they often limit plasticity. Model merging techniques offer promising solutions, but prior methods typically rely on empirical assumptions and carefully selected hyperparameters. In this paper, we explore the potential of model merging to enhance the stability-plasticity trade-off, providing theoretical insights that underscore its benefits. Specifically, we reformulate the merging mechanism using Bayesian continual learning principles and derive a closed-form solution for the optimal merging coefficient that adapts to the diverse characteristics of tasks. To validate our approach, we introduce a two-stage framework named BECAME, which synergizes the expertise of gradient projection and adaptive merging. Extensive experiments show that our approach outperforms state-of-the-art CL methods and existing merging strategies.
Generating Negative Samples for Multi-Modal Recommendation
Jan 25, 2025Multi-modal recommender systems (MMRS) have gained significant attention due to their ability to leverage information from various modalities to enhance recommendation quality. However, existing negative sampling techniques often struggle to effectively utilize the multi-modal data, leading to suboptimal performance. In this paper, we identify two key challenges in negative sampling for MMRS: (1) producing cohesive negative samples contrasting with positive samples and (2) maintaining a balanced influence across different modalities. To address these challenges, we propose NegGen, a novel framework that utilizes multi-modal large language models (MLLMs) to generate balanced and contrastive negative samples. We design three different prompt templates to enable NegGen to analyze and manipulate item attributes across multiple modalities, and then generate negative samples that introduce better supervision signals and ensure modality balance. Furthermore, NegGen employs a causal learning module to disentangle the effect of intervened key features and irrelevant item attributes, enabling fine-grained learning of user preferences. Extensive experiments on real-world datasets demonstrate the superior performance of NegGen compared to state-of-the-art methods in both negative sampling and multi-modal recommendation.
Few-shot Implicit Function Generation via Equivariance
Jan 03, 2025



Implicit Neural Representations (INRs) have emerged as a powerful framework for representing continuous signals. However, generating diverse INR weights remains challenging due to limited training data. We introduce Few-shot Implicit Function Generation, a new problem setup that aims to generate diverse yet functionally consistent INR weights from only a few examples. This is challenging because even for the same signal, the optimal INRs can vary significantly depending on their initializations. To tackle this, we propose EquiGen, a framework that can generate new INRs from limited data. The core idea is that functionally similar networks can be transformed into one another through weight permutations, forming an equivariance group. By projecting these weights into an equivariant latent space, we enable diverse generation within these groups, even with few examples. EquiGen implements this through an equivariant encoder trained via contrastive learning and smooth augmentation, an equivariance-guided diffusion process, and controlled perturbations in the equivariant subspace. Experiments on 2D image and 3D shape INR datasets demonstrate that our approach effectively generates diverse INR weights while preserving their functional properties in few-shot scenarios.
Topology-Aware Popularity Debiasing via Simplicial Complexes
Nov 21, 2024Recommender systems (RS) play a critical role in delivering personalized content across various online platforms, leveraging collaborative filtering (CF) as a key technique to generate recommendations based on users' historical interaction data. Recent advancements in CF have been driven by the adoption of Graph Neural Networks (GNNs), which model user-item interactions as bipartite graphs, enabling the capture of high-order collaborative signals. Despite their success, GNN-based methods face significant challenges due to the inherent popularity bias in the user-item interaction graph's topology, leading to skewed recommendations that favor popular items over less-known ones. To address this challenge, we propose a novel topology-aware popularity debiasing framework, Test-time Simplicial Propagation (TSP), which incorporates simplicial complexes (SCs) to enhance the expressiveness of GNNs. Unlike traditional methods that focus on pairwise relationships, our approach captures multi-order relationships through SCs, providing a more comprehensive representation of user-item interactions. By enriching the neighborhoods of tail items and leveraging SCs for feature smoothing, TSP enables the propagation of multi-order collaborative signals and effectively mitigates biased propagation. Our TSP module is designed as a plug-and-play solution, allowing for seamless integration into pre-trained GNN-based models without the need for fine-tuning additional parameters. Extensive experiments on five real-world datasets demonstrate the superior performance of our method, particularly in long-tail recommendation tasks. Visualization results further confirm that TSP produces more uniform distributions of item representations, leading to fairer and more accurate recommendations.
Tree-of-Table: Unleashing the Power of LLMs for Enhanced Large-Scale Table Understanding
Nov 13, 2024The ubiquity and value of tables as semi-structured data across various domains necessitate advanced methods for understanding their complexity and vast amounts of information. Despite the impressive capabilities of large language models (LLMs) in advancing the natural language understanding frontier, their application to large-scale tabular data presents significant challenges, specifically regarding table size and complex intricate relationships. Existing works have shown promise with small-scale tables but often flounder when tasked with the complex reasoning required by larger, interconnected tables found in real-world scenarios. To address this gap, we introduce "Tree-of-Table", a novel approach designed to enhance LLMs' reasoning capabilities over large and complex tables. Our method employs Table Condensation and Decomposition to distill and reorganize relevant data into a manageable format, followed by the construction of a hierarchical Table-Tree that facilitates tree-structured reasoning. Through a meticulous Table-Tree Execution process, we systematically unravel the tree-structured reasoning chain to derive the solutions. Experiments across diverse datasets, including WikiTQ, TableFact, FeTaQA, and BIRD, demonstrate that Tree-of-Table sets a new benchmark with superior performance, showcasing remarkable efficiency and generalization capabilities in large-scale table reasoning.
Differentiable Gaussian Representation for Incomplete CT Reconstruction
Nov 07, 2024Incomplete Computed Tomography (CT) benefits patients by reducing radiation exposure. However, reconstructing high-fidelity images from limited views or angles remains challenging due to the ill-posed nature of the problem. Deep Learning Reconstruction (DLR) methods have shown promise in enhancing image quality, but the paradox between training data diversity and high generalization ability remains unsolved. In this paper, we propose a novel Gaussian Representation for Incomplete CT Reconstruction (GRCT) without the usage of any neural networks or full-dose CT data. Specifically, we model the 3D volume as a set of learnable Gaussians, which are optimized directly from the incomplete sinogram. Our method can be applied to multiple views and angles without changing the architecture. Additionally, we propose a differentiable Fast CT Reconstruction method for efficient clinical usage. Extensive experiments on multiple datasets and settings demonstrate significant improvements in reconstruction quality metrics and high efficiency. We plan to release our code as open-source.
NT-LLM: A Novel Node Tokenizer for Integrating Graph Structure into Large Language Models
Oct 14, 2024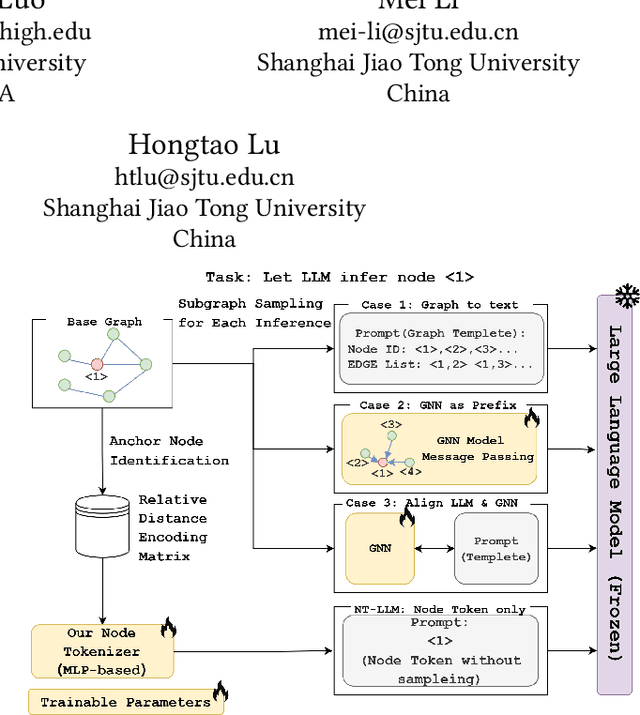

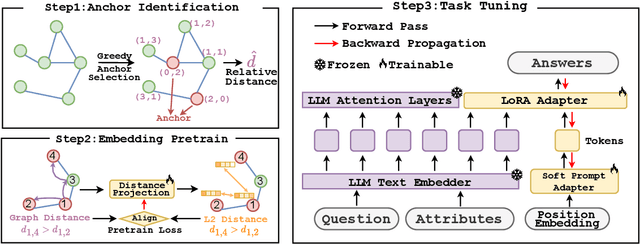

Graphs are a fundamental data structure for representing relationships in real-world scenarios. With the success of Large Language Models (LLMs) across various natural language processing (NLP) tasks, there has been growing interest in integrating LLMs for graph learning. However, applying LLMs to graph-related tasks poses significant challenges, as these models are not inherently designed to capture the complex structural information present in graphs. Existing approaches address this challenge through two strategies: the chain of tasks approach, which uses Graph Neural Networks (GNNs) to encode the graph structure so that LLMs are relieved from understanding spatial positions; and Graph-to-Text Conversion, which translates graph structures into semantic text representations that LLMs can process. Despite their progress, these methods often struggle to fully preserve the topological information of graphs or require extensive computational resources, limiting their practical applicability. In this work, we introduce Node Tokenizer for Large Language Models (NT-LLM), a novel framework that efficiently encodes graph structures by selecting key nodes as anchors and representing each node based on its relative distance to these anchors. This position-anchored encoding effectively captures the graph topology, enabling enhanced reasoning capabilities in LLMs over graph data. Additionally, we implement a task-specific tuning procedure to further improve structural understanding within LLMs. Through extensive empirical evaluations, NT-LLM demonstrates significant performance improvements across a variety of graph-related tasks.
PPTFormer: Pseudo Multi-Perspective Transformer for UAV Segmentation
Jun 28, 2024



The ascension of Unmanned Aerial Vehicles (UAVs) in various fields necessitates effective UAV image segmentation, which faces challenges due to the dynamic perspectives of UAV-captured images. Traditional segmentation algorithms falter as they cannot accurately mimic the complexity of UAV perspectives, and the cost of obtaining multi-perspective labeled datasets is prohibitive. To address these issues, we introduce the PPTFormer, a novel \textbf{P}seudo Multi-\textbf{P}erspective \textbf{T}rans\textbf{former} network that revolutionizes UAV image segmentation. Our approach circumvents the need for actual multi-perspective data by creating pseudo perspectives for enhanced multi-perspective learning. The PPTFormer network boasts Perspective Decomposition, novel Perspective Prototypes, and a specialized encoder and decoder that together achieve superior segmentation results through Pseudo Multi-Perspective Attention (PMP Attention) and fusion. Our experiments demonstrate that PPTFormer achieves state-of-the-art performance across five UAV segmentation datasets, confirming its capability to effectively simulate UAV flight perspectives and significantly advance segmentation precision. This work presents a pioneering leap in UAV scene understanding and sets a new benchmark for future developments in semantic segmentation.