 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHACMatch Semi-Supervised Rotation Regression with Hardness-Aware Curriculum Pseudo Labeling
Mar 23, 2026Regressing 3D rotations of objects from 2D images is a crucial yet challenging task, with broad applications in autonomous driving, virtual reality, and robotic control. Existing rotation regression models often rely on large amounts of labeled data for training or require additional information beyond 2D images, such as point clouds or CAD models. Therefore, exploring semi-supervised rotation regression using only a limited number of labeled 2D images is highly valuable. While recent work FisherMatch introduces semi-supervised learning to rotation regression, it suffers from rigid entropy-based pseudo-label filtering that fails to effectively distinguish between reliable and unreliable unlabeled samples. To address this limitation, we propose a hardness-aware curriculum learning framework that dynamically selects pseudo-labeled samples based on their difficulty, progressing from easy to complex examples. We introduce both multi-stage and adaptive curriculum strategies to replace fixed-threshold filtering with more flexible, hardness-aware mechanisms. Additionally, we present a novel structured data augmentation strategy specifically tailored for rotation estimation, which assembles composite images from augmented patches to introduce feature diversity while preserving critical geometric integrity. Comprehensive experiments on PASCAL3D+ and ObjectNet3D demonstrate that our method outperforms existing supervised and semi-supervised baselines, particularly in low-data regimes, validating the effectiveness of our curriculum learning framework and structured augmentation approach.
* This is an accepted manuscript of an article published in Computer Vision and Image Understanding
TextResNet: Decoupling and Routing Optimization Signals in Compound AI Systems via Deep Residual Tuning
Feb 09, 2026Textual Gradient-style optimizers (TextGrad) enable gradient-like feedback propagation through compound AI systems. However, they do not work well for deep chains. The root cause of this limitation stems from the Semantic Entanglement problem in these extended workflows. In standard textual backpropagation, feedback signals mix local critiques with upstream contexts, leading to Attribution Ambiguity. To address this challenge, we propose TextResNet, a framework that reformulates the optimization process to achieve precise signal routing via four key innovations. Firstly, in the forward pass, it enforces Additive Semantic Deltas to preserve an Identity Highway for gradient flow. Secondly, in the backward pass, it introduces Semantic Gradient Decomposition via a Semantic Projector to disentangle feedback into causally independent subspaces. Thirdly, it implements Causal Routing, which routes projected signals to their specific components. Finally, it performs Density-Aware Optimization Scheduling to leverage the disentangled signals to dynamically allocate resources to key system bottlenecks. Our results show that TextResNet not only achieves superior performance compared to TextGrad, but also exhibits remarkable stability for agentic tasks in compound AI systems where baselines collapse. Code is available at https://github.com/JeanDiable/TextResNet.
MORE: Multi-Organ Medical Image REconstruction Dataset
Oct 30, 2025CT reconstruction provides radiologists with images for diagnosis and treatment, yet current deep learning methods are typically limited to specific anatomies and datasets, hindering generalization ability to unseen anatomies and lesions. To address this, we introduce the Multi-Organ medical image REconstruction (MORE) dataset, comprising CT scans across 9 diverse anatomies with 15 lesion types. This dataset serves two key purposes: (1) enabling robust training of deep learning models on extensive, heterogeneous data, and (2) facilitating rigorous evaluation of model generalization for CT reconstruction. We further establish a strong baseline solution that outperforms prior approaches under these challenging conditions. Our results demonstrate that: (1) a comprehensive dataset helps improve the generalization capability of models, and (2) optimization-based methods offer enhanced robustness for unseen anatomies. The MORE dataset is freely accessible under CC-BY-NC 4.0 at our project page https://more-med.github.io/
BECAME: BayEsian Continual Learning with Adaptive Model MErging
Apr 03, 2025Continual Learning (CL) strives to learn incrementally across tasks while mitigating catastrophic forgetting. A key challenge in CL is balancing stability (retaining prior knowledge) and plasticity (learning new tasks). While representative gradient projection methods ensure stability, they often limit plasticity. Model merging techniques offer promising solutions, but prior methods typically rely on empirical assumptions and carefully selected hyperparameters. In this paper, we explore the potential of model merging to enhance the stability-plasticity trade-off, providing theoretical insights that underscore its benefits. Specifically, we reformulate the merging mechanism using Bayesian continual learning principles and derive a closed-form solution for the optimal merging coefficient that adapts to the diverse characteristics of tasks. To validate our approach, we introduce a two-stage framework named BECAME, which synergizes the expertise of gradient projection and adaptive merging. Extensive experiments show that our approach outperforms state-of-the-art CL methods and existing merging strategies.
Few-shot Implicit Function Generation via Equivariance
Jan 03, 2025



Implicit Neural Representations (INRs) have emerged as a powerful framework for representing continuous signals. However, generating diverse INR weights remains challenging due to limited training data. We introduce Few-shot Implicit Function Generation, a new problem setup that aims to generate diverse yet functionally consistent INR weights from only a few examples. This is challenging because even for the same signal, the optimal INRs can vary significantly depending on their initializations. To tackle this, we propose EquiGen, a framework that can generate new INRs from limited data. The core idea is that functionally similar networks can be transformed into one another through weight permutations, forming an equivariance group. By projecting these weights into an equivariant latent space, we enable diverse generation within these groups, even with few examples. EquiGen implements this through an equivariant encoder trained via contrastive learning and smooth augmentation, an equivariance-guided diffusion process, and controlled perturbations in the equivariant subspace. Experiments on 2D image and 3D shape INR datasets demonstrate that our approach effectively generates diverse INR weights while preserving their functional properties in few-shot scenarios.
Differentiable Gaussian Representation for Incomplete CT Reconstruction
Nov 07, 2024Incomplete Computed Tomography (CT) benefits patients by reducing radiation exposure. However, reconstructing high-fidelity images from limited views or angles remains challenging due to the ill-posed nature of the problem. Deep Learning Reconstruction (DLR) methods have shown promise in enhancing image quality, but the paradox between training data diversity and high generalization ability remains unsolved. In this paper, we propose a novel Gaussian Representation for Incomplete CT Reconstruction (GRCT) without the usage of any neural networks or full-dose CT data. Specifically, we model the 3D volume as a set of learnable Gaussians, which are optimized directly from the incomplete sinogram. Our method can be applied to multiple views and angles without changing the architecture. Additionally, we propose a differentiable Fast CT Reconstruction method for efficient clinical usage. Extensive experiments on multiple datasets and settings demonstrate significant improvements in reconstruction quality metrics and high efficiency. We plan to release our code as open-source.
Task Indicating Transformer for Task-conditional Dense Predictions
Mar 01, 2024



The task-conditional model is a distinctive stream for efficient multi-task learning. Existing works encounter a critical limitation in learning task-agnostic and task-specific representations, primarily due to shortcomings in global context modeling arising from CNN-based architectures, as well as a deficiency in multi-scale feature interaction within the decoder. In this paper, we introduce a novel task-conditional framework called Task Indicating Transformer (TIT) to tackle this challenge. Our approach designs a Mix Task Adapter module within the transformer block, which incorporates a Task Indicating Matrix through matrix decomposition, thereby enhancing long-range dependency modeling and parameter-efficient feature adaptation by capturing intra- and inter-task features. Moreover, we propose a Task Gate Decoder module that harnesses a Task Indicating Vector and gating mechanism to facilitate adaptive multi-scale feature refinement guided by task embeddings. Experiments on two public multi-task dense prediction benchmarks, NYUD-v2 and PASCAL-Context, demonstrate that our approach surpasses state-of-the-art task-conditional methods.
YOLO-MED : Multi-Task Interaction Network for Biomedical Images
Mar 01, 2024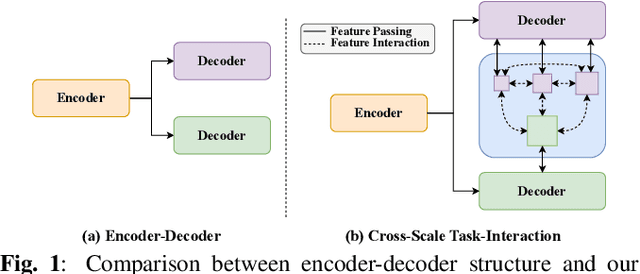
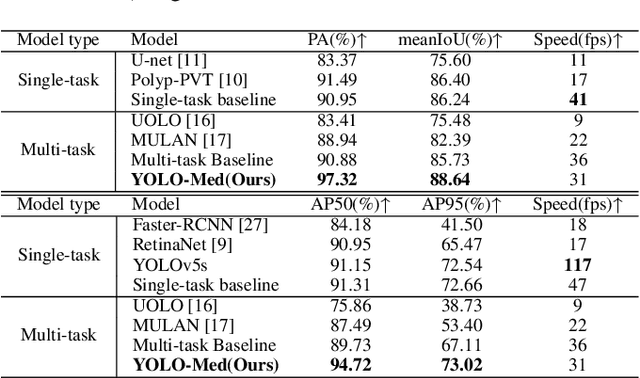
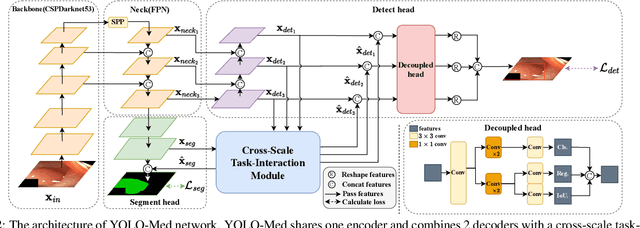

Object detection and semantic segmentation are pivotal components in biomedical image analysis. Current single-task networks exhibit promising outcomes in both detection and segmentation tasks. Multi-task networks have gained prominence due to their capability to simultaneously tackle segmentation and detection tasks, while also accelerating the segmentation inference. Nevertheless, recent multi-task networks confront distinct limitations such as the difficulty in striking a balance between accuracy and inference speed. Additionally, they often overlook the integration of cross-scale features, which is especially important for biomedical image analysis. In this study, we propose an efficient end-to-end multi-task network capable of concurrently performing object detection and semantic segmentation called YOLO-Med. Our model employs a backbone and a neck for multi-scale feature extraction, complemented by the inclusion of two task-specific decoders. A cross-scale task-interaction module is employed in order to facilitate information fusion between various tasks. Our model exhibits promising results in balancing accuracy and speed when evaluated on the Kvasir-seg dataset and a private biomedical image dataset.
Federated Multi-Task Learning on Non-IID Data Silos: An Experimental Study
Feb 20, 2024



The innovative Federated Multi-Task Learning (FMTL) approach consolidates the benefits of Federated Learning (FL) and Multi-Task Learning (MTL), enabling collaborative model training on multi-task learning datasets. However, a comprehensive evaluation method, integrating the unique features of both FL and MTL, is currently absent in the field. This paper fills this void by introducing a novel framework, FMTL-Bench, for systematic evaluation of the FMTL paradigm. This benchmark covers various aspects at the data, model, and optimization algorithm levels, and comprises seven sets of comparative experiments, encapsulating a wide array of non-independent and identically distributed (Non-IID) data partitioning scenarios. We propose a systematic process for comparing baselines of diverse indicators and conduct a case study on communication expenditure, time, and energy consumption. Through our exhaustive experiments, we aim to provide valuable insights into the strengths and limitations of existing baseline methods, contributing to the ongoing discourse on optimal FMTL application in practical scenarios. The source code will be made available for results replication.
Towards Hetero-Client Federated Multi-Task Learning
Nov 22, 2023
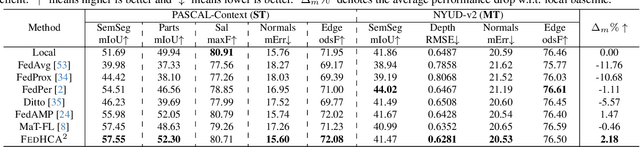


Federated Learning (FL) enables joint training across distributed clients using their local data privately. Federated Multi-Task Learning (FMTL) builds on FL to handle multiple tasks, assuming model congruity that identical model architecture is deployed in each client. To relax this assumption and thus extend real-world applicability, we introduce a novel problem setting, Hetero-Client Federated Multi-Task Learning (HC-FMTL), to accommodate diverse task setups. The main challenge of HC-FMTL is the model incongruity issue that invalidates conventional aggregation methods. It also escalates the difficulties in accurate model aggregation to deal with data and task heterogeneity inherent in FMTL. To address these challenges, we propose the FedHCA$^2$ framework, which allows for federated training of personalized models by modeling relationships among heterogeneous clients. Drawing on our theoretical insights into the difference between multi-task and federated optimization, we propose the Hyper Conflict-Averse Aggregation scheme to mitigate conflicts during encoder updates. Additionally, inspired by task interaction in MTL, the Hyper Cross Attention Aggregation scheme uses layer-wise cross attention to enhance decoder interactions while alleviating model incongruity. Moreover, we employ learnable Hyper Aggregation Weights for each client to customize personalized parameter updates. Extensive experiments demonstrate the superior performance of FedHCA$^2$ in various HC-FMTL scenarios compared to representative methods. Our code will be made publicly available.