 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Indicating Transformer for Task-conditional Dense Predictions
Mar 01, 2024



The task-conditional model is a distinctive stream for efficient multi-task learning. Existing works encounter a critical limitation in learning task-agnostic and task-specific representations, primarily due to shortcomings in global context modeling arising from CNN-based architectures, as well as a deficiency in multi-scale feature interaction within the decoder. In this paper, we introduce a novel task-conditional framework called Task Indicating Transformer (TIT) to tackle this challenge. Our approach designs a Mix Task Adapter module within the transformer block, which incorporates a Task Indicating Matrix through matrix decomposition, thereby enhancing long-range dependency modeling and parameter-efficient feature adaptation by capturing intra- and inter-task features. Moreover, we propose a Task Gate Decoder module that harnesses a Task Indicating Vector and gating mechanism to facilitate adaptive multi-scale feature refinement guided by task embeddings. Experiments on two public multi-task dense prediction benchmarks, NYUD-v2 and PASCAL-Context, demonstrate that our approach surpasses state-of-the-art task-conditional methods.
RAFT-MSF: Self-Supervised Monocular Scene Flow using Recurrent Optimizer
May 03, 2022
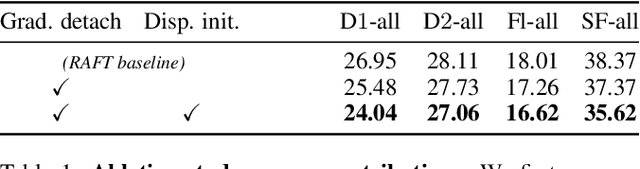
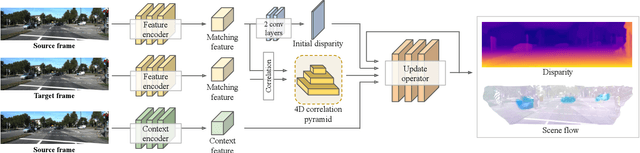
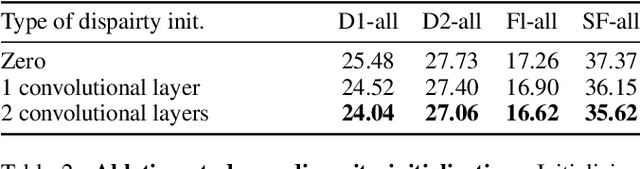
Learning scene flow from a monocular camera still remains a challenging task due to its ill-posedness as well as lack of annotated data. Self-supervised methods demonstrate learning scene flow estimation from unlabeled data, yet their accuracy lags behind (semi-)supervised methods. In this paper, we introduce a self-supervised monocular scene flow method that substantially improves the accuracy over the previous approaches. Based on RAFT, a state-of-the-art optical flow model, we design a new decoder to iteratively update 3D motion fields and disparity maps simultaneously. Furthermore, we propose an enhanced upsampling layer and a disparity initialization technique, which overall further improves accuracy up to 7.2%. Our method achieves state-of-the-art accuracy among all self-supervised monocular scene flow methods, improving accuracy by 34.2%. Our fine-tuned model outperforms the best previous semi-supervised method with 228 times faster runtime. Code will be publicly available.
Temporal Continuity Based Unsupervised Learning for Person Re-Identification
Sep 01, 2020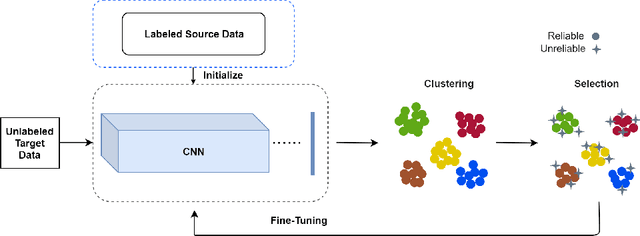
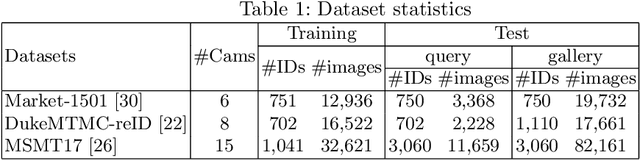

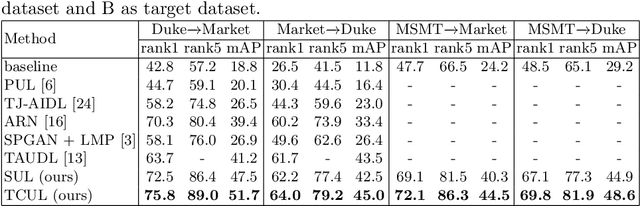
Person re-identification (re-id) aims to match the same person from images taken across multiple cameras. Most existing person re-id methods generally require a large amount of identity labeled data to act as discriminative guideline for representation learning. Difficulty in manually collecting identity labeled data leads to poor adaptability in practical scenarios. To overcome this problem, we propose an unsupervised center-based clustering approach capable of progressively learning and exploiting the underlying re-id discriminative information from temporal continuity within a camera. We call our framework Temporal Continuity based Unsupervised Learning (TCUL). Specifically, TCUL simultaneously does center based clustering of unlabeled (target) dataset and fine-tunes a convolutional neural network (CNN) pre-trained on irrelevant labeled (source) dataset to enhance discriminative capability of the CNN for the target dataset. Furthermore, it exploits temporally continuous nature of images within-camera jointly with spatial similarity of feature maps across-cameras to generate reliable pseudo-labels for training a re-identification model. As the training progresses, number of reliable samples keep on growing adaptively which in turn boosts representation ability of the CNN. Extensive experiments on three large-scale person re-id benchmark datasets are conducted to compare our framework with state-of-the-art techniques, which demonstrate superiority of TCUL over existing methods.
FH-GAN: Face Hallucination and Recognition using Generative Adversarial Network
May 16, 2019
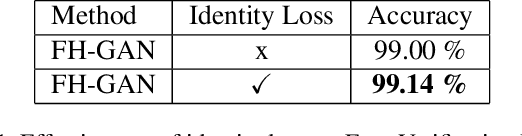
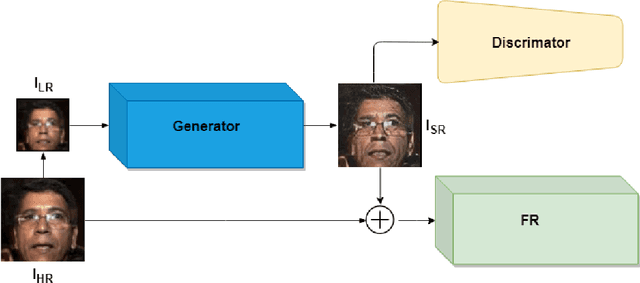
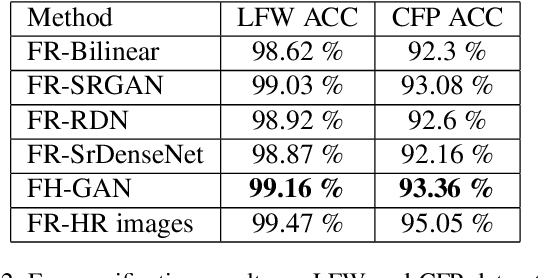
There are many factors affecting visual face recognition, such as low resolution images, aging, illumination and pose variance, etc. One of the most important problem is low resolution face images which can result in bad performance on face recognition. Most of the general face recognition algorithms usually assume a sufficient resolution for the face images. However, in practice many applications often do not have sufficient image resolutions. The modern face hallucination models demonstrate reasonable performance to reconstruct high-resolution images from its corresponding low resolution images. However, they do not consider identity level information during hallucination which directly affects results of the recognition of low resolution faces. To address this issue, we propose a Face Hallucination Generative Adversarial Network (FH-GAN) which improves the quality of low resolution face images and accurately recognize those low quality images. Concretely, we make the following contributions: 1) we propose FH-GAN network, an end-to-end system, that improves both face hallucination and face recognition simultaneously. The novelty of this proposed network depends on incorporating identity information in a GAN-based face hallucination algorithm via combining a face recognition network for identity preserving. 2) We also propose a new face hallucination network, namely Dense Sparse Network (DSNet), which improves upon the state-of-art in face hallucination. 3) We demonstrate benefits of training the face recognition and GAN-based DSNet jointly by reporting good result on face hallucination and recognition.
Spatial Shortcut Network for Human Pose Estimation
Apr 05, 2019
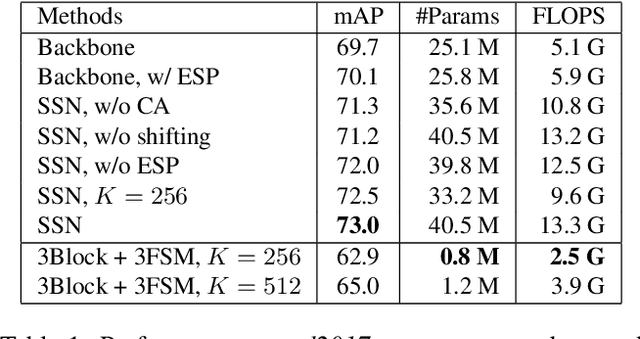
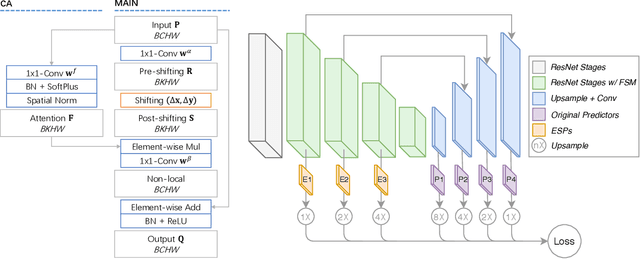

Like many computer vision problems, human pose estimation is a challenging problem in that recognizing a body part requires not only information from local area but also from areas with large spatial distance. In order to spatially pass information, large convolutional kernels and deep layers have been normally used, introducing high computation cost and large parameter space. Luckily for pose estimation, human body is geometrically structured in images, enabling modeling of spatial dependency. In this paper, we propose a spatial shortcut network for pose estimation task, where information is easier to flow spatially. We evaluate our model with detailed analyses and present its outstanding performance with smaller structure.