 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO-4D: Unposed Feedforward 4D Reconstruction from Two Images
Mar 05, 2026Dense 4D reconstruction from unposed images remains a critical challenge, with current methods relying on slow test-time optimization or fragmented, task-specific feedforward models. We introduce UFO-4D, a unified feedforward framework to reconstruct a dense, explicit 4D representation from just a pair of unposed images. UFO-4D directly estimates dynamic 3D Gaussian Splats, enabling the joint and consistent estimation of 3D geometry, 3D motion, and camera pose in a feedforward manner. Our core insight is that differentiably rendering multiple signals from a single Dynamic 3D Gaussian representation offers major training advantages. This approach enables a self-supervised image synthesis loss while tightly coupling appearance, depth, and motion. Since all modalities share the same geometric primitives, supervising one inherently regularizes and improves the others. This synergy overcomes data scarcity, allowing UFO-4D to outperform prior work by up to 3 times in joint geometry, motion, and camera pose estimation. Our representation also enables high-fidelity 4D interpolation across novel views and time. Please visit our project page for visual results: https://ufo-4d.github.io/
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Mar 03, 2026Feedforward geometric foundation models achieve strong short-window reconstruction, yet scaling them to minutes-long videos is bottlenecked by quadratic attention complexity or limited effective memory in recurrent designs. We present LoGeR (Long-context Geometric Reconstruction), a novel architecture that scales dense 3D reconstruction to extremely long sequences without post-optimization. LoGeR processes video streams in chunks, leveraging strong bidirectional priors for high-fidelity intra-chunk reasoning. To manage the critical challenge of coherence across chunk boundaries, we propose a learning-based hybrid memory module. This dual-component system combines a parametric Test-Time Training (TTT) memory to anchor the global coordinate frame and prevent scale drift, alongside a non-parametric Sliding Window Attention (SWA) mechanism to preserve uncompressed context for high-precision adjacent alignment. Remarkably, this memory architecture enables LoGeR to be trained on sequences of 128 frames, and generalize up to thousands of frames during inference. Evaluated across standard benchmarks and a newly repurposed VBR dataset with sequences of up to 19k frames, LoGeR substantially outperforms prior state-of-the-art feedforward methods--reducing ATE on KITTI by over 74%--and achieves robust, globally consistent reconstruction over unprecedented horizons.
GR3EN: Generative Relighting for 3D Environments
Jan 22, 2026We present a method for relighting 3D reconstructions of large room-scale environments. Existing solutions for 3D scene relighting often require solving under-determined or ill-conditioned inverse rendering problems, and are as such unable to produce high-quality results on complex real-world scenes. Though recent progress in using generative image and video diffusion models for relighting has been promising, these techniques are either limited to 2D image and video relighting or 3D relighting of individual objects. Our approach enables controllable 3D relighting of room-scale scenes by distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction. This side-steps the need to solve a difficult inverse rendering problem, and results in a flexible system that can relight 3D reconstructions of complex real-world scenes. We validate our approach on both synthetic and real-world datasets to show that it can faithfully render novel views of scenes under new lighting conditions.
GeCo: A Differentiable Geometric Consistency Metric for Video Generation
Dec 25, 2025We introduce GeCo, a geometry-grounded metric for jointly detecting geometric deformation and occlusion-inconsistency artifacts in static scenes. By fusing residual motion and depth priors, GeCo produces interpretable, dense consistency maps that reveal these artifacts. We use GeCo to systematically benchmark recent video generation models, uncovering common failure modes, and further employ it as a training-free guidance loss to reduce deformation artifacts during video generation.
Repurposing Video Diffusion Transformers for Robust Point Tracking
Dec 23, 2025Point tracking aims to localize corresponding points across video frames, serving as a fundamental task for 4D reconstruction, robotics, and video editing. Existing methods commonly rely on shallow convolutional backbones such as ResNet that process frames independently, lacking temporal coherence and producing unreliable matching costs under challenging conditions. Through systematic analysis, we find that video Diffusion Transformers (DiTs), pre-trained on large-scale real-world videos with spatio-temporal attention, inherently exhibit strong point tracking capability and robustly handle dynamic motions and frequent occlusions. We propose DiTracker, which adapts video DiTs through: (1) query-key attention matching, (2) lightweight LoRA tuning, and (3) cost fusion with a ResNet backbone. Despite training with 8 times smaller batch size, DiTracker achieves state-of-the-art performance on challenging ITTO benchmark and matches or outperforms state-of-the-art models on TAP-Vid benchmarks. Our work validates video DiT features as an effective and efficient foundation for point tracking.
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Oct 04, 2024



Estimating geometry from dynamic scenes, where objects move and deform over time, remains a core challenge in computer vision. Current approaches often rely on multi-stage pipelines or global optimizations that decompose the problem into subtasks, like depth and flow, leading to complex systems prone to errors. In this paper, we present Motion DUSt3R (MonST3R), a novel geometry-first approach that directly estimates per-timestep geometry from dynamic scenes. Our key insight is that by simply estimating a pointmap for each timestep, we can effectively adapt DUST3R's representation, previously only used for static scenes, to dynamic scenes. However, this approach presents a significant challenge: the scarcity of suitable training data, namely dynamic, posed videos with depth labels. Despite this, we show that by posing the problem as a fine-tuning task, identifying several suitable datasets, and strategically training the model on this limited data, we can surprisingly enable the model to handle dynamics, even without an explicit motion representation. Based on this, we introduce new optimizations for several downstream video-specific tasks and demonstrate strong performance on video depth and camera pose estimation, outperforming prior work in terms of robustness and efficiency. Moreover, MonST3R shows promising results for primarily feed-forward 4D reconstruction.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Boundary Attention: Learning to Find Faint Boundaries at Any Resolution
Jan 01, 2024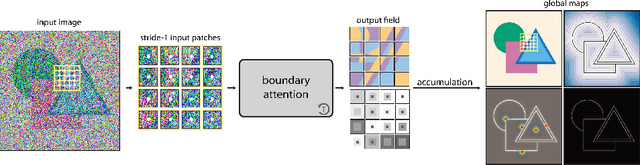
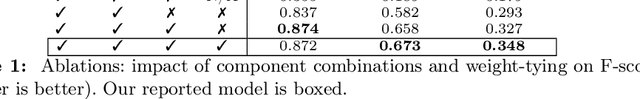
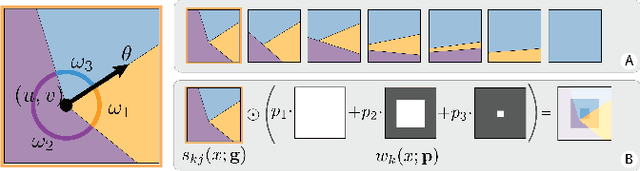
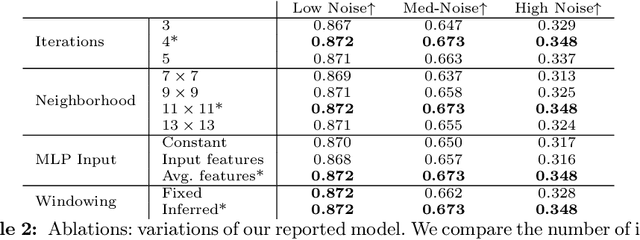
We present a differentiable model that explicitly models boundaries -- including contours, corners and junctions -- using a new mechanism that we call boundary attention. We show that our model provides accurate results even when the boundary signal is very weak or is swamped by noise. Compared to previous classical methods for finding faint boundaries, our model has the advantages of being differentiable; being scalable to larger images; and automatically adapting to an appropriate level of geometric detail in each part of an image. Compared to previous deep methods for finding boundaries via end-to-end training, it has the advantages of providing sub-pixel precision, being more resilient to noise, and being able to process any image at its native resolution and aspect ratio.