 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Dec 17, 2025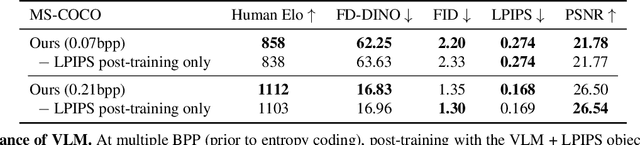

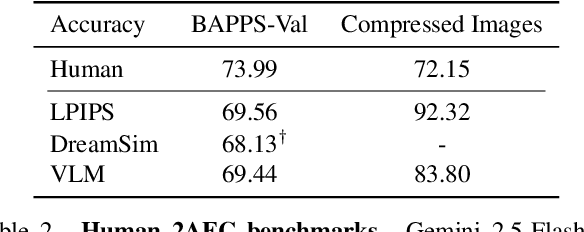
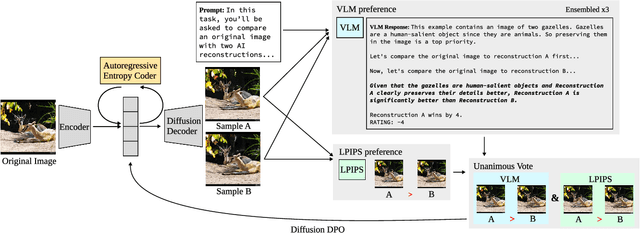
Evaluations of image compression performance which include human preferences have generally found that naive distortion functions such as MSE are insufficiently aligned to human perception. In order to align compression models to human perception, prior work has employed differentiable perceptual losses consisting of neural networks calibrated on large-scale datasets of human psycho-visual judgments. We show that, surprisingly, state-of-the-art vision-language models (VLMs) can replicate binary human two-alternative forced choice (2AFC) judgments zero-shot when asked to reason about the differences between pairs of images. Motivated to exploit the powerful zero-shot visual reasoning capabilities of VLMs, we propose Vision-Language Models for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments. VLIC leverages existing techniques for diffusion model post-training with preferences, rather than distilling the VLM judgments into a separate perceptual loss network. We show that calibrating this system on VLM judgments produces competitive or state-of-the-art performance on human-aligned visual compression depending on the dataset, according to perceptual metrics and large-scale user studies. We additionally conduct an extensive analysis of the VLM-based reward design and training procedure and share important insights. More visuals are available at https://kylesargent.github.io/vlic
Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
Mar 14, 2025Since the advent of popular visual generation frameworks like VQGAN and latent diffusion models, state-of-the-art image generation systems have generally been two-stage systems that first tokenize or compress visual data into a lower-dimensional latent space before learning a generative model. Tokenizer training typically follows a standard recipe in which images are compressed and reconstructed subject to a combination of MSE, perceptual, and adversarial losses. Diffusion autoencoders have been proposed in prior work as a way to learn end-to-end perceptually-oriented image compression, but have not yet shown state-of-the-art performance on the competitive task of ImageNet-1K reconstruction. We propose FlowMo, a transformer-based diffusion autoencoder that achieves a new state-of-the-art for image tokenization at multiple compression rates without using convolutions, adversarial losses, spatially-aligned two-dimensional latent codes, or distilling from other tokenizers. Our key insight is that FlowMo training should be broken into a mode-matching pre-training stage and a mode-seeking post-training stage. In addition, we conduct extensive analyses and explore the training of generative models atop the FlowMo tokenizer. Our code and models will be available at http://kylesargent.github.io/flowmo .
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Sep 05, 2024Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
May 23, 2024



Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose $\textbf{GCD}$, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
WonderJourney: Going from Anywhere to Everywhere
Dec 06, 2023



We introduce WonderJourney, a modularized framework for perpetual 3D scene generation. Unlike prior work on view generation that focuses on a single type of scenes, we start at any user-provided location (by a text description or an image) and generate a journey through a long sequence of diverse yet coherently connected 3D scenes. We leverage an LLM to generate textual descriptions of the scenes in this journey, a text-driven point cloud generation pipeline to make a compelling and coherent sequence of 3D scenes, and a large VLM to verify the generated scenes. We show compelling, diverse visual results across various scene types and styles, forming imaginary "wonderjourneys". Project website: https://kovenyu.com/WonderJourney/
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023

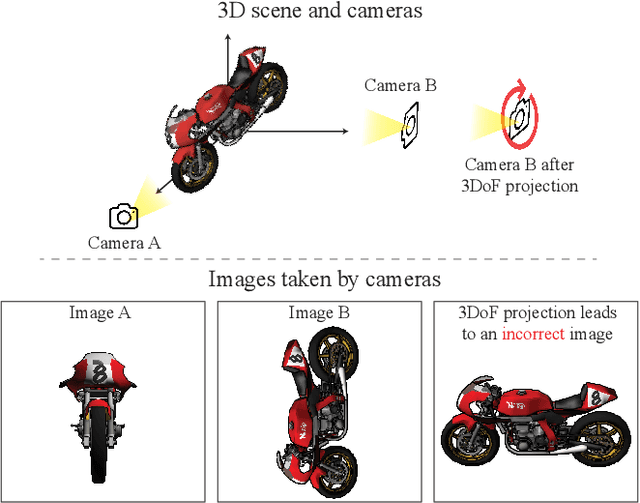

We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
Feb 14, 2023


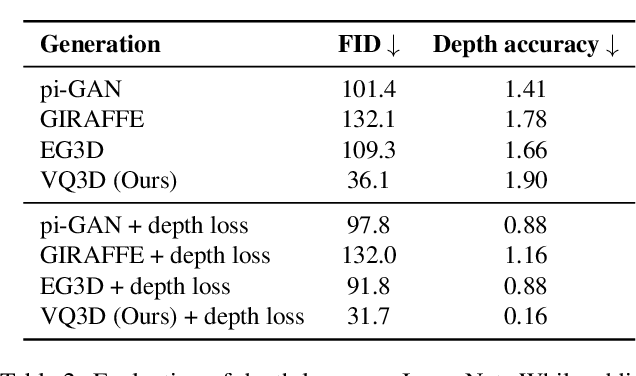
Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.
Self-supervised AutoFlow
Dec 08, 2022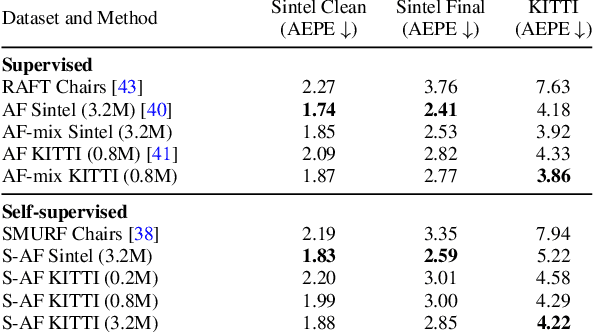
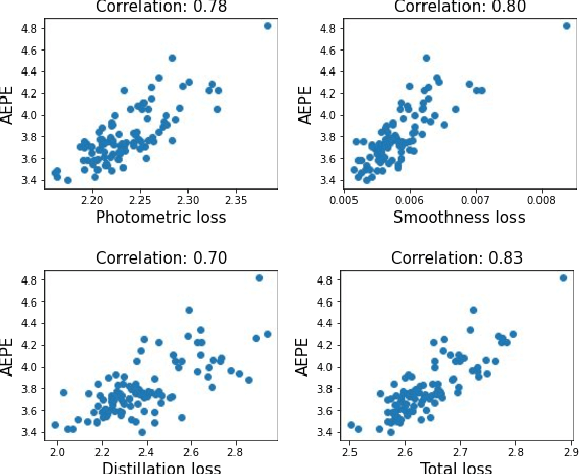

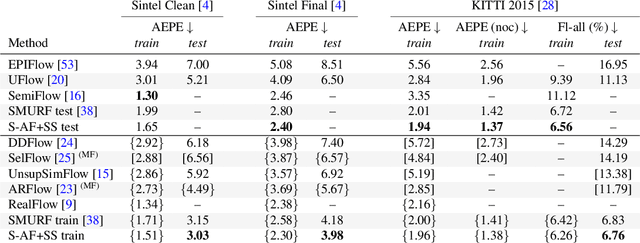
Recently, AutoFlow has shown promising results on learning a training set for optical flow, but requires ground truth labels in the target domain to compute its search metric. Observing a strong correlation between the ground truth search metric and self-supervised losses, we introduce self-supervised AutoFlow to handle real-world videos without ground truth labels. Using self-supervised loss as the search metric, our self-supervised AutoFlow performs on par with AutoFlow on Sintel and KITTI where ground truth is available, and performs better on the real-world DAVIS dataset. We further explore using self-supervised AutoFlow in the (semi-)supervised setting and obtain competitive results against the state of the art.
Pyramid Adversarial Training Improves ViT Performance
Nov 30, 2021



Aggressive data augmentation is a key component of the strong generalization capabilities of Vision Transformer (ViT). One such data augmentation technique is adversarial training; however, many prior works have shown that this often results in poor clean accuracy. In this work, we present Pyramid Adversarial Training, a simple and effective technique to improve ViT's overall performance. We pair it with a "matched" Dropout and stochastic depth regularization, which adopts the same Dropout and stochastic depth configuration for the clean and adversarial samples. Similar to the improvements on CNNs by AdvProp (not directly applicable to ViT), our Pyramid Adversarial Training breaks the trade-off between in-distribution accuracy and out-of-distribution robustness for ViT and related architectures. It leads to $1.82\%$ absolute improvement on ImageNet clean accuracy for the ViT-B model when trained only on ImageNet-1K data, while simultaneously boosting performance on $7$ ImageNet robustness metrics, by absolute numbers ranging from $1.76\%$ to $11.45\%$. We set a new state-of-the-art for ImageNet-C (41.4 mCE), ImageNet-R ($53.92\%$), and ImageNet-Sketch ($41.04\%$) without extra data, using only the ViT-B/16 backbone and our Pyramid Adversarial Training. Our code will be publicly available upon acceptance.