 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA Foundry: A Unified Framework for Training Vision-Language-Action Models
Apr 21, 2026We present VLA Foundry, an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. Most open-source VLA efforts specialize on the action training stage, often stitching together incompatible pretraining pipelines. VLA Foundry instead provides a shared training stack with end-to-end control, from language pretraining to action-expert fine-tuning. VLA Foundry supports both from-scratch training and pretrained backbones from Hugging Face. To demonstrate the utility of our framework, we train and release two types of models: the first trained fully from scratch through our LLM-->VLM-->VLA pipeline and the second built on the pretrained Qwen3-VL backbone. We evaluate closed-loop policy performance of both models on LBM Eval, an open-data, open-source simulator. We also contribute usability improvements to the simulator and the STEP analysis tools for easier public use. In the nominal evaluation setting, our fully-open from-scratch model is on par with our prior closed-source work and substituting in the Qwen3-VL backbone leads to a strong multi-task table top manipulation policy outperforming our baseline by a wide margin. The VLA Foundry codebase is available at https://github.com/TRI-ML/vla_foundry and all multi-task model weights are released on https://huggingface.co/collections/TRI-ML/vla-foundry. Additional qualitative videos are available on the project website https://tri-ml.github.io/vla_foundry.
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025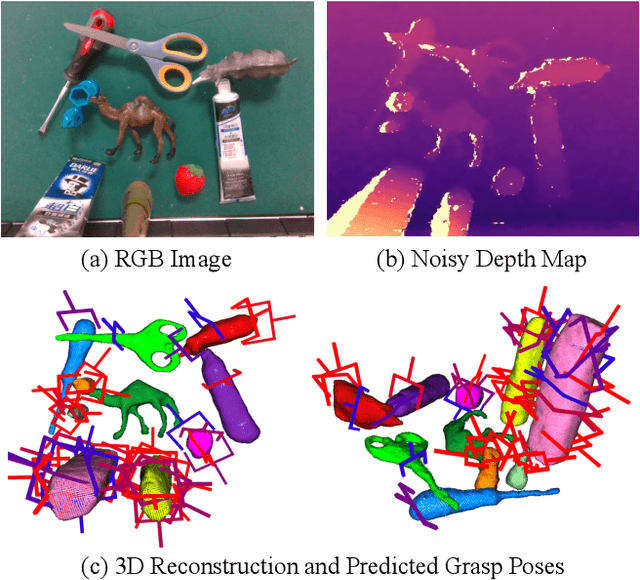
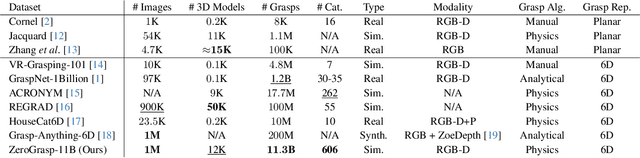
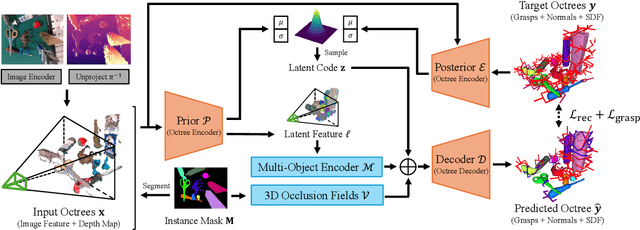
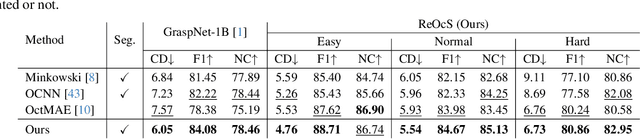
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
$SE(3)$ Equivariant Ray Embeddings for Implicit Multi-View Depth Estimation
Nov 11, 2024Incorporating inductive bias by embedding geometric entities (such as rays) as input has proven successful in multi-view learning. However, the methods adopting this technique typically lack equivariance, which is crucial for effective 3D learning. Equivariance serves as a valuable inductive prior, aiding in the generation of robust multi-view features for 3D scene understanding. In this paper, we explore the application of equivariant multi-view learning to depth estimation, not only recognizing its significance for computer vision and robotics but also addressing the limitations of previous research. Most prior studies have either overlooked equivariance in this setting or achieved only approximate equivariance through data augmentation, which often leads to inconsistencies across different reference frames. To address this issue, we propose to embed $SE(3)$ equivariance into the Perceiver IO architecture. We employ Spherical Harmonics for positional encoding to ensure 3D rotation equivariance, and develop a specialized equivariant encoder and decoder within the Perceiver IO architecture. To validate our model, we applied it to the task of stereo depth estimation, achieving state of the art results on real-world datasets without explicit geometric constraints or extensive data augmentation.
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Sep 05, 2024Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
ReFiNe: Recursive Field Networks for Cross-modal Multi-scene Representation
Jun 06, 2024



The common trade-offs of state-of-the-art methods for multi-shape representation (a single model "packing" multiple objects) involve trading modeling accuracy against memory and storage. We show how to encode multiple shapes represented as continuous neural fields with a higher degree of precision than previously possible and with low memory usage. Key to our approach is a recursive hierarchical formulation that exploits object self-similarity, leading to a highly compressed and efficient shape latent space. Thanks to the recursive formulation, our method supports spatial and global-to-local latent feature fusion without needing to initialize and maintain auxiliary data structures, while still allowing for continuous field queries to enable applications such as raytracing. In experiments on a set of diverse datasets, we provide compelling qualitative results and demonstrate state-of-the-art multi-scene reconstruction and compression results with a single network per dataset.
Zero-Shot Multi-Object Shape Completion
Mar 21, 2024We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a na\"ive 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability.
DiffusionNOCS: Managing Symmetry and Uncertainty in Sim2Real Multi-Modal Category-level Pose Estimation
Feb 20, 2024



This paper addresses the challenging problem of category-level pose estimation. Current state-of-the-art methods for this task face challenges when dealing with symmetric objects and when attempting to generalize to new environments solely through synthetic data training. In this work, we address these challenges by proposing a probabilistic model that relies on diffusion to estimate dense canonical maps crucial for recovering partial object shapes as well as establishing correspondences essential for pose estimation. Furthermore, we introduce critical components to enhance performance by leveraging the strength of the diffusion models with multi-modal input representations. We demonstrate the effectiveness of our method by testing it on a range of real datasets. Despite being trained solely on our generated synthetic data, our approach achieves state-of-the-art performance and unprecedented generalization qualities, outperforming baselines, even those specifically trained on the target domain.
NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
Aug 24, 2023Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360{\deg} scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird's-eye-view (BEV) representations and is more effective and expressive than each. NeO 360's representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360{\deg} unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page: https://zubair-irshad.github.io/projects/neo360.html
Multi-Object Manipulation via Object-Centric Neural Scattering Functions
Jun 14, 2023Learned visual dynamics models have proven effective for robotic manipulation tasks. Yet, it remains unclear how best to represent scenes involving multi-object interactions. Current methods decompose a scene into discrete objects, but they struggle with precise modeling and manipulation amid challenging lighting conditions as they only encode appearance tied with specific illuminations. In this work, we propose using object-centric neural scattering functions (OSFs) as object representations in a model-predictive control framework. OSFs model per-object light transport, enabling compositional scene re-rendering under object rearrangement and varying lighting conditions. By combining this approach with inverse parameter estimation and graph-based neural dynamics models, we demonstrate improved model-predictive control performance and generalization in compositional multi-object environments, even in previously unseen scenarios and harsh lighting conditions.
CARTO: Category and Joint Agnostic Reconstruction of ARTiculated Objects
Mar 28, 2023



We present CARTO, a novel approach for reconstructing multiple articulated objects from a single stereo RGB observation. We use implicit object-centric representations and learn a single geometry and articulation decoder for multiple object categories. Despite training on multiple categories, our decoder achieves a comparable reconstruction accuracy to methods that train bespoke decoders separately for each category. Combined with our stereo image encoder we infer the 3D shape, 6D pose, size, joint type, and the joint state of multiple unknown objects in a single forward pass. Our method achieves a 20.4% absolute improvement in mAP 3D IOU50 for novel instances when compared to a two-stage pipeline. Inference time is fast and can run on a NVIDIA TITAN XP GPU at 1 HZ for eight or less objects present. While only trained on simulated data, CARTO transfers to real-world object instances. Code and evaluation data is available at: http://carto.cs.uni-freiburg.de