 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR: Gaussian Splatting Tracking and Reconstruction of Unknown Objects Based on Appearance and Geometric Complexity
May 17, 2025We present a novel method for 6-DoF object tracking and high-quality 3D reconstruction from monocular RGBD video. Existing methods, while achieving impressive results, often struggle with complex objects, particularly those exhibiting symmetry, intricate geometry or complex appearance. To bridge these gaps, we introduce an adaptive method that combines 3D Gaussian Splatting, hybrid geometry/appearance tracking, and key frame selection to achieve robust tracking and accurate reconstructions across a diverse range of objects. Additionally, we present a benchmark covering these challenging object classes, providing high-quality annotations for evaluating both tracking and reconstruction performance. Our approach demonstrates strong capabilities in recovering high-fidelity object meshes, setting a new standard for single-sensor 3D reconstruction in open-world environments.
Simultaneous Pick and Place Detection by Combining SE(3) Diffusion Models with Differential Kinematics
Apr 28, 2025Grasp detection methods typically target the detection of a set of free-floating hand poses that can grasp the object. However, not all of the detected grasp poses are executable due to physical constraints. Even though it is straightforward to filter invalid grasp poses in the post-process, such a two-staged approach is computationally inefficient, especially when the constraint is hard. In this work, we propose an approach to take the following two constraints into account during the grasp detection stage, namely, (i) the picked object must be able to be placed with a predefined configuration without in-hand manipulation (ii) it must be reachable by the robot under the joint limit and collision-avoidance constraints for both pick and place cases. Our key idea is to train an SE(3) grasp diffusion network to estimate the noise in the form of spatial velocity, and constrain the denoising process by a multi-target differential inverse kinematics with an inequality constraint, so that the states are guaranteed to be reachable and placement can be performed without collision. In addition to an improved success ratio, we experimentally confirmed that our approach is more efficient and consistent in computation time compared to a naive two-stage approach.
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025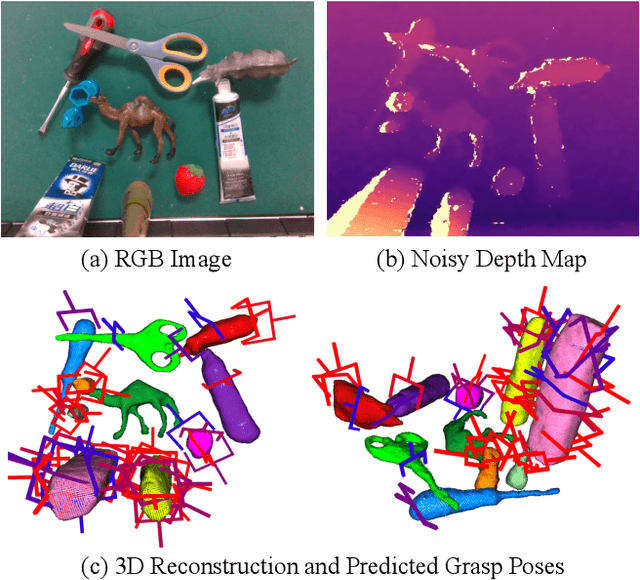
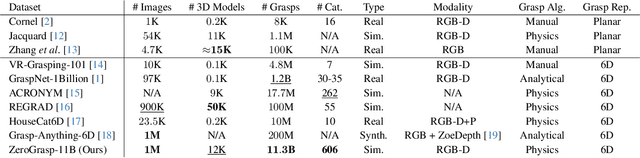
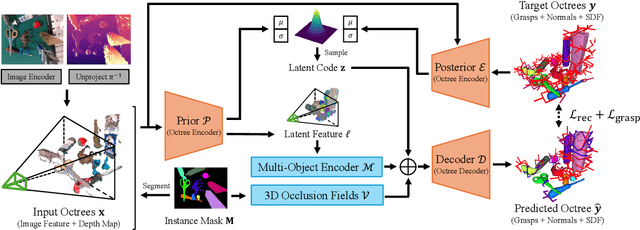
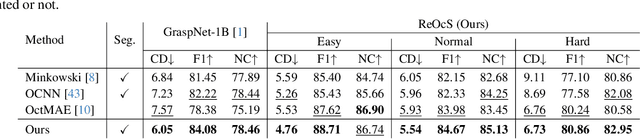
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
A Planar-Symmetric SO(3) Representation for Learning Grasp Detection
Oct 07, 2024Planar-symmetric hands, such as parallel grippers, are widely adopted in both research and industrial fields. Their symmetry, however, introduces ambiguity and discontinuity in the SO(3) representation, which hinders both the training and inference of neural-network-based grasp detectors. We propose a novel SO(3) representation that can parametrize a pair of planar-symmetric poses with a single parameter set by leveraging the 2D Bingham distribution. We also detail a grasp detector based on our representation, which provides a more consistent rotation output. An intensive evaluation with multiple grippers and objects in both the simulation and the real world quantitatively shows our approach's contribution.
ViFu: Multiple 360$^\circ$ Objects Reconstruction with Clean Background via Visible Part Fusion
Apr 15, 2024



In this paper, we propose a method to segment and recover a static, clean background and multiple 360$^\circ$ objects from observations of scenes at different timestamps. Recent works have used neural radiance fields to model 3D scenes and improved the quality of novel view synthesis, while few studies have focused on modeling the invisible or occluded parts of the training images. These under-reconstruction parts constrain both scene editing and rendering view selection, thereby limiting their utility for synthetic data generation for downstream tasks. Our basic idea is that, by observing the same set of objects in various arrangement, so that parts that are invisible in one scene may become visible in others. By fusing the visible parts from each scene, occlusion-free rendering of both background and foreground objects can be achieved. We decompose the multi-scene fusion task into two main components: (1) objects/background segmentation and alignment, where we leverage point cloud-based methods tailored to our novel problem formulation; (2) radiance fields fusion, where we introduce visibility field to quantify the visible information of radiance fields, and propose visibility-aware rendering for the fusion of series of scenes, ultimately obtaining clean background and 360$^\circ$ object rendering. Comprehensive experiments were conducted on synthetic and real datasets, and the results demonstrate the effectiveness of our method.
DiffusionNOCS: Managing Symmetry and Uncertainty in Sim2Real Multi-Modal Category-level Pose Estimation
Feb 20, 2024



This paper addresses the challenging problem of category-level pose estimation. Current state-of-the-art methods for this task face challenges when dealing with symmetric objects and when attempting to generalize to new environments solely through synthetic data training. In this work, we address these challenges by proposing a probabilistic model that relies on diffusion to estimate dense canonical maps crucial for recovering partial object shapes as well as establishing correspondences essential for pose estimation. Furthermore, we introduce critical components to enhance performance by leveraging the strength of the diffusion models with multi-modal input representations. We demonstrate the effectiveness of our method by testing it on a range of real datasets. Despite being trained solely on our generated synthetic data, our approach achieves state-of-the-art performance and unprecedented generalization qualities, outperforming baselines, even those specifically trained on the target domain.
Gravity-aware Grasp Generation with Implicit Grasp Mode Selection for Underactuated Hands
Dec 19, 2023
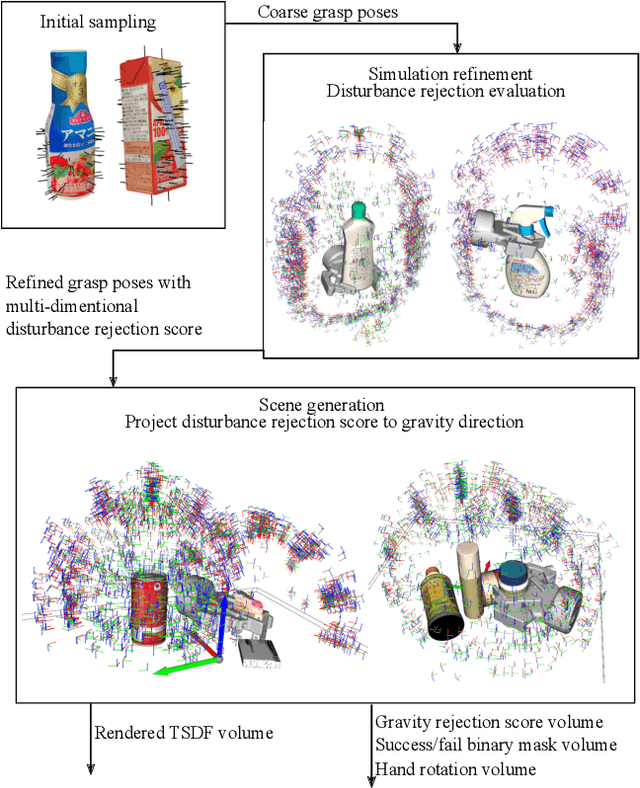
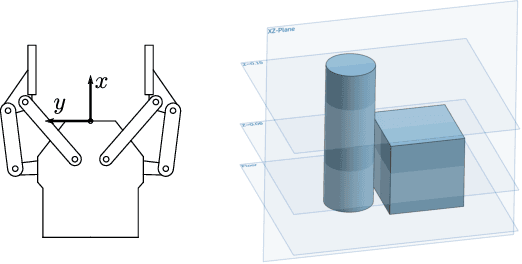
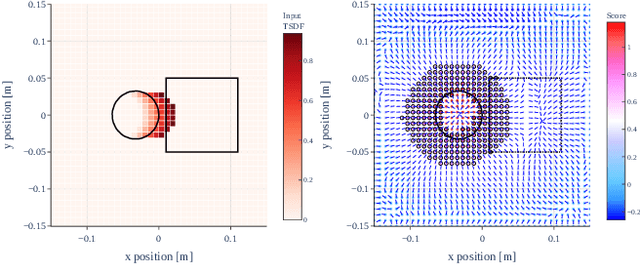
To overcome the mechanical limitation of parallel-jaw grippers, in this paper, we present a gravity-aware grasp generation that supports both precision grasp and power grasp of underactuated hands. We propose a novel approach to generate a large-scale dataset with a gravity-rejection score and experimentally confirm that the combination of that score and classical success/fail binary classification is powerful: the former encourages stable grasps, such as power grasps or grasping the center of mass, while the latter rejects invalid grasps, such as colliding with other objects or attempting to grasp parts that are too large for the gripper. We also propose a rotation representation that is continuous on SO(3) and considers the grasp's physical meaning. Our simulation and real robot evaluation experiments demonstrate significant improvements from the baseline works, especially for heavy objects.
GS-Pose: Category-Level Object Pose Estimation via Geometric and Semantic Correspondence
Nov 23, 2023



Category-level pose estimation is a challenging task with many potential applications in computer vision and robotics. Recently, deep-learning-based approaches have made great progress, but are typically hindered by the need for large datasets of either pose-labelled real images or carefully tuned photorealistic simulators. This can be avoided by using only geometry inputs such as depth images to reduce the domain-gap but these approaches suffer from a lack of semantic information, which can be vital in the pose estimation problem. To resolve this conflict, we propose to utilize both geometric and semantic features obtained from a pre-trained foundation model.Our approach projects 2D features from this foundation model into 3D for a single object model per category, and then performs matching against this for new single view observations of unseen object instances with a trained matching network. This requires significantly less data to train than prior methods since the semantic features are robust to object texture and appearance. We demonstrate this with a rich evaluation, showing improved performance over prior methods with a fraction of the data required.
A Probabilistic Rotation Representation for Symmetric Shapes With an Efficiently Computable Bingham Loss Function
May 30, 2023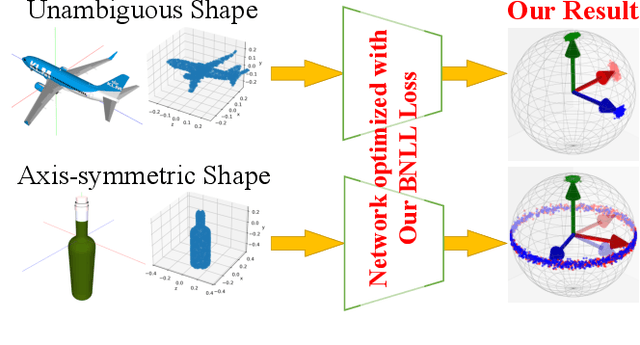



In recent years, a deep learning framework has been widely used for object pose estimation. While quaternion is a common choice for rotation representation, it cannot represent the ambiguity of the observation. In order to handle the ambiguity, the Bingham distribution is one promising solution. However, it requires complicated calculation when yielding the negative log-likelihood (NLL) loss. An alternative easy-to-implement loss function has been proposed to avoid complex computations but has difficulty expressing symmetric distribution. In this paper, we introduce a fast-computable and easy-to-implement NLL loss function for Bingham distribution. We also create the inference network and show that our loss function can capture the symmetric property of target objects from their point clouds.
Development of a Stereo-Vision Based High-Throughput Robotic System for Mouse Tail Vein Injection
May 25, 2022
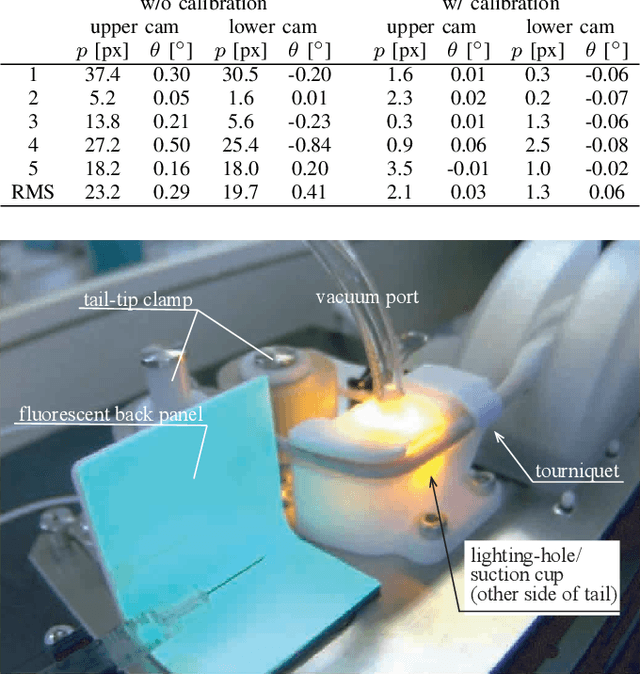


In this paper, we present a robotic device for mouse tail vein injection. We propose a mouse holding mechanism to realize vein injection without anesthetizing the mouse, which consists of a tourniquet, vacuum port, and adaptive tail-end fixture. The position of the target vein in 3D space is reconstructed from a high-resolution stereo vision. The vein is detected by a simple but robust vein line detector. Thanks to the proposed two-staged calibration process, the total time for the injection process is limited to 1.5 minutes, despite that the position of needle and tail vein varies for each trial. We performed an injection experiment targeting 40 mice and succeeded to inject saline to 37 of them, resulting 92.5% success ratio.