 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Harness for Governable Medical AI Skill Ecosystems
Jun 25, 2026Medical AI remains organized around isolated models, whereas clinical care requires accountable capabilities that persist across time. We propose clinical AI skills and the Clinical Harness: a runtime governance architecture for registering, orchestrating, guarding and monitoring AI-enabled clinical capabilities. Using osteoporosis as an exemplar, we show how knowledge-driven, data-driven and physics-enhanced skills can support lifecycle care under runtime governance.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
HiMoR: Monocular Deformable Gaussian Reconstruction with Hierarchical Motion Representation
Apr 08, 2025We present Hierarchical Motion Representation (HiMoR), a novel deformation representation for 3D Gaussian primitives capable of achieving high-quality monocular dynamic 3D reconstruction. The insight behind HiMoR is that motions in everyday scenes can be decomposed into coarser motions that serve as the foundation for finer details. Using a tree structure, HiMoR's nodes represent different levels of motion detail, with shallower nodes modeling coarse motion for temporal smoothness and deeper nodes capturing finer motion. Additionally, our model uses a few shared motion bases to represent motions of different sets of nodes, aligning with the assumption that motion tends to be smooth and simple. This motion representation design provides Gaussians with a more structured deformation, maximizing the use of temporal relationships to tackle the challenging task of monocular dynamic 3D reconstruction. We also propose using a more reliable perceptual metric as an alternative, given that pixel-level metrics for evaluating monocular dynamic 3D reconstruction can sometimes fail to accurately reflect the true quality of reconstruction. Extensive experiments demonstrate our method's efficacy in achieving superior novel view synthesis from challenging monocular videos with complex motions.
Rethinking Directional Parameterization in Neural Implicit Surface Reconstruction
Sep 11, 2024



Multi-view 3D surface reconstruction using neural implicit representations has made notable progress by modeling the geometry and view-dependent radiance fields within a unified framework. However, their effectiveness in reconstructing objects with specular or complex surfaces is typically biased by the directional parameterization used in their view-dependent radiance network. {\it Viewing direction} and {\it reflection direction} are the two most commonly used directional parameterizations but have their own limitations. Typically, utilizing the viewing direction usually struggles to correctly decouple the geometry and appearance of objects with highly specular surfaces, while using the reflection direction tends to yield overly smooth reconstructions for concave or complex structures. In this paper, we analyze their failed cases in detail and propose a novel hybrid directional parameterization to address their limitations in a unified form. Extensive experiments demonstrate the proposed hybrid directional parameterization consistently delivered satisfactory results in reconstructing objects with a wide variety of materials, geometry and appearance, whereas using other directional parameterizations faces challenges in reconstructing certain objects. Moreover, the proposed hybrid directional parameterization is nearly parameter-free and can be effortlessly applied in any existing neural surface reconstruction method.
ViFu: Multiple 360$^\circ$ Objects Reconstruction with Clean Background via Visible Part Fusion
Apr 15, 2024



In this paper, we propose a method to segment and recover a static, clean background and multiple 360$^\circ$ objects from observations of scenes at different timestamps. Recent works have used neural radiance fields to model 3D scenes and improved the quality of novel view synthesis, while few studies have focused on modeling the invisible or occluded parts of the training images. These under-reconstruction parts constrain both scene editing and rendering view selection, thereby limiting their utility for synthetic data generation for downstream tasks. Our basic idea is that, by observing the same set of objects in various arrangement, so that parts that are invisible in one scene may become visible in others. By fusing the visible parts from each scene, occlusion-free rendering of both background and foreground objects can be achieved. We decompose the multi-scene fusion task into two main components: (1) objects/background segmentation and alignment, where we leverage point cloud-based methods tailored to our novel problem formulation; (2) radiance fields fusion, where we introduce visibility field to quantify the visible information of radiance fields, and propose visibility-aware rendering for the fusion of series of scenes, ultimately obtaining clean background and 360$^\circ$ object rendering. Comprehensive experiments were conducted on synthetic and real datasets, and the results demonstrate the effectiveness of our method.
SA-MDKIF: A Scalable and Adaptable Medical Domain Knowledge Injection Framework for Large Language Models
Feb 01, 2024Recent advances in large language models (LLMs) have demonstrated exceptional performance in various natural language processing (NLP) tasks. However, their effective application in the medical domain is hampered by a lack of medical domain knowledge. In this study, we present SA-MDKIF, a scalable and adaptable framework that aims to inject medical knowledge into general-purpose LLMs through instruction tuning, thereby enabling adaptability for various downstream tasks. SA-MDKIF consists of two stages: skill training and skill adaptation. In the first stage, we define 12 basic medical skills and use AdaLoRA to train these skills based on uniformly formatted instructional datasets that we have constructed. In the next stage, we train the skill router using task-specific downstream data and use this router to integrate the acquired skills with LLMs during inference. Experimental results on 9 different medical tasks show that SA-MDKIF improves performance by 10-20% compared to the original LLMs. Notably, this improvement is particularly pronounced for unseen medical tasks, showing an improvement of up to 30%.
Deforming Radiance Fields with Cages
Jul 25, 2022
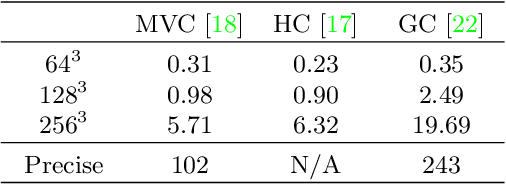
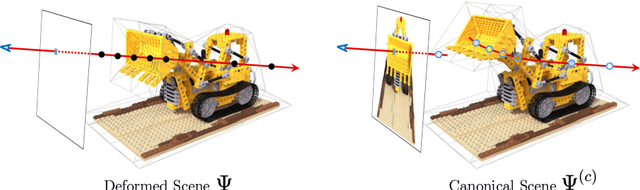

Recent advances in radiance fields enable photorealistic rendering of static or dynamic 3D scenes, but still do not support explicit deformation that is used for scene manipulation or animation. In this paper, we propose a method that enables a new type of deformation of the radiance field: free-form radiance field deformation. We use a triangular mesh that encloses the foreground object called cage as an interface, and by manipulating the cage vertices, our approach enables the free-form deformation of the radiance field. The core of our approach is cage-based deformation which is commonly used in mesh deformation. We propose a novel formulation to extend it to the radiance field, which maps the position and the view direction of the sampling points from the deformed space to the canonical space, thus enabling the rendering of the deformed scene. The deformation results of the synthetic datasets and the real-world datasets demonstrate the effectiveness of our approach.
Surface-Aligned Neural Radiance Fields for Controllable 3D Human Synthesis
Jan 05, 2022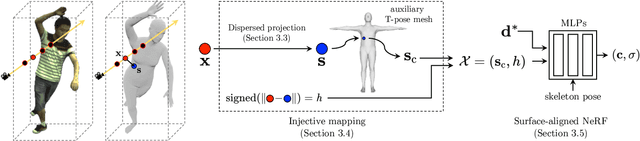
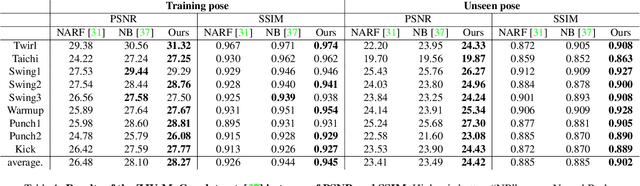
We propose a new method for reconstructing controllable implicit 3D human models from sparse multi-view RGB videos. Our method defines the neural scene representation on the mesh surface points and signed distances from the surface of a human body mesh. We identify an indistinguishability issue that arises when a point in 3D space is mapped to its nearest surface point on a mesh for learning surface-aligned neural scene representation. To address this issue, we propose projecting a point onto a mesh surface using a barycentric interpolation with modified vertex normals. Experiments with the ZJU-MoCap and Human3.6M datasets show that our approach achieves a higher quality in a novel-view and novel-pose synthesis than existing methods. We also demonstrate that our method easily supports the control of body shape and clothes.
Graph Stacked Hourglass Networks for 3D Human Pose Estimation
Mar 30, 2021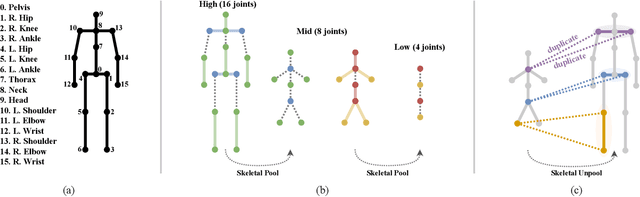
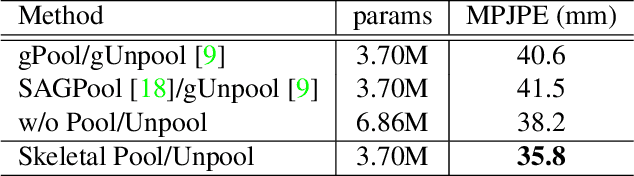
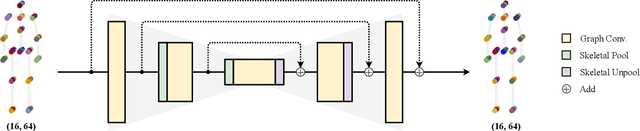
In this paper, we propose a novel graph convolutional network architecture, Graph Stacked Hourglass Networks, for 2D-to-3D human pose estimation tasks. The proposed architecture consists of repeated encoder-decoder, in which graph-structured features are processed across three different scales of human skeletal representations. This multi-scale architecture enables the model to learn both local and global feature representations, which are critical for 3D human pose estimation. We also introduce a multi-level feature learning approach using different-depth intermediate features and show the performance improvements that result from exploiting multi-scale, multi-level feature representations. Extensive experiments are conducted to validate our approach, and the results show that our model outperforms the state-of-the-art.