 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Directional Parameterization in Neural Implicit Surface Reconstruction
Sep 11, 2024



Multi-view 3D surface reconstruction using neural implicit representations has made notable progress by modeling the geometry and view-dependent radiance fields within a unified framework. However, their effectiveness in reconstructing objects with specular or complex surfaces is typically biased by the directional parameterization used in their view-dependent radiance network. {\it Viewing direction} and {\it reflection direction} are the two most commonly used directional parameterizations but have their own limitations. Typically, utilizing the viewing direction usually struggles to correctly decouple the geometry and appearance of objects with highly specular surfaces, while using the reflection direction tends to yield overly smooth reconstructions for concave or complex structures. In this paper, we analyze their failed cases in detail and propose a novel hybrid directional parameterization to address their limitations in a unified form. Extensive experiments demonstrate the proposed hybrid directional parameterization consistently delivered satisfactory results in reconstructing objects with a wide variety of materials, geometry and appearance, whereas using other directional parameterizations faces challenges in reconstructing certain objects. Moreover, the proposed hybrid directional parameterization is nearly parameter-free and can be effortlessly applied in any existing neural surface reconstruction method.
Multi-View Neural Surface Reconstruction with Structured Light
Nov 22, 2022



Three-dimensional (3D) object reconstruction based on differentiable rendering (DR) is an active research topic in computer vision. DR-based methods minimize the difference between the rendered and target images by optimizing both the shape and appearance and realizing a high visual reproductivity. However, most approaches perform poorly for textureless objects because of the geometrical ambiguity, which means that multiple shapes can have the same rendered result in such objects. To overcome this problem, we introduce active sensing with structured light (SL) into multi-view 3D object reconstruction based on DR to learn the unknown geometry and appearance of arbitrary scenes and camera poses. More specifically, our framework leverages the correspondences between pixels in different views calculated by structured light as an additional constraint in the DR-based optimization of implicit surface, color representations, and camera poses. Because camera poses can be optimized simultaneously, our method realizes high reconstruction accuracy in the textureless region and reduces efforts for camera pose calibration, which is required for conventional SL-based methods. Experiment results on both synthetic and real data demonstrate that our system outperforms conventional DR- and SL-based methods in a high-quality surface reconstruction, particularly for challenging objects with textureless or shiny surfaces.
Monocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

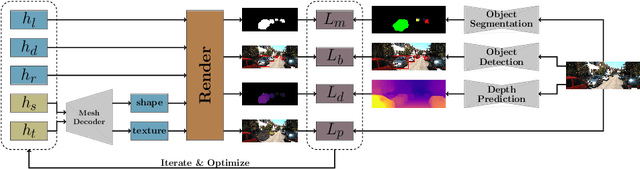
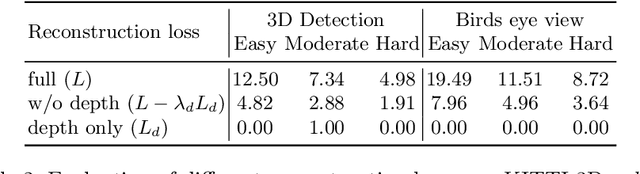
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.
Differentiable Rendering: A Survey
Jun 22, 2020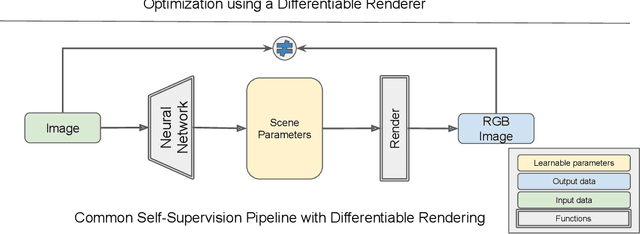
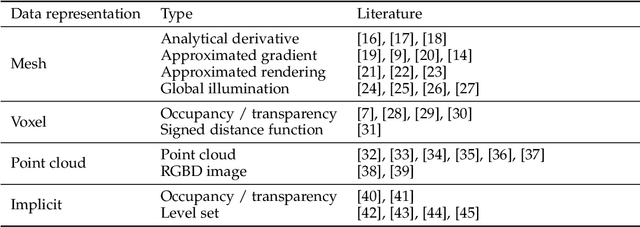
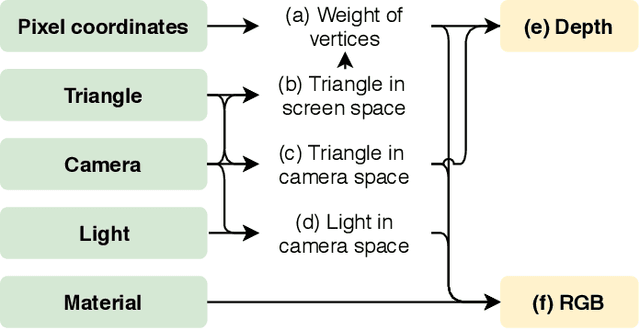

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.
Self-supervised Learning of 3D Objects from Natural Images
Nov 20, 2019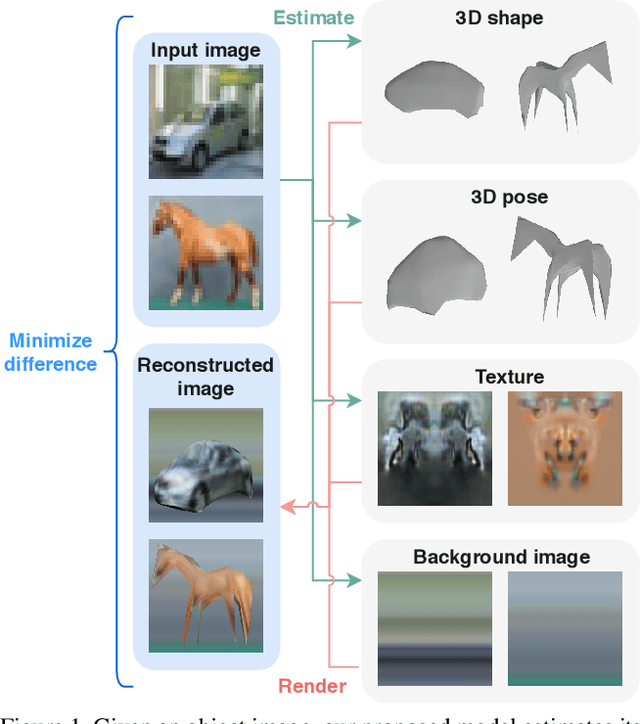



We present a method to learn single-view reconstruction of the 3D shape, pose, and texture of objects from categorized natural images in a self-supervised manner. Since this is a severely ill-posed problem, carefully designing a training method and introducing constraints are essential. To avoid the difficulty of training all elements at the same time, we propose training category-specific base shapes with fixed pose distribution and simple textures first, and subsequently training poses and textures using the obtained shapes. Another difficulty is that shapes and backgrounds sometimes become excessively complicated to mistakenly reconstruct textures on object surfaces. To suppress it, we propose using strong regularization and constraints on object surfaces and background images. With these two techniques, we demonstrate that we can use natural image collections such as CIFAR-10 and PASCAL objects for training, which indicates the possibility to realize 3D object reconstruction on diverse object categories beyond synthetic datasets.
Learning View Priors for Single-view 3D Reconstruction
Nov 26, 2018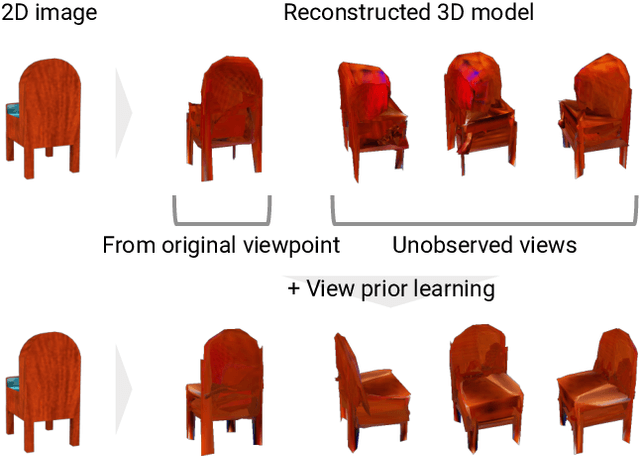

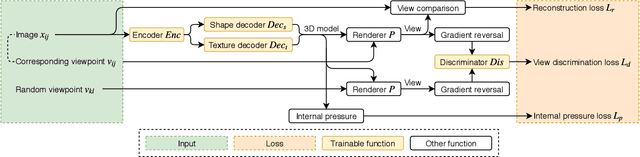
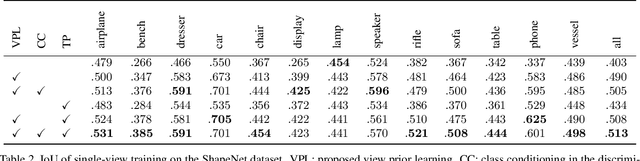
There is some ambiguity in the 3D shape of an object when the number of observed views is small. Because of this ambiguity, although a 3D object reconstructor can be trained using a single view or a few views per object, reconstructed shapes only fit the observed views and appear incorrect from the unobserved viewpoints. To reconstruct shapes that look reasonable from any viewpoint, we propose to train a discriminator that learns prior knowledge regarding possible views. The discriminator is trained to distinguish the reconstructed views of the observed viewpoints from those of the unobserved viewpoints. The reconstructor is trained to correct unobserved views by fooling the discriminator. Our method outperforms current state-of-the-art methods on both synthetic and natural image datasets; this validates the effectiveness of our method.
Neural 3D Mesh Renderer
Nov 20, 2017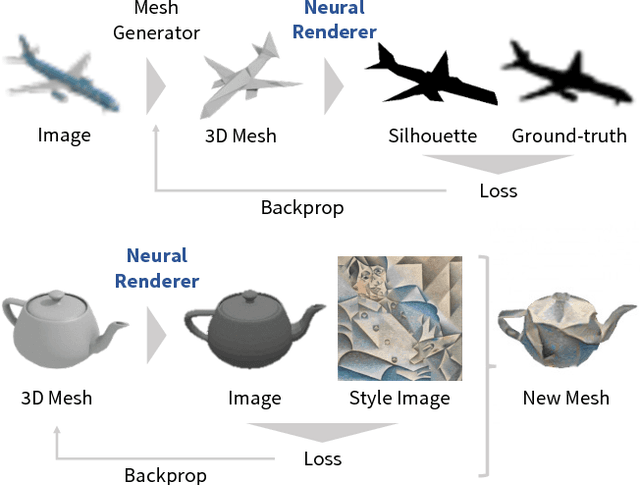
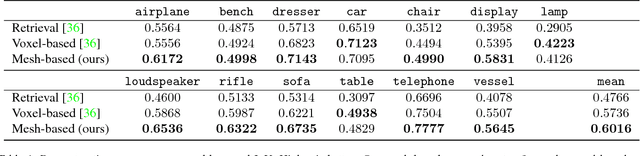
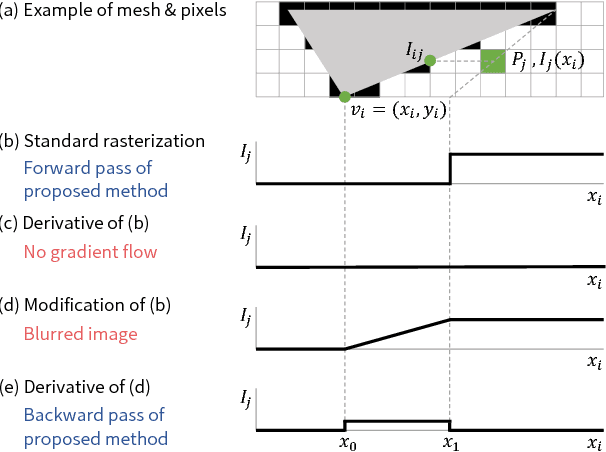
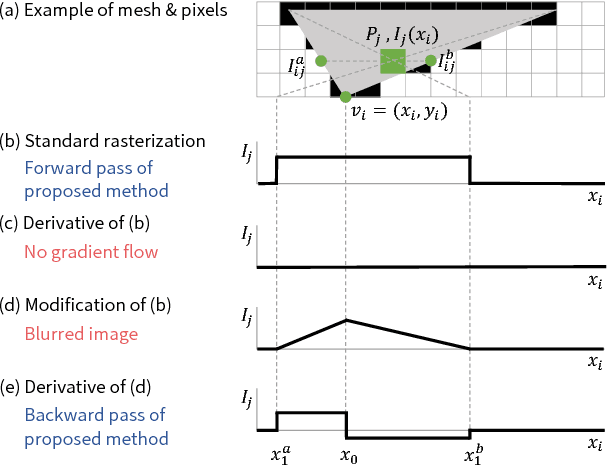
For modeling the 3D world behind 2D images, which 3D representation is most appropriate? A polygon mesh is a promising candidate for its compactness and geometric properties. However, it is not straightforward to model a polygon mesh from 2D images using neural networks because the conversion from a mesh to an image, or rendering, involves a discrete operation called rasterization, which prevents back-propagation. Therefore, in this work, we propose an approximate gradient for rasterization that enables the integration of rendering into neural networks. Using this renderer, we perform single-image 3D mesh reconstruction with silhouette image supervision and our system outperforms the existing voxel-based approach. Additionally, we perform gradient-based 3D mesh editing operations, such as 2D-to-3D style transfer and 3D DeepDream, with 2D supervision for the first time. These applications demonstrate the potential of the integration of a mesh renderer into neural networks and the effectiveness of our proposed renderer.
Visual Language Modeling on CNN Image Representations
Nov 09, 2015
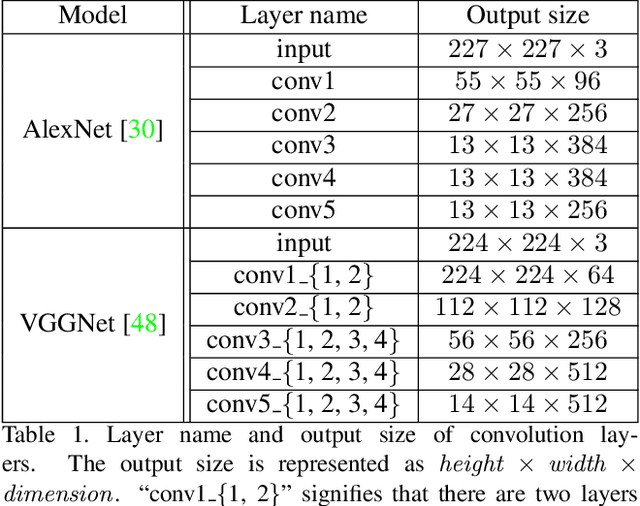


Measuring the naturalness of images is important to generate realistic images or to detect unnatural regions in images. Additionally, a method to measure naturalness can be complementary to Convolutional Neural Network (CNN) based features, which are known to be insensitive to the naturalness of images. However, most probabilistic image models have insufficient capability of modeling the complex and abstract naturalness that we feel because they are built directly on raw image pixels. In this work, we assume that naturalness can be measured by the predictability on high-level features during eye movement. Based on this assumption, we propose a novel method to evaluate the naturalness by building a variant of Recurrent Neural Network Language Models on pre-trained CNN representations. Our method is applied to two tasks, demonstrating that 1) using our method as a regularizer enables us to generate more understandable images from image features than existing approaches, and 2) unnaturalness maps produced by our method achieve state-of-the-art eye fixation prediction performance on two well-studied datasets.
Image Reconstruction from Bag-of-Visual-Words
May 19, 2015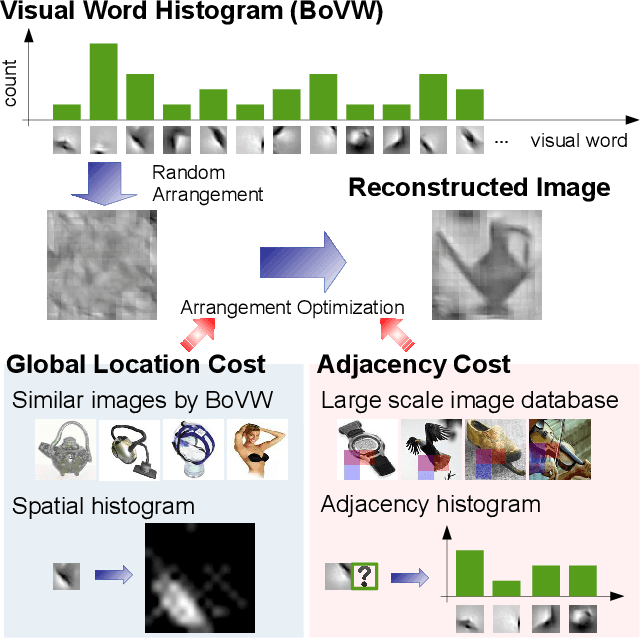
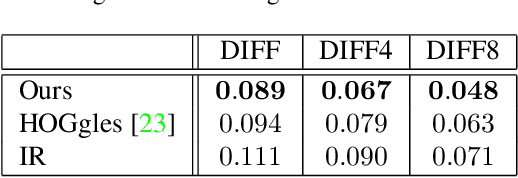

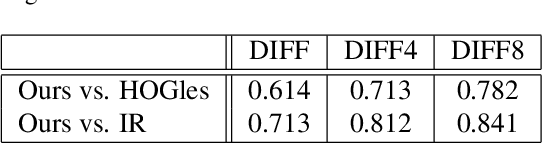
The objective of this work is to reconstruct an original image from Bag-of-Visual-Words (BoVW). Image reconstruction from features can be a means of identifying the characteristics of features. Additionally, it enables us to generate novel images via features. Although BoVW is the de facto standard feature for image recognition and retrieval, successful image reconstruction from BoVW has not been reported yet. What complicates this task is that BoVW lacks the spatial information for including visual words. As described in this paper, to estimate an original arrangement, we propose an evaluation function that incorporates the naturalness of local adjacency and the global position, with a method to obtain related parameters using an external image database. To evaluate the performance of our method, we reconstruct images of objects of 101 kinds. Additionally, we apply our method to analyze object classifiers and to generate novel images via BoVW.