 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

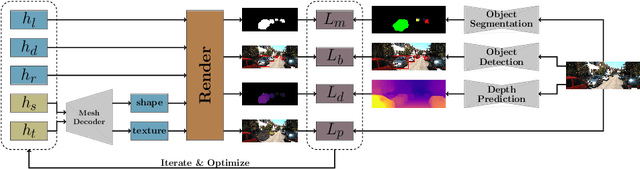
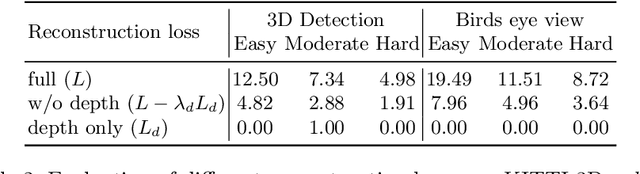
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.
Differentiable Rendering: A Survey
Jun 22, 2020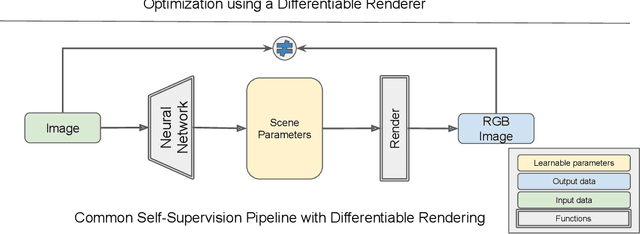
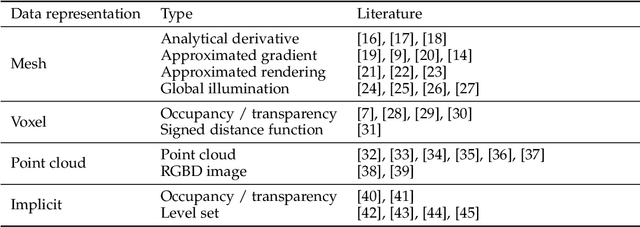
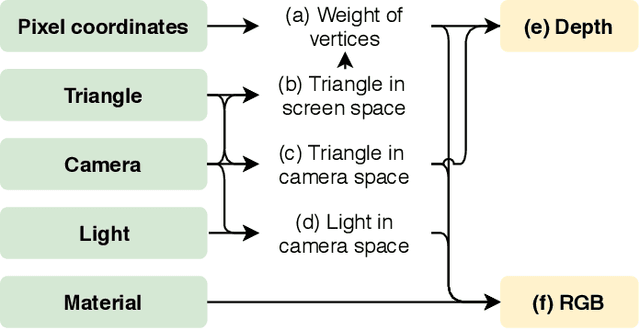

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.