 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopSparse: Accelerated block sparse matrix multiplication on IPU
Apr 05, 2023



Reducing the computational cost of running large scale neural networks using sparsity has attracted great attention in the deep learning community. While much success has been achieved in reducing FLOP and parameter counts while maintaining acceptable task performance, achieving actual speed improvements has typically been much more difficult, particularly on general purpose accelerators (GPAs) such as NVIDIA GPUs using low precision number formats. In this work we introduce PopSparse, a library that enables fast sparse operations on Graphcore IPUs by leveraging both the unique hardware characteristics of IPUs as well as any block structure defined in the data. We target two different types of sparsity: static, where the sparsity pattern is fixed at compile-time; and dynamic, where it can change each time the model is run. We present benchmark results for matrix multiplication for both of these modes on IPU with a range of block sizes, matrix sizes and densities. Results indicate that the PopSparse implementations are faster than dense matrix multiplications on IPU at a range of sparsity levels with large matrix size and block size. Furthermore, static sparsity in general outperforms dynamic sparsity. While previous work on GPAs has shown speedups only for very high sparsity (typically 99\% and above), the present work demonstrates that our static sparse implementation outperforms equivalent dense calculations in FP16 at lower sparsity (around 90%). IPU code is available to view and run at ipu.dev/sparsity-benchmarks, GPU code will be made available shortly.
GPS++: Reviving the Art of Message Passing for Molecular Property Prediction
Feb 06, 2023



We present GPS++, a hybrid Message Passing Neural Network / Graph Transformer model for molecular property prediction. Our model integrates a well-tuned local message passing component and biased global attention with other key ideas from prior literature to achieve state-of-the-art results on large-scale molecular dataset PCQM4Mv2. Through a thorough ablation study we highlight the impact of individual components and, contrary to expectations set by recent trends, find that nearly all of the model's performance can be maintained without any use of global self-attention. We also show that our approach is significantly more accurate than prior art when 3D positional information is not available.
GPS++: An Optimised Hybrid MPNN/Transformer for Molecular Property Prediction
Dec 06, 2022



This technical report presents GPS++, the first-place solution to the Open Graph Benchmark Large-Scale Challenge (OGB-LSC 2022) for the PCQM4Mv2 molecular property prediction task. Our approach implements several key principles from the prior literature. At its core our GPS++ method is a hybrid MPNN/Transformer model that incorporates 3D atom positions and an auxiliary denoising task. The effectiveness of GPS++ is demonstrated by achieving 0.0719 mean absolute error on the independent test-challenge PCQM4Mv2 split. Thanks to Graphcore IPU acceleration, GPS++ scales to deep architectures (16 layers), training at 3 minutes per epoch, and large ensemble (112 models), completing the final predictions in 1 hour 32 minutes, well under the 4 hour inference budget allocated. Our implementation is publicly available at: https://github.com/graphcore/ogb-lsc-pcqm4mv2.
Monocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

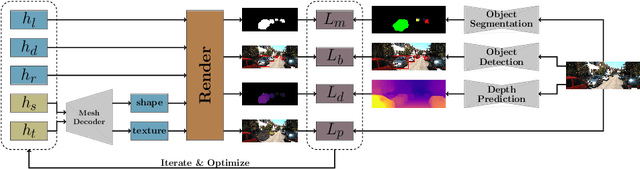
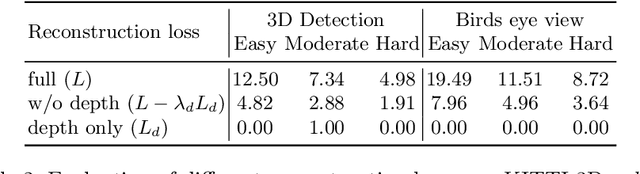
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.
Differentiable Rendering: A Survey
Jun 22, 2020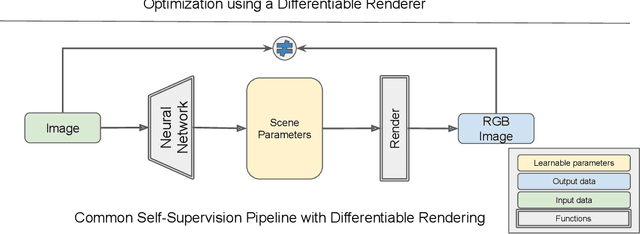
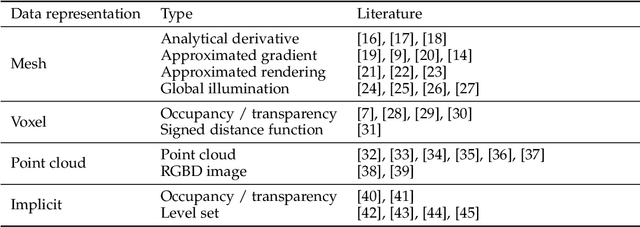
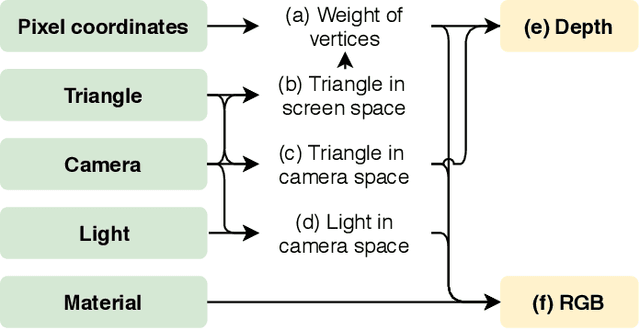

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.