 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Directional Parameterization in Neural Implicit Surface Reconstruction
Sep 11, 2024



Multi-view 3D surface reconstruction using neural implicit representations has made notable progress by modeling the geometry and view-dependent radiance fields within a unified framework. However, their effectiveness in reconstructing objects with specular or complex surfaces is typically biased by the directional parameterization used in their view-dependent radiance network. {\it Viewing direction} and {\it reflection direction} are the two most commonly used directional parameterizations but have their own limitations. Typically, utilizing the viewing direction usually struggles to correctly decouple the geometry and appearance of objects with highly specular surfaces, while using the reflection direction tends to yield overly smooth reconstructions for concave or complex structures. In this paper, we analyze their failed cases in detail and propose a novel hybrid directional parameterization to address their limitations in a unified form. Extensive experiments demonstrate the proposed hybrid directional parameterization consistently delivered satisfactory results in reconstructing objects with a wide variety of materials, geometry and appearance, whereas using other directional parameterizations faces challenges in reconstructing certain objects. Moreover, the proposed hybrid directional parameterization is nearly parameter-free and can be effortlessly applied in any existing neural surface reconstruction method.
Neural Radiance Fields for Novel View Synthesis in Monocular Gastroscopy
May 29, 2024



Enabling the synthesis of arbitrarily novel viewpoint images within a patient's stomach from pre-captured monocular gastroscopic images is a promising topic in stomach diagnosis. Typical methods to achieve this objective integrate traditional 3D reconstruction techniques, including structure-from-motion (SfM) and Poisson surface reconstruction. These methods produce explicit 3D representations, such as point clouds and meshes, thereby enabling the rendering of the images from novel viewpoints. However, the existence of low-texture and non-Lambertian regions within the stomach often results in noisy and incomplete reconstructions of point clouds and meshes, hindering the attainment of high-quality image rendering. In this paper, we apply the emerging technique of neural radiance fields (NeRF) to monocular gastroscopic data for synthesizing photo-realistic images for novel viewpoints. To address the performance degradation due to view sparsity in local regions of monocular gastroscopy, we incorporate geometry priors from a pre-reconstructed point cloud into the training of NeRF, which introduces a novel geometry-based loss to both pre-captured observed views and generated unobserved views. Compared to other recent NeRF methods, our approach showcases high-fidelity image renderings from novel viewpoints within the stomach both qualitatively and quantitatively.
EMR-MSF: Self-Supervised Recurrent Monocular Scene Flow Exploiting Ego-Motion Rigidity
Sep 04, 2023Self-supervised monocular scene flow estimation, aiming to understand both 3D structures and 3D motions from two temporally consecutive monocular images, has received increasing attention for its simple and economical sensor setup. However, the accuracy of current methods suffers from the bottleneck of less-efficient network architecture and lack of motion rigidity for regularization. In this paper, we propose a superior model named EMR-MSF by borrowing the advantages of network architecture design under the scope of supervised learning. We further impose explicit and robust geometric constraints with an elaborately constructed ego-motion aggregation module where a rigidity soft mask is proposed to filter out dynamic regions for stable ego-motion estimation using static regions. Moreover, we propose a motion consistency loss along with a mask regularization loss to fully exploit static regions. Several efficient training strategies are integrated including a gradient detachment technique and an enhanced view synthesis process for better performance. Our proposed method outperforms the previous self-supervised works by a large margin and catches up to the performance of supervised methods. On the KITTI scene flow benchmark, our approach improves the SF-all metric of the state-of-the-art self-supervised monocular method by 44% and demonstrates superior performance across sub-tasks including depth and visual odometry, amongst other self-supervised single-task or multi-task methods.
Self-Supervised Ego-Motion Estimation Based on Multi-Layer Fusion of RGB and Inferred Depth
Mar 03, 2022
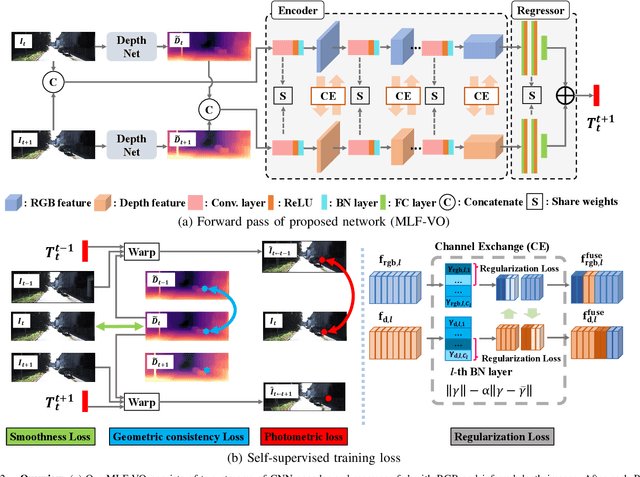
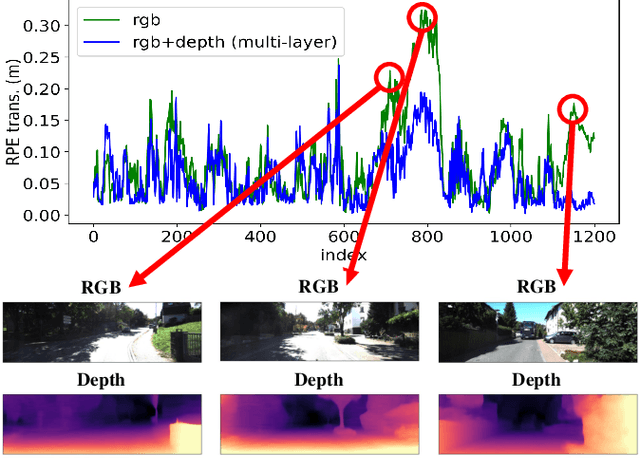

In existing self-supervised depth and ego-motion estimation methods, ego-motion estimation is usually limited to only leveraging RGB information. Recently, several methods have been proposed to further improve the accuracy of self-supervised ego-motion estimation by fusing information from other modalities, e.g., depth, acceleration, and angular velocity. However, they rarely focus on how different fusion strategies affect performance. In this paper, we investigate the effect of different fusion strategies for ego-motion estimation and propose a new framework for self-supervised learning of depth and ego-motion estimation, which performs ego-motion estimation by leveraging RGB and inferred depth information in a Multi-Layer Fusion manner. As a result, we have achieved state-of-the-art performance among learning-based methods on the KITTI odometry benchmark. Detailed studies on the design choices of leveraging inferred depth information and fusion strategies have also been carried out, which clearly demonstrate the advantages of our proposed framework.
VIO-Aided Structure from Motion Under Challenging Environments
Jan 26, 2021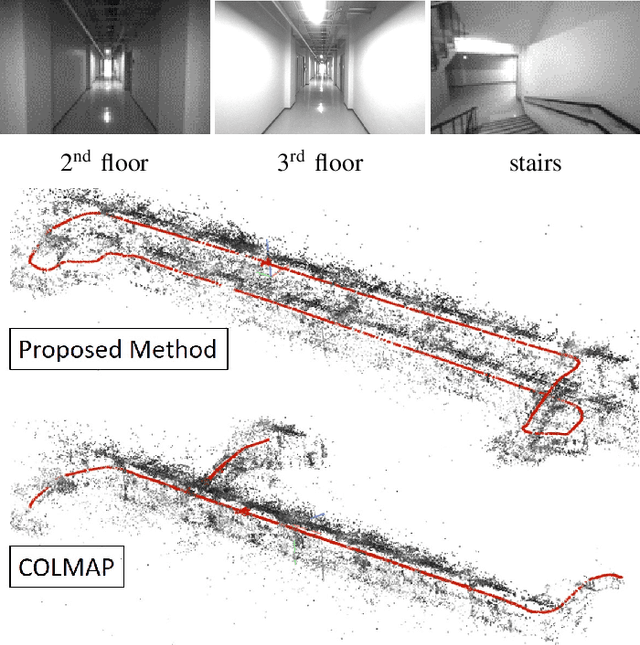
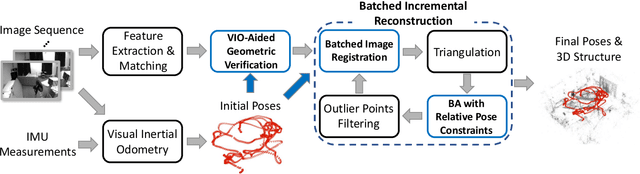
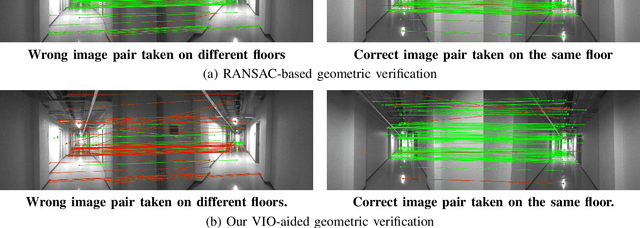

In this paper, we present a robust and efficient Structure from Motion pipeline for accurate 3D reconstruction under challenging environments by leveraging the camera pose information from a visual-inertial odometry. Specifically, we propose a geometric verification method to filter out mismatches by considering the prior geometric configuration of candidate image pairs. Furthermore, we introduce an efficient and scalable reconstruction approach that relies on batched image registration and robust bundle adjustment, both leveraging the reliable local odometry estimation. Extensive experimental results show that our pipeline performs better than the state-of-the-art SfM approaches in terms of reconstruction accuracy and robustness for challenging sequential image collections.