 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Ego-Motion Estimation Based on Multi-Layer Fusion of RGB and Inferred Depth
Mar 03, 2022
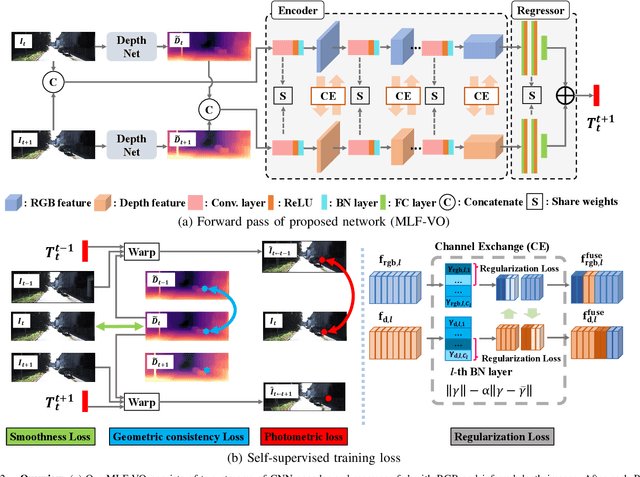
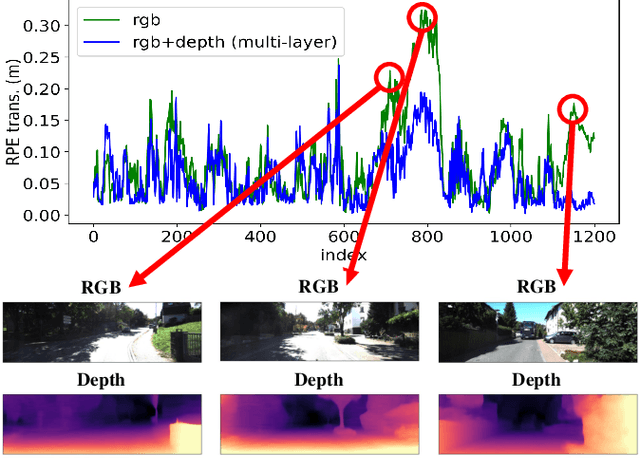

In existing self-supervised depth and ego-motion estimation methods, ego-motion estimation is usually limited to only leveraging RGB information. Recently, several methods have been proposed to further improve the accuracy of self-supervised ego-motion estimation by fusing information from other modalities, e.g., depth, acceleration, and angular velocity. However, they rarely focus on how different fusion strategies affect performance. In this paper, we investigate the effect of different fusion strategies for ego-motion estimation and propose a new framework for self-supervised learning of depth and ego-motion estimation, which performs ego-motion estimation by leveraging RGB and inferred depth information in a Multi-Layer Fusion manner. As a result, we have achieved state-of-the-art performance among learning-based methods on the KITTI odometry benchmark. Detailed studies on the design choices of leveraging inferred depth information and fusion strategies have also been carried out, which clearly demonstrate the advantages of our proposed framework.
Video-Based Camera Localization Using Anchor View Detection and Recursive 3D Reconstruction
Jul 07, 2021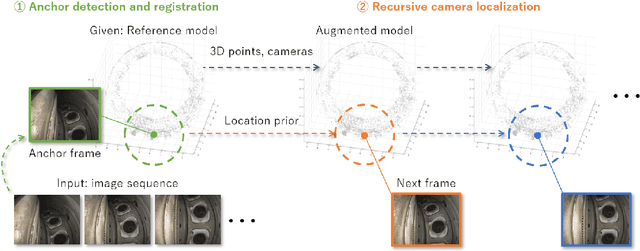
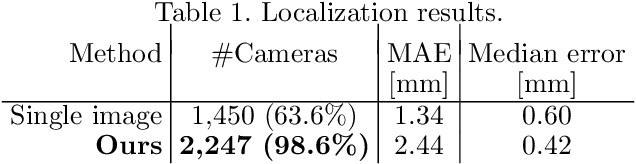
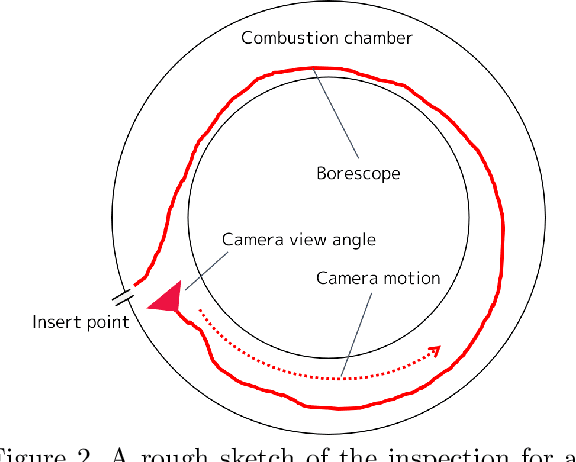

In this paper we introduce a new camera localization strategy designed for image sequences captured in challenging industrial situations such as industrial parts inspection. To deal with peculiar appearances that hurt standard 3D reconstruction pipeline, we exploit pre-knowledge of the scene by selecting key frames in the sequence (called as anchors) which are roughly connected to a certain location. Our method then seek the location of each frame in time-order, while recursively updating an augmented 3D model which can provide current camera location and surrounding 3D structure. In an experiment on a practical industrial situation, our method can localize over 99% frames in the input sequence, whereas standard localization methods fail to reconstruct a complete camera trajectory.
VIO-Aided Structure from Motion Under Challenging Environments
Jan 26, 2021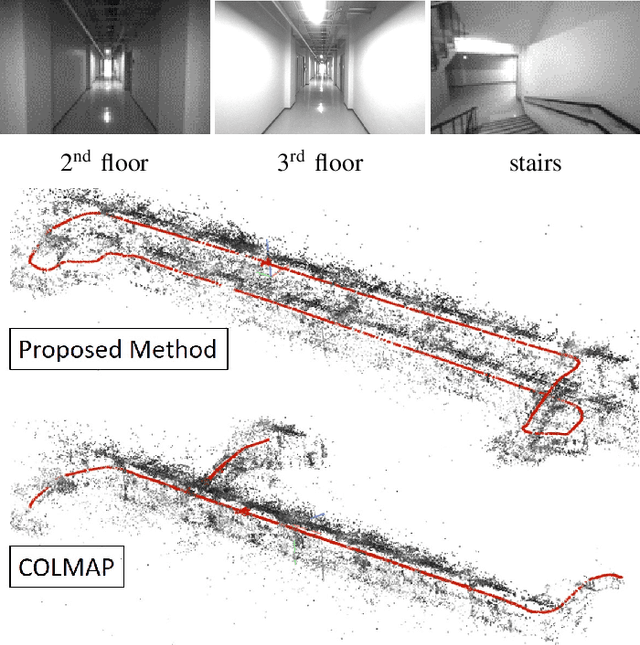
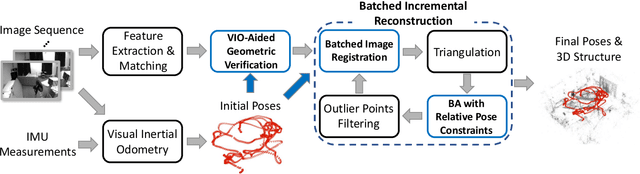
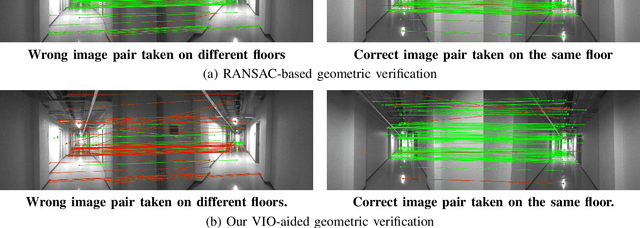

In this paper, we present a robust and efficient Structure from Motion pipeline for accurate 3D reconstruction under challenging environments by leveraging the camera pose information from a visual-inertial odometry. Specifically, we propose a geometric verification method to filter out mismatches by considering the prior geometric configuration of candidate image pairs. Furthermore, we introduce an efficient and scalable reconstruction approach that relies on batched image registration and robust bundle adjustment, both leveraging the reliable local odometry estimation. Extensive experimental results show that our pipeline performs better than the state-of-the-art SfM approaches in terms of reconstruction accuracy and robustness for challenging sequential image collections.
3D Pipe Network Reconstruction Based on Structure from Motion with Incremental Conic Shape Detection and Cylindrical Constraint
Jul 03, 2020
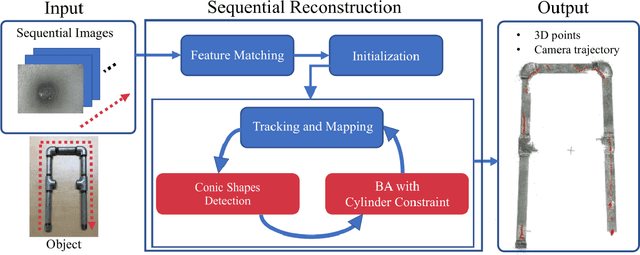
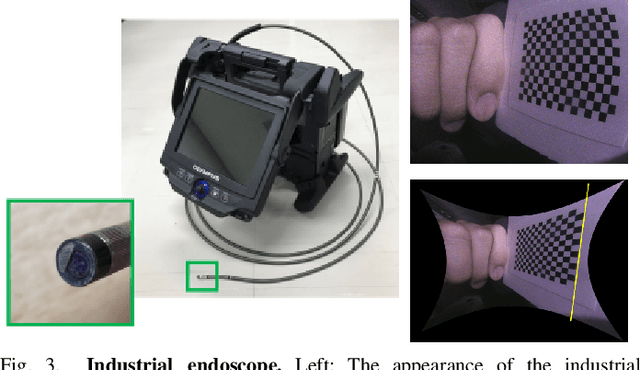
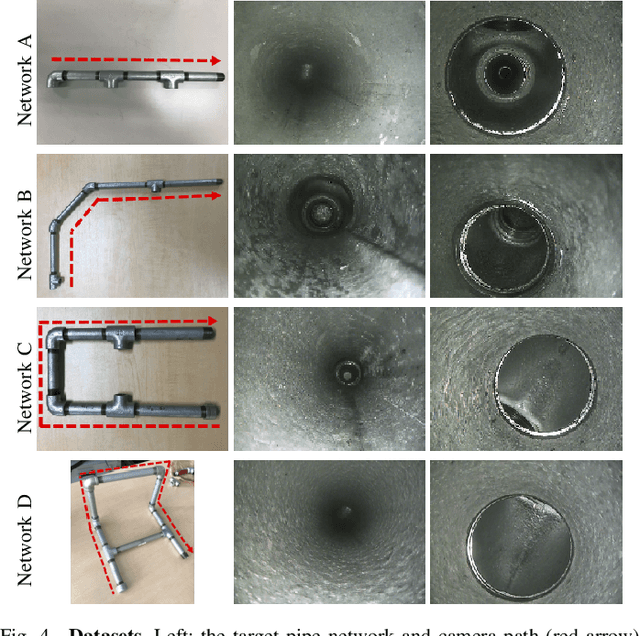
Pipe inspection is a critical task for many industries and infrastructure of a city. The 3D information of a pipe can be used for revealing the deformation of the pipe surface and position of the camera during the inspection. In this paper, we propose a 3D pipe reconstruction system using sequential images captured by a monocular endoscopic camera. Our work extends a state-of-the-art incremental Structure-from-Motion (SfM) method to incorporate prior constraints given by the target shape into bundle adjustment (BA). Using this constraint, we can minimize the scale-drift that is the general problem in SfM. Moreover, our method can reconstruct a pipe network composed of multiple parts including straight pipes, elbows, and tees. In the experiments, we show that the proposed system enables more accurate and robust pipe mapping from a monocular camera in comparison with existing state-of-the-art methods.