 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetail store customer behavior analysis system: Design and Implementation
Sep 05, 2023



Understanding customer behavior in retail stores plays a crucial role in improving customer satisfaction by adding personalized value to services. Behavior analysis reveals both general and detailed patterns in the interaction of customers with a store items and other people, providing store managers with insight into customer preferences. Several solutions aim to utilize this data by recognizing specific behaviors through statistical visualization. However, current approaches are limited to the analysis of small customer behavior sets, utilizing conventional methods to detect behaviors. They do not use deep learning techniques such as deep neural networks, which are powerful methods in the field of computer vision. Furthermore, these methods provide limited figures when visualizing the behavioral data acquired by the system. In this study, we propose a framework that includes three primary parts: mathematical modeling of customer behaviors, behavior analysis using an efficient deep learning based system, and individual and group behavior visualization. Each module and the entire system were validated using data from actual situations in a retail store.
F2SD: A dataset for end-to-end group detection algorithms
Nov 20, 2022The lack of large-scale datasets has been impeding the advance of deep learning approaches to the problem of F-formation detection. Moreover, most research works on this problem rely on input sensor signals of object location and orientation rather than image signals. To address this, we develop a new, large-scale dataset of simulated images for F-formation detection, called F-formation Simulation Dataset (F2SD). F2SD contains nearly 60,000 images simulated from GTA-5, with bounding boxes and orientation information on images, making it useful for a wide variety of modelling approaches. It is also closer to practical scenarios, where three-dimensional location and orientation information are costly to record. It is challenging to construct such a large-scale simulated dataset while keeping it realistic. Furthermore, the available research utilizes conventional methods to detect groups. They do not detect groups directly from the image. In this work, we propose (1) a large-scale simulation dataset F2SD and a pipeline for F-formation simulation, (2) a first-ever end-to-end baseline model for the task, and experiments on our simulation dataset.
3D Pipe Network Reconstruction Based on Structure from Motion with Incremental Conic Shape Detection and Cylindrical Constraint
Jul 03, 2020
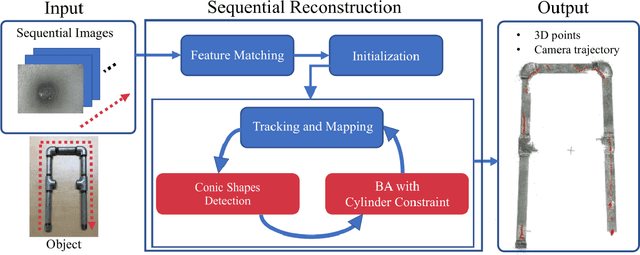
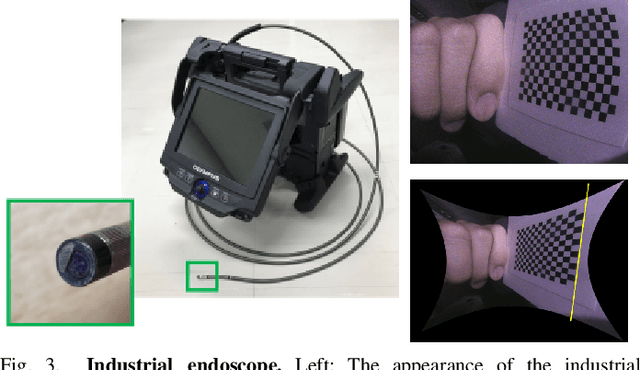
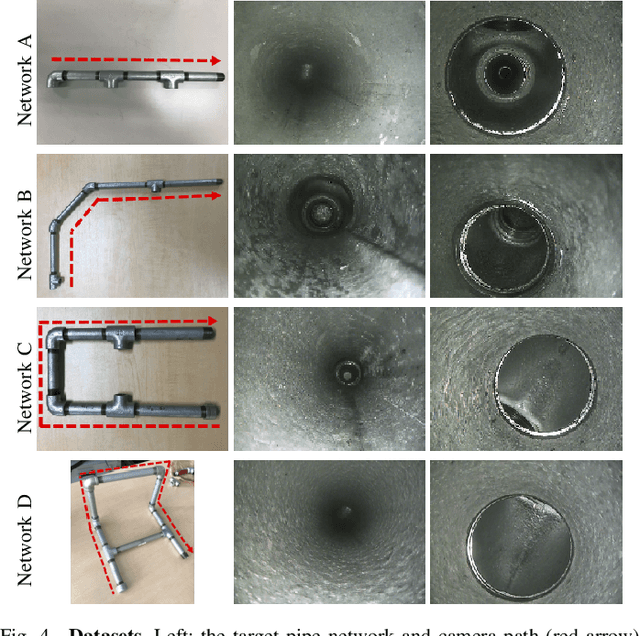
Pipe inspection is a critical task for many industries and infrastructure of a city. The 3D information of a pipe can be used for revealing the deformation of the pipe surface and position of the camera during the inspection. In this paper, we propose a 3D pipe reconstruction system using sequential images captured by a monocular endoscopic camera. Our work extends a state-of-the-art incremental Structure-from-Motion (SfM) method to incorporate prior constraints given by the target shape into bundle adjustment (BA). Using this constraint, we can minimize the scale-drift that is the general problem in SfM. Moreover, our method can reconstruct a pipe network composed of multiple parts including straight pipes, elbows, and tees. In the experiments, we show that the proposed system enables more accurate and robust pipe mapping from a monocular camera in comparison with existing state-of-the-art methods.
Is This The Right Place? Geometric-Semantic Pose Verification for Indoor Visual Localization
Sep 02, 2019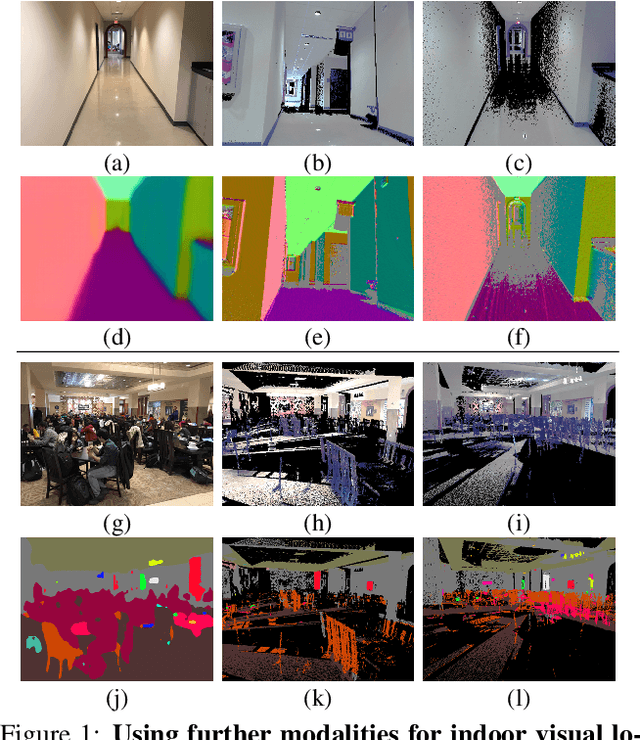
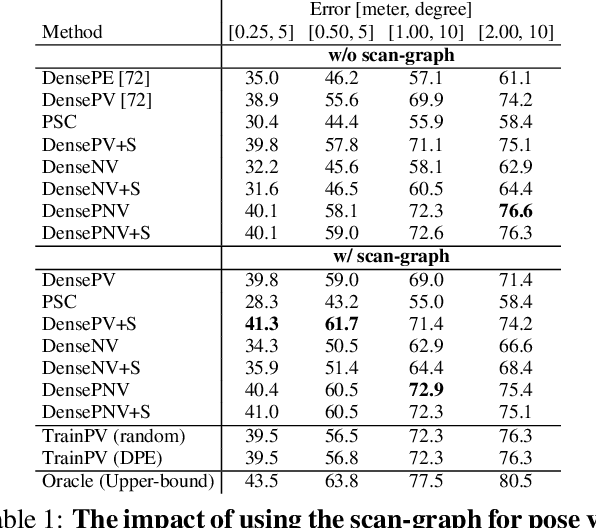
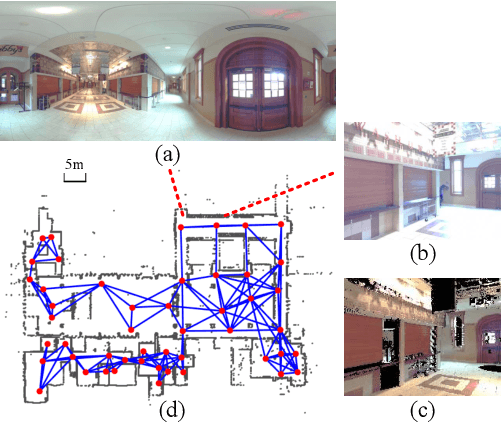
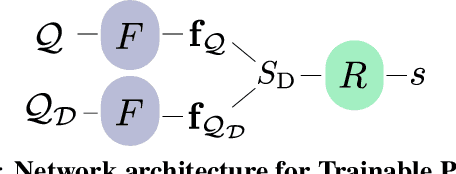
Visual localization in large and complex indoor scenes, dominated by weakly textured rooms and repeating geometric patterns, is a challenging problem with high practical relevance for applications such as Augmented Reality and robotics. To handle the ambiguities arising in this scenario, a common strategy is, first, to generate multiple estimates for the camera pose from which a given query image was taken. The pose with the largest geometric consistency with the query image, e.g., in the form of an inlier count, is then selected in a second stage. While a significant amount of research has concentrated on the first stage, there is considerably less work on the second stage. In this paper, we thus focus on pose verification. We show that combining different modalities, namely appearance, geometry, and semantics, considerably boosts pose verification and consequently pose accuracy. We develop multiple hand-crafted as well as a trainable approach to join into the geometric-semantic verification and show significant improvements over state-of-the-art on a very challenging indoor dataset.
D2-Net: A Trainable CNN for Joint Detection and Description of Local Features
May 09, 2019
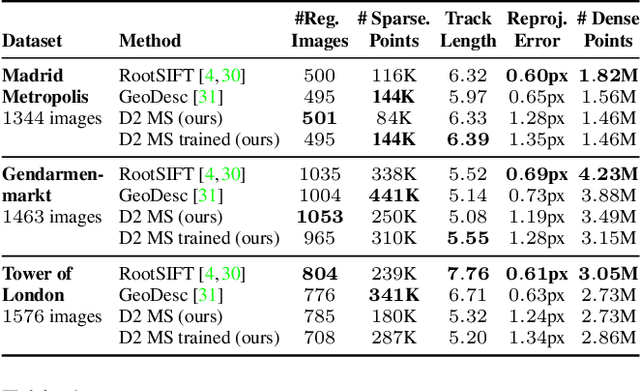
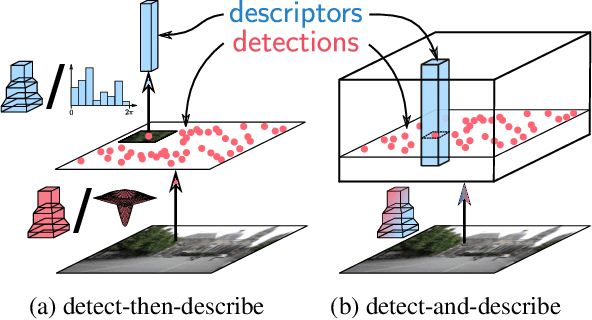
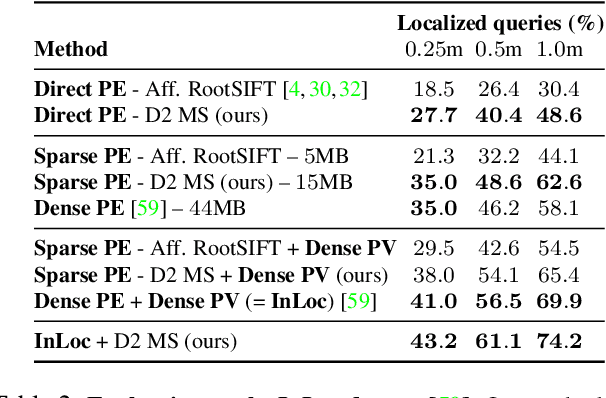
In this work we address the problem of finding reliable pixel-level correspondences under difficult imaging conditions. We propose an approach where a single convolutional neural network plays a dual role: It is simultaneously a dense feature descriptor and a feature detector. By postponing the detection to a later stage, the obtained keypoints are more stable than their traditional counterparts based on early detection of low-level structures. We show that this model can be trained using pixel correspondences extracted from readily available large-scale SfM reconstructions, without any further annotations. The proposed method obtains state-of-the-art performance on both the difficult Aachen Day-Night localization dataset and the InLoc indoor localization benchmark, as well as competitive performance on other benchmarks for image matching and 3D reconstruction.
Neighbourhood Consensus Networks
Oct 24, 2018
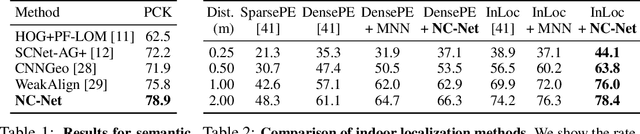


We address the problem of finding reliable dense correspondences between a pair of images. This is a challenging task due to strong appearance differences between the corresponding scene elements and ambiguities generated by repetitive patterns. The contributions of this work are threefold. First, inspired by the classic idea of disambiguating feature matches using semi-local constraints, we develop an end-to-end trainable convolutional neural network architecture that identifies sets of spatially consistent matches by analyzing neighbourhood consensus patterns in the 4D space of all possible correspondences between a pair of images without the need for a global geometric model. Second, we demonstrate that the model can be trained effectively from weak supervision in the form of matching and non-matching image pairs without the need for costly manual annotation of point to point correspondences. Third, we show the proposed neighbourhood consensus network can be applied to a range of matching tasks including both category- and instance-level matching, obtaining the state-of-the-art results on the PF Pascal dataset and the InLoc indoor visual localization benchmark.
Structure-from-Motion using Dense CNN Features with Keypoint Relocalization
May 11, 2018


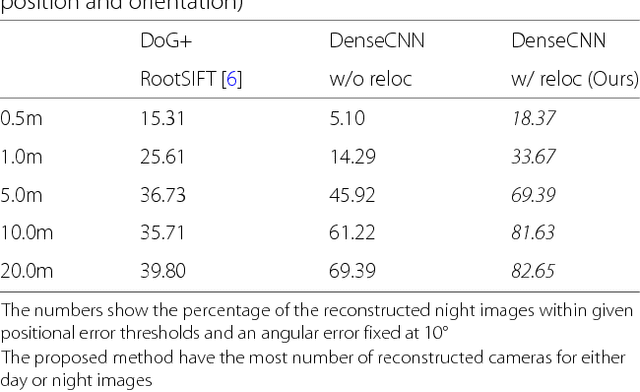
Structure from Motion (SfM) using imagery that involves extreme appearance changes is yet a challenging task due to a loss of feature repeatability. Using feature correspondences obtained by matching densely extracted convolutional neural network (CNN) features significantly improves the SfM reconstruction capability. However, the reconstruction accuracy is limited by the spatial resolution of the extracted CNN features which is not even pixel-level accuracy in the existing approach. Providing dense feature matches with precise keypoint positions is not trivial because of memory limitation and computational burden of dense features. To achieve accurate SfM reconstruction with highly repeatable dense features, we propose an SfM pipeline that uses dense CNN features with relocalization of keypoint position that can efficiently and accurately provide pixel-level feature correspondences. Then, we demonstrate on the Aachen Day-Night dataset that the proposed SfM using dense CNN features with the keypoint relocalization outperforms a state-of-the-art SfM (COLMAP using RootSIFT) by a large margin.
InLoc: Indoor Visual Localization with Dense Matching and View Synthesis
Apr 08, 2018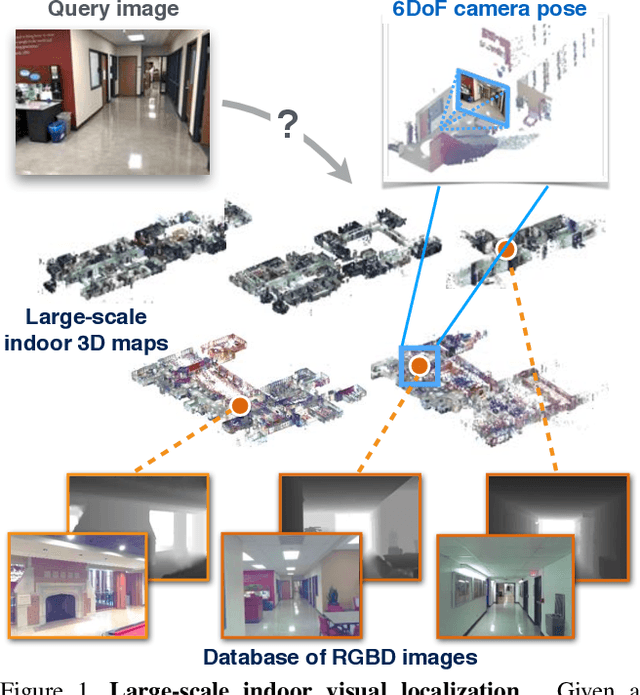

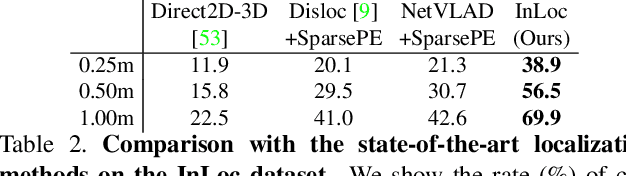

We seek to predict the 6 degree-of-freedom (6DoF) pose of a query photograph with respect to a large indoor 3D map. The contributions of this work are three-fold. First, we develop a new large-scale visual localization method targeted for indoor environments. The method proceeds along three steps: (i) efficient retrieval of candidate poses that ensures scalability to large-scale environments, (ii) pose estimation using dense matching rather than local features to deal with textureless indoor scenes, and (iii) pose verification by virtual view synthesis to cope with significant changes in viewpoint, scene layout, and occluders. Second, we collect a new dataset with reference 6DoF poses for large-scale indoor localization. Query photographs are captured by mobile phones at a different time than the reference 3D map, thus presenting a realistic indoor localization scenario. Third, we demonstrate that our method significantly outperforms current state-of-the-art indoor localization approaches on this new challenging data.
Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions
Apr 04, 2018



Visual localization enables autonomous vehicles to navigate in their surroundings and augmented reality applications to link virtual to real worlds. Practical visual localization approaches need to be robust to a wide variety of viewing condition, including day-night changes, as well as weather and seasonal variations, while providing highly accurate 6 degree-of-freedom (6DOF) camera pose estimates. In this paper, we introduce the first benchmark datasets specifically designed for analyzing the impact of such factors on visual localization. Using carefully created ground truth poses for query images taken under a wide variety of conditions, we evaluate the impact of various factors on 6DOF camera pose estimation accuracy through extensive experiments with state-of-the-art localization approaches. Based on our results, we draw conclusions about the difficulty of different conditions, showing that long-term localization is far from solved, and propose promising avenues for future work, including sequence-based localization approaches and the need for better local features. Our benchmark is available at visuallocalization.net.
NetVLAD: CNN architecture for weakly supervised place recognition
May 02, 2016
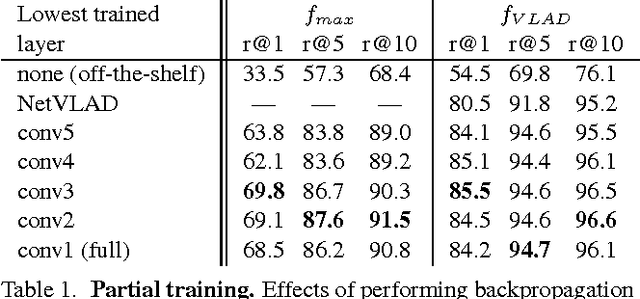

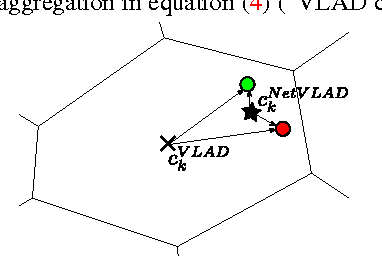
We tackle the problem of large scale visual place recognition, where the task is to quickly and accurately recognize the location of a given query photograph. We present the following three principal contributions. First, we develop a convolutional neural network (CNN) architecture that is trainable in an end-to-end manner directly for the place recognition task. The main component of this architecture, NetVLAD, is a new generalized VLAD layer, inspired by the "Vector of Locally Aggregated Descriptors" image representation commonly used in image retrieval. The layer is readily pluggable into any CNN architecture and amenable to training via backpropagation. Second, we develop a training procedure, based on a new weakly supervised ranking loss, to learn parameters of the architecture in an end-to-end manner from images depicting the same places over time downloaded from Google Street View Time Machine. Finally, we show that the proposed architecture significantly outperforms non-learnt image representations and off-the-shelf CNN descriptors on two challenging place recognition benchmarks, and improves over current state-of-the-art compact image representations on standard image retrieval benchmarks.