 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Positive Contrastive Learning with Pose-Consistent Generated Images
Apr 04, 2024



Model pre-training has become essential in various recognition tasks. Meanwhile, with the remarkable advancements in image generation models, pre-training methods utilizing generated images have also emerged given their ability to produce unlimited training data. However, while existing methods utilizing generated images excel in classification, they fall short in more practical tasks, such as human pose estimation. In this paper, we have experimentally demonstrated it and propose the generation of visually distinct images with identical human poses. We then propose a novel multi-positive contrastive learning, which optimally utilize the previously generated images to learn structural features of the human body. We term the entire learning pipeline as GenPoCCL. Despite using only less than 1% amount of data compared to current state-of-the-art method, GenPoCCL captures structural features of the human body more effectively, surpassing existing methods in a variety of human-centric perception tasks.
Learning-Based Depth and Pose Estimation for Monocular Endoscope with Loss Generalization
Jul 28, 2021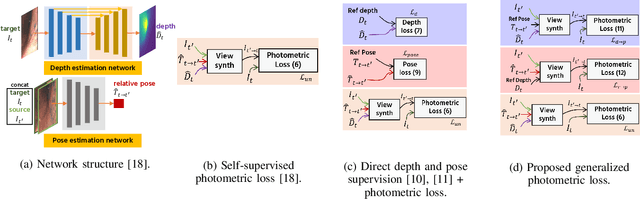
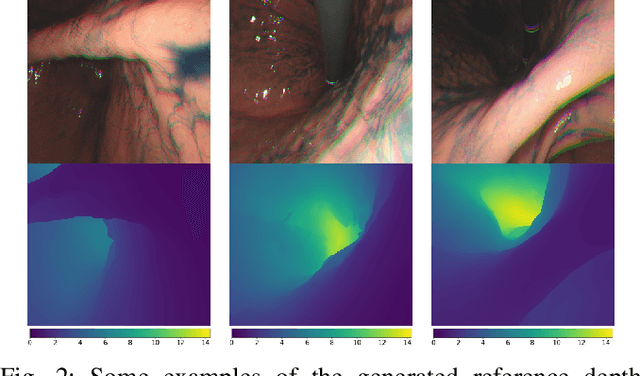
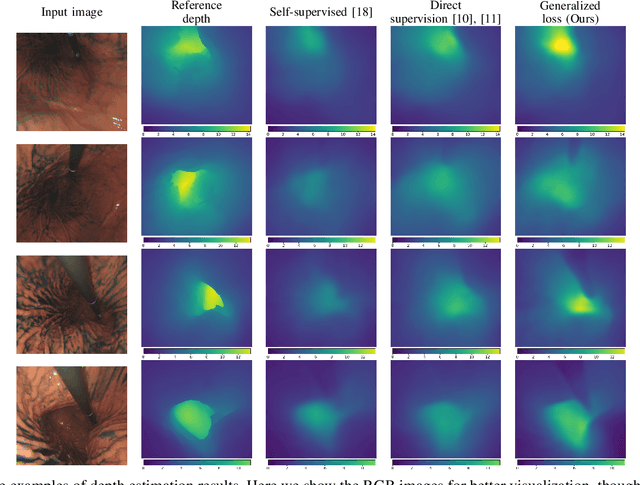
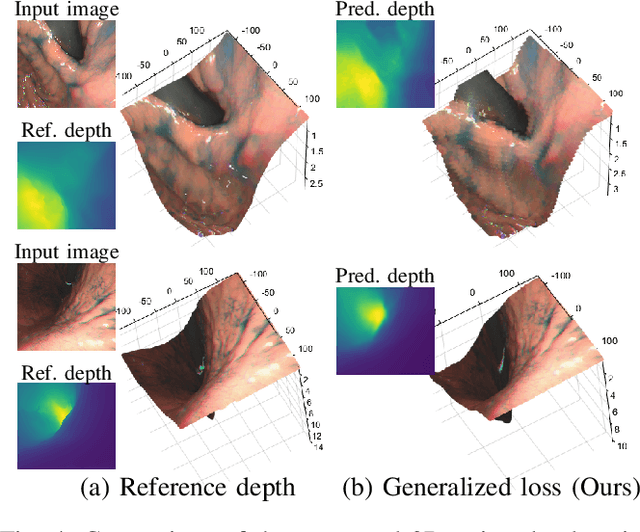
Gastroendoscopy has been a clinical standard for diagnosing and treating conditions that affect a part of a patient's digestive system, such as the stomach. Despite the fact that gastroendoscopy has a lot of advantages for patients, there exist some challenges for practitioners, such as the lack of 3D perception, including the depth and the endoscope pose information. Such challenges make navigating the endoscope and localizing any found lesion in a digestive tract difficult. To tackle these problems, deep learning-based approaches have been proposed to provide monocular gastroendoscopy with additional yet important depth and pose information. In this paper, we propose a novel supervised approach to train depth and pose estimation networks using consecutive endoscopy images to assist the endoscope navigation in the stomach. We firstly generate real depth and pose training data using our previously proposed whole stomach 3D reconstruction pipeline to avoid poor generalization ability between computer-generated (CG) models and real data for the stomach. In addition, we propose a novel generalized photometric loss function to avoid the complicated process of finding proper weights for balancing the depth and the pose loss terms, which is required for existing direct depth and pose supervision approaches. We then experimentally show that our proposed generalized loss performs better than existing direct supervision losses.
Stomach 3D Reconstruction Based on Virtual Chromoendoscopic Image Generation
Apr 26, 2020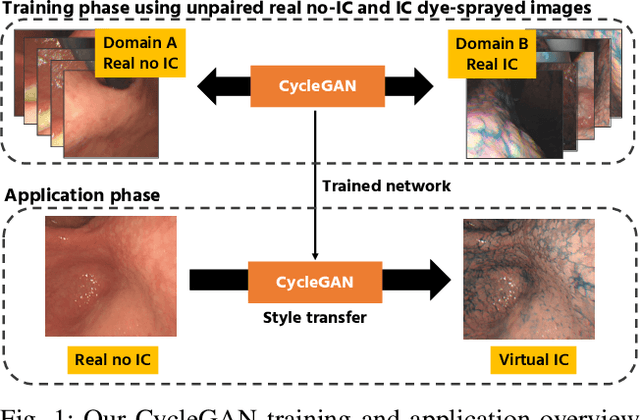
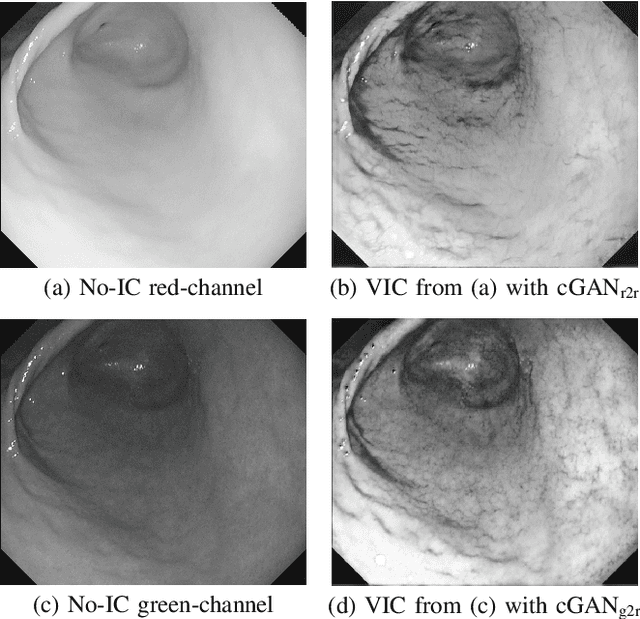


Gastric endoscopy is a standard clinical process that enables medical practitioners to diagnose various lesions inside a patient's stomach. If any lesion is found, it is very important to perceive the location of the lesion relative to the global view of the stomach. Our previous research showed that this could be addressed by reconstructing the whole stomach shape from chromoendoscopic images using a structure-from-motion (SfM) pipeline, in which indigo carmine (IC) blue dye sprayed images were used to increase feature matches for SfM by enhancing stomach surface's textures. However, spraying the IC dye to the whole stomach requires additional time, labor, and cost, which is not desirable for patients and practitioners. In this paper, we propose an alternative way to achieve whole stomach 3D reconstruction without the need of the IC dye by generating virtual IC-sprayed (VIC) images based on image-to-image style translation trained on unpaired real no-IC and IC-sprayed images. We have specifically investigated the effect of input and output color channel selection for generating the VIC images and found that translating no-IC green-channel images to IC-sprayed red-channel images gives the best SfM reconstruction result.
3D Reconstruction of Whole Stomach from Endoscope Video Using Structure-from-Motion
May 30, 2019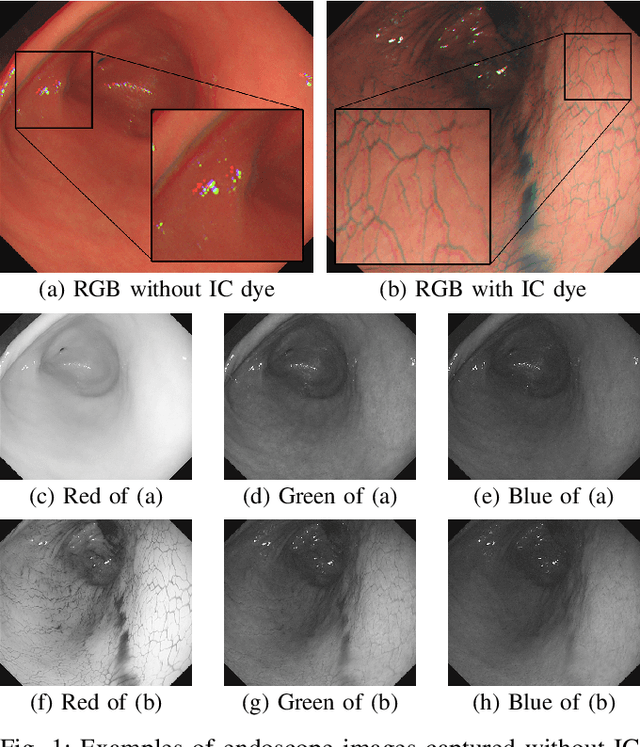
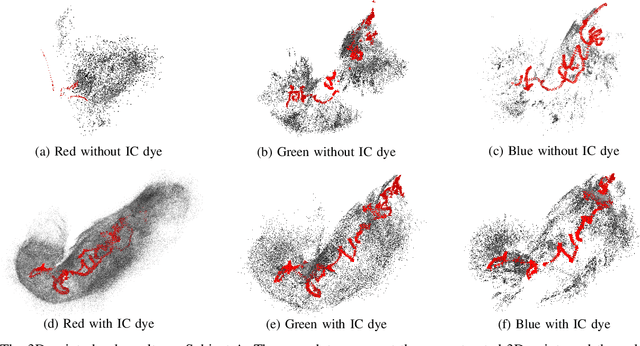
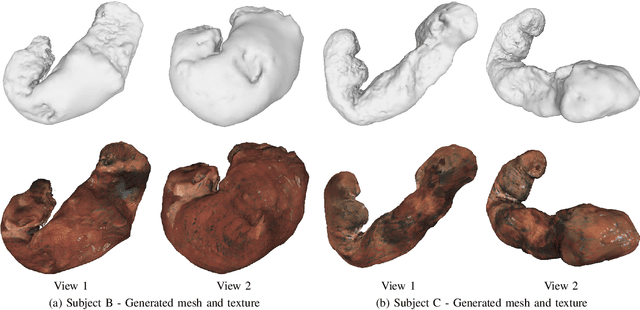
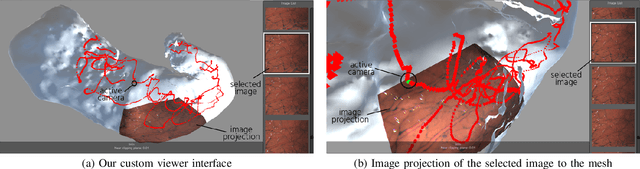
Gastric endoscopy is a common clinical practice that enables medical doctors to diagnose the stomach inside a body. In order to identify a gastric lesion's location such as early gastric cancer within the stomach, this work addressed to reconstruct the 3D shape of a whole stomach with color texture information generated from a standard monocular endoscope video. Previous works have tried to reconstruct the 3D structures of various organs from endoscope images. However, they are mainly focused on a partial surface. In this work, we investigated how to enable structure-from-motion (SfM) to reconstruct the whole shape of a stomach from a standard endoscope video. We specifically investigated the combined effect of chromo-endoscopy and color channel selection on SfM. Our study found that 3D reconstruction of the whole stomach can be achieved by using red channel images captured under chromo-endoscopy by spreading indigo carmine (IC) dye on the stomach surface.
Structure-from-Motion using Dense CNN Features with Keypoint Relocalization
May 11, 2018


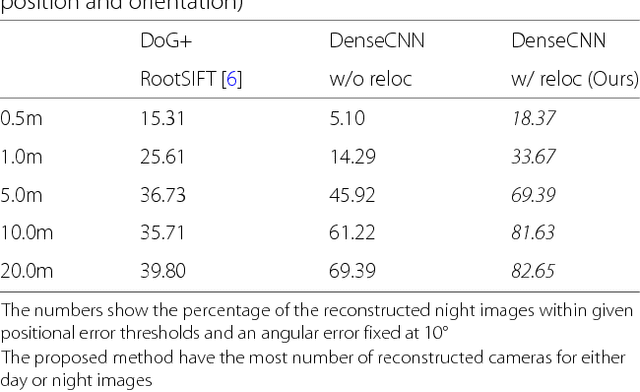
Structure from Motion (SfM) using imagery that involves extreme appearance changes is yet a challenging task due to a loss of feature repeatability. Using feature correspondences obtained by matching densely extracted convolutional neural network (CNN) features significantly improves the SfM reconstruction capability. However, the reconstruction accuracy is limited by the spatial resolution of the extracted CNN features which is not even pixel-level accuracy in the existing approach. Providing dense feature matches with precise keypoint positions is not trivial because of memory limitation and computational burden of dense features. To achieve accurate SfM reconstruction with highly repeatable dense features, we propose an SfM pipeline that uses dense CNN features with relocalization of keypoint position that can efficiently and accurately provide pixel-level feature correspondences. Then, we demonstrate on the Aachen Day-Night dataset that the proposed SfM using dense CNN features with the keypoint relocalization outperforms a state-of-the-art SfM (COLMAP using RootSIFT) by a large margin.