 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Positive Contrastive Learning with Pose-Consistent Generated Images
Apr 04, 2024



Model pre-training has become essential in various recognition tasks. Meanwhile, with the remarkable advancements in image generation models, pre-training methods utilizing generated images have also emerged given their ability to produce unlimited training data. However, while existing methods utilizing generated images excel in classification, they fall short in more practical tasks, such as human pose estimation. In this paper, we have experimentally demonstrated it and propose the generation of visually distinct images with identical human poses. We then propose a novel multi-positive contrastive learning, which optimally utilize the previously generated images to learn structural features of the human body. We term the entire learning pipeline as GenPoCCL. Despite using only less than 1% amount of data compared to current state-of-the-art method, GenPoCCL captures structural features of the human body more effectively, surpassing existing methods in a variety of human-centric perception tasks.
Multimodal Explanations by Predicting Counterfactuality in Videos
Dec 04, 2018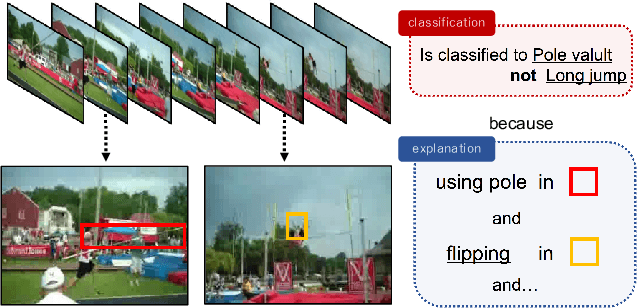
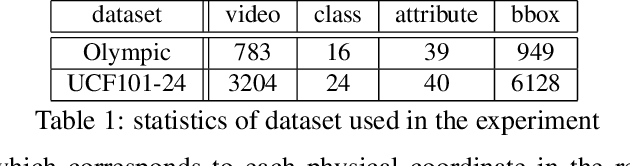
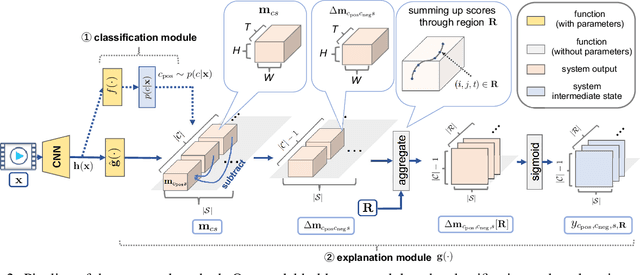
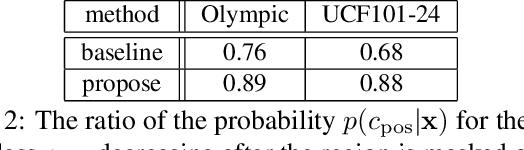
This study addresses generating counterfactual explanations with multimodal information. Our goal is not only to classify a video into a specific category, but also to provide explanations on why it is not predicted as part of a specific class with a combination of visual-linguistic information. Requirements that the expected output should satisfy are referred to as counterfactuality in this paper: (1) Compatibility of visual-linguistic explanations, and (2) Positiveness/negativeness for the specific positive/negative class. Exploiting a spatio-temporal region (tube) and an attribute as visual and linguistic explanations respectively, the explanation model is trained to predict the counterfactuality for possible combinations of multimodal information in a post-hoc manner. The optimization problem, which appears during the training/inference process, can be efficiently solved by inserting a novel neural network layer, namely the maximum subpath layer. We demonstrated the effectiveness of this method by comparison with a baseline of the action-recognition datasets extended for this task. Moreover, we provide information-theoretical insight into the proposed method.