 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3: Data Diversity Design for Systematic Generalization in Visual Question Answering
Sep 15, 2023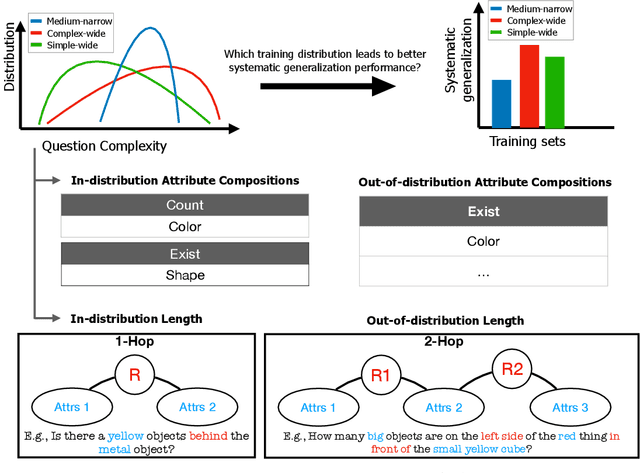


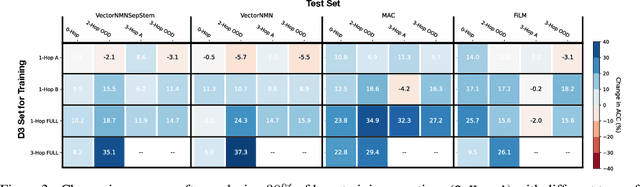
Systematic generalization is a crucial aspect of intelligence, which refers to the ability to generalize to novel tasks by combining known subtasks and concepts. One critical factor that has been shown to influence systematic generalization is the diversity of training data. However, diversity can be defined in various ways, as data have many factors of variation. A more granular understanding of how different aspects of data diversity affect systematic generalization is lacking. We present new evidence in the problem of Visual Question Answering (VQA) that reveals that the diversity of simple tasks (i.e. tasks formed by a few subtasks and concepts) plays a key role in achieving systematic generalization. This implies that it may not be essential to gather a large and varied number of complex tasks, which could be costly to obtain. We demonstrate that this result is independent of the similarity between the training and testing data and applies to well-known families of neural network architectures for VQA (i.e. monolithic architectures and neural module networks). Additionally, we observe that neural module networks leverage all forms of data diversity we evaluated, while monolithic architectures require more extensive amounts of data to do so. These findings provide a first step towards understanding the interactions between data diversity design, neural network architectures, and systematic generalization capabilities.
HICO-DET-SG and V-COCO-SG: New Data Splits to Evaluate Systematic Generalization in Human-Object Interaction Detection
May 17, 2023



Human-Object Interaction (HOI) detection is a task to predict interactions between humans and objects in an image. In real-world scenarios, HOI detection models are required systematic generalization, i.e., generalization to novel combinations of objects and interactions, because it is highly probable that the train data only cover a limited portion of all possible combinations. However, to our knowledge, no open benchmark or existing work evaluates the systematic generalization in HOI detection. To address this issue, we created two new sets of HOI detection data splits named HICO-DET-SG and V-COCO-SG based on HICO-DET and V-COCO datasets. We evaluated representative HOI detection models on the new data splits and observed large degradation in the test performances compared to those on the original datasets. This result shows that systematic generalization is a challenging goal in HOI detection. We hope our new data splits encourage more research toward this goal.
Transformer Module Networks for Systematic Generalization in Visual Question Answering
Jan 27, 2022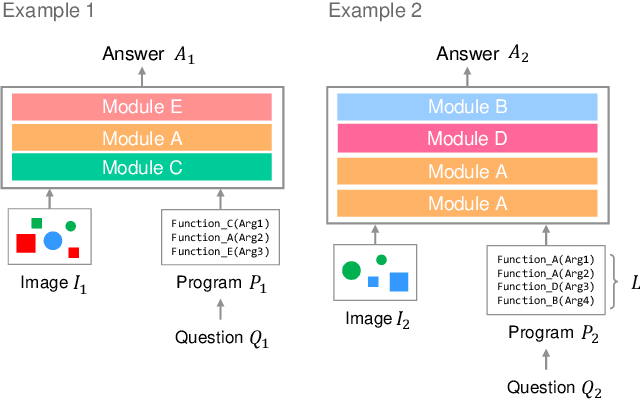
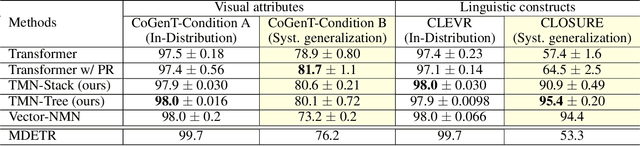
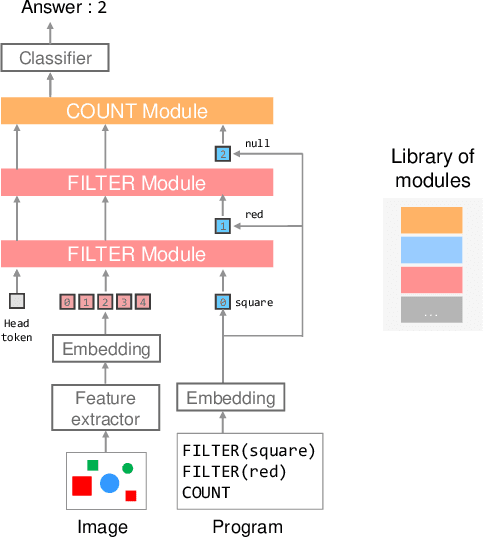

Transformer-based models achieve great performance on Visual Question Answering (VQA). However, when we evaluate them on systematic generalization, i.e., handling novel combinations of known concepts, their performance degrades. Neural Module Networks (NMNs) are a promising approach for systematic generalization that consists on composing modules, i.e., neural networks that tackle a sub-task. Inspired by Transformers and NMNs, we propose Transformer Module Network (TMN), a novel Transformer-based model for VQA that dynamically composes modules into a question-specific Transformer network. TMNs achieve state-of-the-art systematic generalization performance in three VQA datasets, namely, CLEVR-CoGenT, CLOSURE and GQA-SGL, in some cases improving more than 30% over standard Transformers.
Multimodal Explanations by Predicting Counterfactuality in Videos
Dec 04, 2018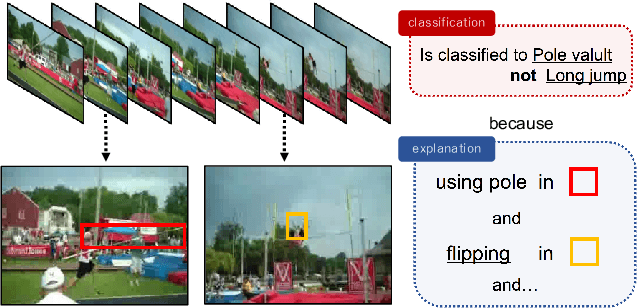
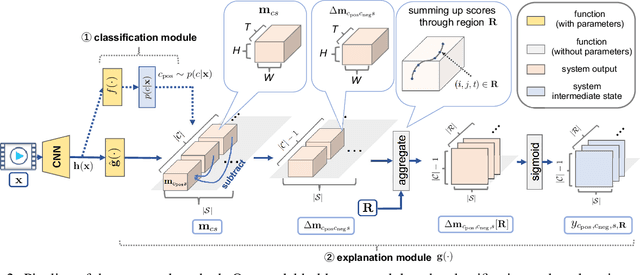
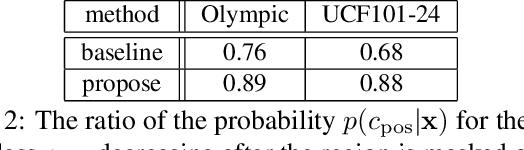
This study addresses generating counterfactual explanations with multimodal information. Our goal is not only to classify a video into a specific category, but also to provide explanations on why it is not predicted as part of a specific class with a combination of visual-linguistic information. Requirements that the expected output should satisfy are referred to as counterfactuality in this paper: (1) Compatibility of visual-linguistic explanations, and (2) Positiveness/negativeness for the specific positive/negative class. Exploiting a spatio-temporal region (tube) and an attribute as visual and linguistic explanations respectively, the explanation model is trained to predict the counterfactuality for possible combinations of multimodal information in a post-hoc manner. The optimization problem, which appears during the training/inference process, can be efficiently solved by inserting a novel neural network layer, namely the maximum subpath layer. We demonstrated the effectiveness of this method by comparison with a baseline of the action-recognition datasets extended for this task. Moreover, we provide information-theoretical insight into the proposed method.