 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on test proteins improves fitness, structure, and function prediction
Nov 04, 2024



Data scarcity and distribution shifts often hinder the ability of machine learning models to generalize when applied to proteins and other biological data. Self-supervised pre-training on large datasets is a common method to enhance generalization. However, striving to perform well on all possible proteins can limit model's capacity to excel on any specific one, even though practitioners are often most interested in accurate predictions for the individual protein they study. To address this limitation, we propose an orthogonal approach to achieve generalization. Building on the prevalence of self-supervised pre-training, we introduce a method for self-supervised fine-tuning at test time, allowing models to adapt to the test protein of interest on the fly and without requiring any additional data. We study our test-time training (TTT) method through the lens of perplexity minimization and show that it consistently enhances generalization across different models, their scales, and datasets. Notably, our method leads to new state-of-the-art results on the standard benchmark for protein fitness prediction, improves protein structure prediction for challenging targets, and enhances function prediction accuracy.
Revealing data leakage in protein interaction benchmarks
Apr 16, 2024


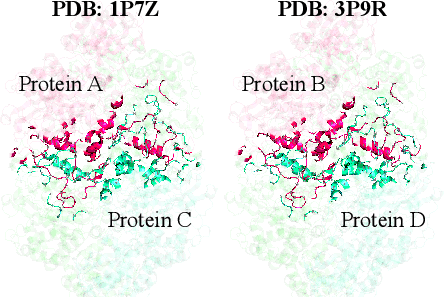
In recent years, there has been remarkable progress in machine learning for protein-protein interactions. However, prior work has predominantly focused on improving learning algorithms, with less attention paid to evaluation strategies and data preparation. Here, we demonstrate that further development of machine learning methods may be hindered by the quality of existing train-test splits. Specifically, we find that commonly used splitting strategies for protein complexes, based on protein sequence or metadata similarity, introduce major data leakage. This may result in overoptimistic evaluation of generalization, as well as unfair benchmarking of the models, biased towards assessing their overfitting capacity rather than practical utility. To overcome the data leakage, we recommend constructing data splits based on 3D structural similarity of protein-protein interfaces and suggest corresponding algorithms. We believe that addressing the data leakage problem is critical for further progress in this research area.
Learning to design protein-protein interactions with enhanced generalization
Oct 27, 2023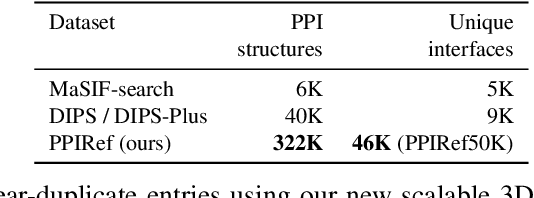
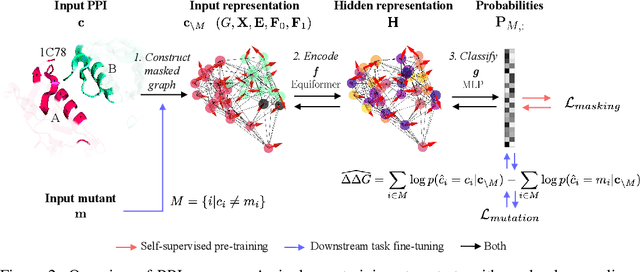

Discovering mutations enhancing protein-protein interactions (PPIs) is critical for advancing biomedical research and developing improved therapeutics. While machine learning approaches have substantially advanced the field, they often struggle to generalize beyond training data in practical scenarios. The contributions of this work are three-fold. First, we construct PPIRef, the largest and non-redundant dataset of 3D protein-protein interactions, enabling effective large-scale learning. Second, we leverage the PPIRef dataset to pre-train PPIformer, a new SE(3)-equivariant model generalizing across diverse protein-binder variants. We fine-tune PPIformer to predict effects of mutations on protein-protein interactions via a thermodynamically motivated adjustment of the pre-training loss function. Finally, we demonstrate the enhanced generalization of our new PPIformer approach by outperforming other state-of-the-art methods on new, non-leaking splits of standard labeled PPI mutational data and independent case studies optimizing a human antibody against SARS-CoV-2 and increasing the thrombolytic activity of staphylokinase.
Imitrob: Imitation Learning Dataset for Training and Evaluating 6D Object Pose Estimators
Sep 19, 2022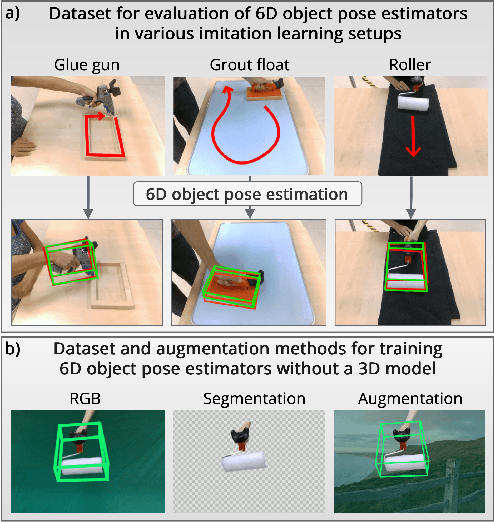


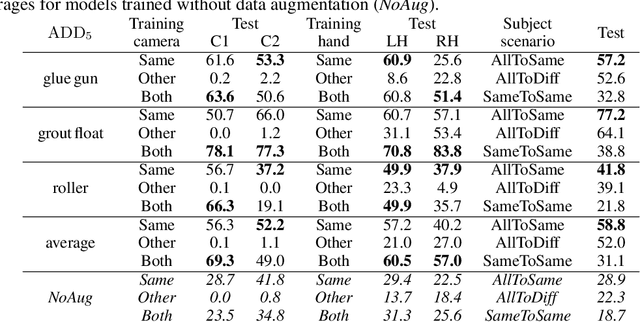
This paper introduces a dataset for training and evaluating methods for 6D pose estimation of hand-held tools in task demonstrations captured by a standard RGB camera. Despite the significant progress of 6D pose estimation methods, their performance is usually limited for heavily occluded objects, which is a common case in imitation learning where the object is typically partially occluded by the manipulating hand. Currently, there is a lack of datasets that would enable the development of robust 6D pose estimation methods for these conditions. To overcome this problem, we collect a new dataset (Imitrob) aimed at 6D pose estimation in imitation learning and other applications where a human holds a tool and performs a task. The dataset contains image sequences of three different tools and six manipulation tasks with two camera viewpoints, four human subjects, and left/right hand. Each image is accompanied by an accurate ground truth measurement of the 6D object pose, obtained by the HTC Vive motion tracking device. The use of the dataset is demonstrated by training and evaluating a recent 6D object pose estimation method (DOPE) in various setups. The dataset and code are publicly available at http://imitrob.ciirc.cvut.cz/imitrobdataset.php.
Estimating 3D Motion and Forces of Human-Object Interactions from Internet Videos
Nov 02, 2021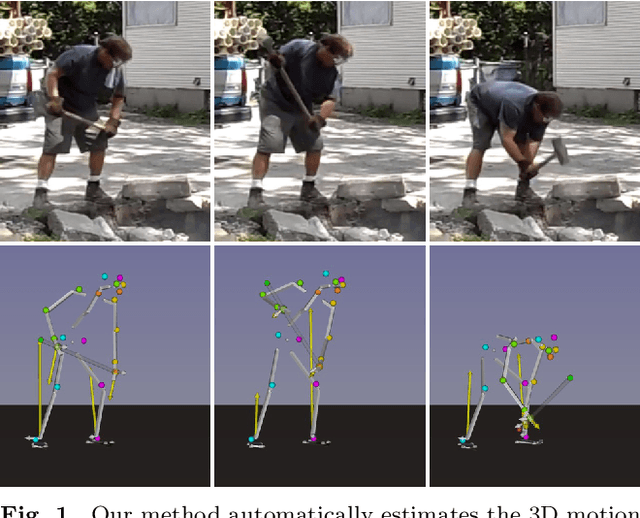

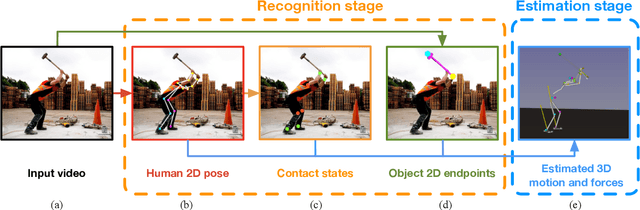

In this paper, we introduce a method to automatically reconstruct the 3D motion of a person interacting with an object from a single RGB video. Our method estimates the 3D poses of the person together with the object pose, the contact positions and the contact forces exerted on the human body. The main contributions of this work are three-fold. First, we introduce an approach to jointly estimate the motion and the actuation forces of the person on the manipulated object by modeling contacts and the dynamics of the interactions. This is cast as a large-scale trajectory optimization problem. Second, we develop a method to automatically recognize from the input video the 2D position and timing of contacts between the person and the object or the ground, thereby significantly simplifying the complexity of the optimization. Third, we validate our approach on a recent video+MoCap dataset capturing typical parkour actions, and demonstrate its performance on a new dataset of Internet videos showing people manipulating a variety of tools in unconstrained environments.
Is This The Right Place? Geometric-Semantic Pose Verification for Indoor Visual Localization
Sep 02, 2019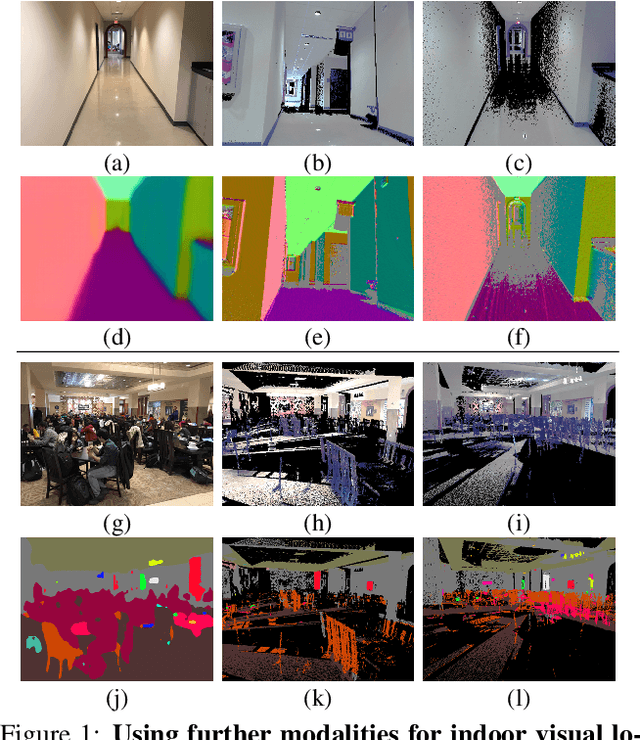
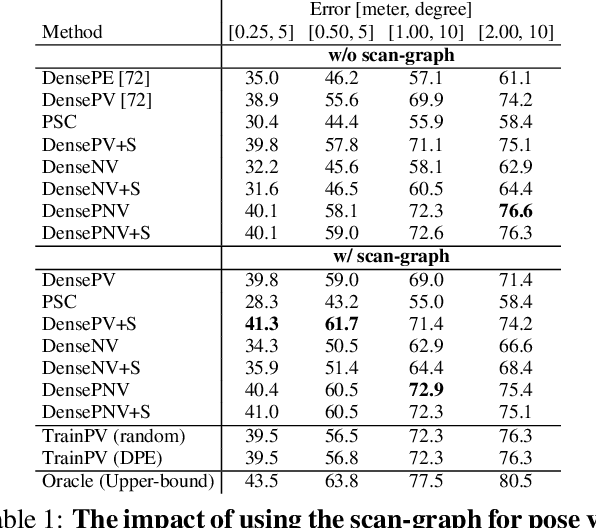
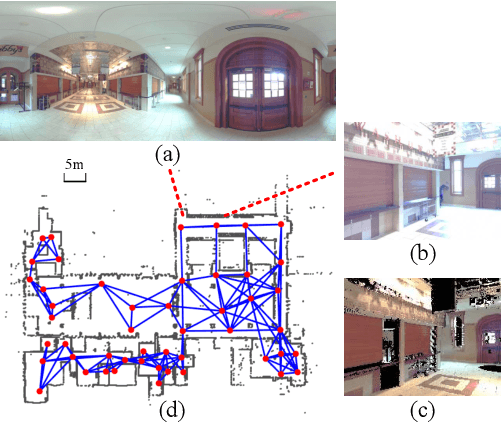
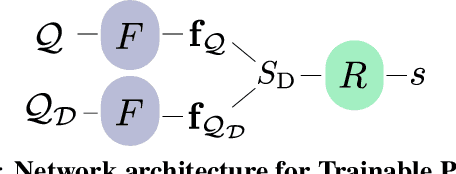
Visual localization in large and complex indoor scenes, dominated by weakly textured rooms and repeating geometric patterns, is a challenging problem with high practical relevance for applications such as Augmented Reality and robotics. To handle the ambiguities arising in this scenario, a common strategy is, first, to generate multiple estimates for the camera pose from which a given query image was taken. The pose with the largest geometric consistency with the query image, e.g., in the form of an inlier count, is then selected in a second stage. While a significant amount of research has concentrated on the first stage, there is considerably less work on the second stage. In this paper, we thus focus on pose verification. We show that combining different modalities, namely appearance, geometry, and semantics, considerably boosts pose verification and consequently pose accuracy. We develop multiple hand-crafted as well as a trainable approach to join into the geometric-semantic verification and show significant improvements over state-of-the-art on a very challenging indoor dataset.
Estimating 3D Motion and Forces of Person-Object Interactions from Monocular Video
Apr 04, 2019



In this paper, we introduce a method to automatically reconstruct the 3D motion of a person interacting with an object from a single RGB video. Our method estimates the 3D poses of the person and the object, contact positions, and forces and torques actuated by the human limbs. The main contributions of this work are three-fold. First, we introduce an approach to jointly estimate the motion and the actuation forces of the person on the manipulated object by modeling contacts and the dynamics of their interactions. This is cast as a large-scale trajectory optimization problem. Second, we develop a method to automatically recognize from the input video the position and timing of contacts between the person and the object or the ground, thereby significantly simplifying the complexity of the optimization. Third, we validate our approach on a recent MoCap dataset with ground truth contact forces and demonstrate its performance on a new dataset of Internet videos showing people manipulating a variety of tools in unconstrained environments.
Teaching robots to imitate a human with no on-teacher sensors. What are the key challenges?
Jan 24, 2019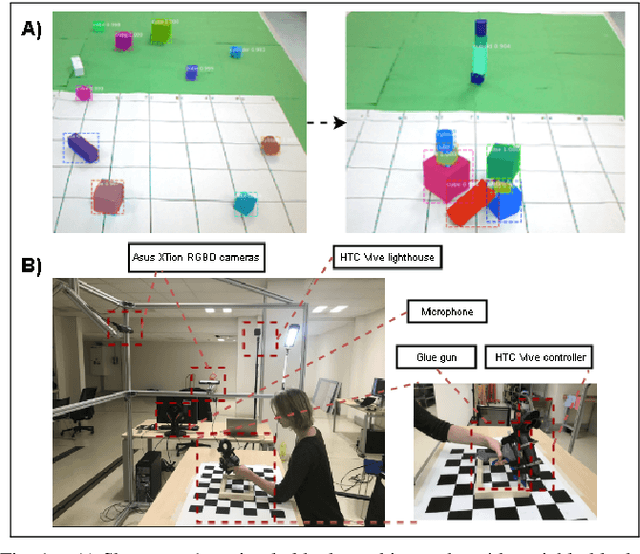



In this paper, we consider the problem of learning object manipulation tasks from human demonstration using RGB or RGB-D cameras. We highlight the key challenges in capturing sufficiently good data with no tracking devices - starting from sensor selection and accurate 6DoF pose estimation to natural language processing. In particular, we focus on two showcases: gluing task with a glue gun and simple block-stacking with variable blocks. Furthermore, we discuss how a linguistic description of the task could help to improve the accuracy of task description. We also present the whole architecture of our transfer of the imitated task to the simulated and real robot environment.
Predicting 1p19q Chromosomal Deletion of Low-Grade Gliomas from MR Images using Deep Learning
Nov 21, 2016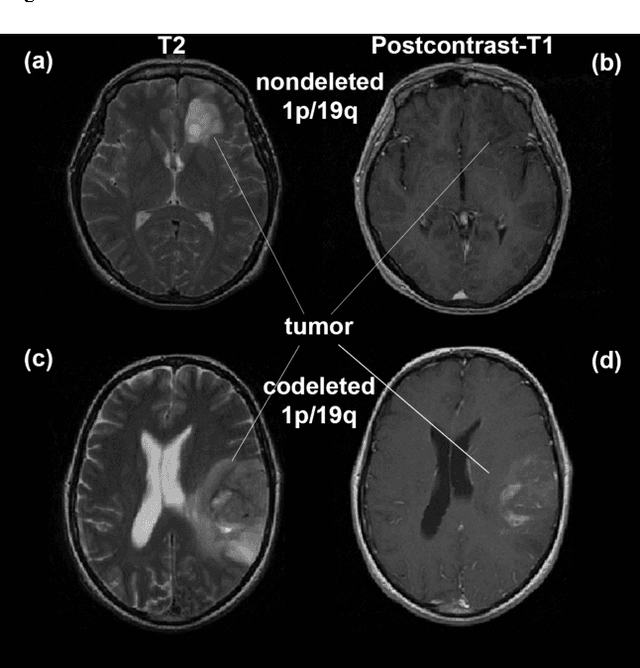
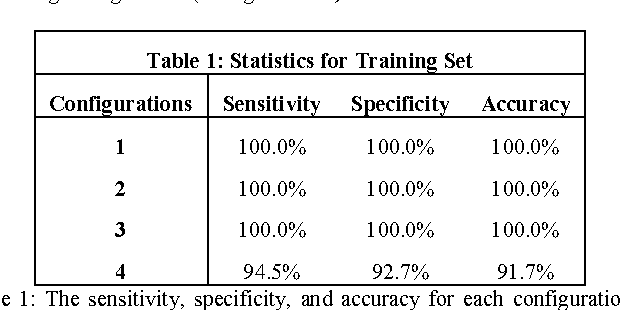
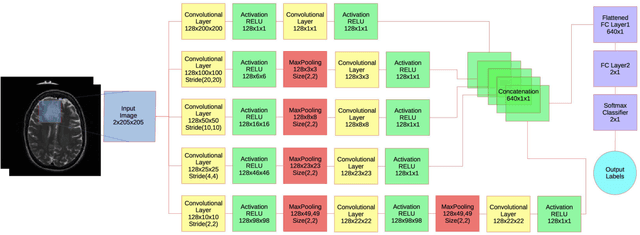
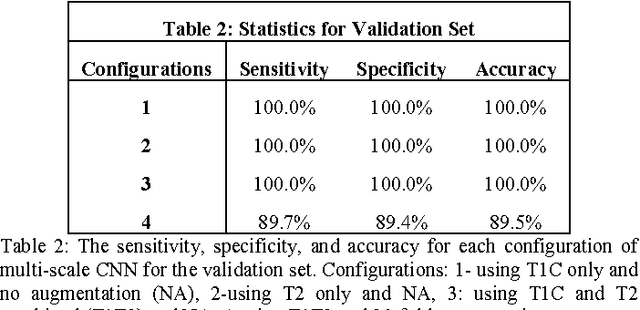
Objective: Several studies have associated codeletion of chromosome arms 1p/19q in low-grade gliomas (LGG) with positive response to treatment and longer progression free survival. Therefore, predicting 1p/19q status is crucial for effective treatment planning of LGG. In this study, we predict the 1p/19q status from MR images using convolutional neural networks (CNN), which could be a noninvasive alternative to surgical biopsy and histopathological analysis. Method: Our method consists of three main steps: image registration, tumor segmentation, and classification of 1p/19q status using CNN. We included a total of 159 LGG with 3 image slices each who had biopsy-proven 1p/19q status (57 nondeleted and 102 codeleted) and preoperative postcontrast-T1 (T1C) and T2 images. We divided our data into training, validation, and test sets. The training data was balanced for equal class probability and then augmented with iterations of random translational shift, rotation, and horizontal and vertical flips to increase the size of the training set. We shuffled and augmented the training data to counter overfitting in each epoch. Finally, we evaluated several configurations of a multi-scale CNN architecture until training and validation accuracies became consistent. Results: The results of the best performing configuration on the unseen test set were 93.3% (sensitivity), 82.22% (specificity), and 87.7% (accuracy). Conclusion: Multi-scale CNN with their self-learning capability provides promising results for predicting 1p/19q status noninvasively based on T1C and T2 images. Significance: Predicting 1p/19q status noninvasively from MR images would allow selecting effective treatment strategies for LGG patients without the need for surgical biopsy.