 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfeasible optimization problems and the hierarchical augmented Lagrangian method in imitation learning
May 30, 2026Imitation learning (IL) is an effective approach to train complex robotics policies. Recent works have introduced hard constraints into imitation-learning optimization problems to ensure safety, stability, and robustness of the learned policy. However, we argue that these constraints are sometimes infeasible, which can lead to unstable or difficult training dynamics. We study a simple remedy for such situations based on recent theoretical results on the augmented Lagrangian method in infeasible settings. We show that our approach drives the learned policy toward the solution of a closest-feasible constrained IL problem with desirable properties. The method is illustrated on a toy driving example with a total-acceleration constraint and pedestrian-safety constraints, a setting in which infeasibility can naturally arise while still allowing a safe learned policy.
Survival Reinforcement Learning: Toward Scalable Self-Supervised RL
May 29, 2026While self-supervised Contrastive Reinforcement Learning (CRL) has shown remarkable depth-scaling capabilities, successfully using networks over 64 layers, scaled CRL still struggles with long-horizon goal-conditioned planning due to the uniformity-tolerance dilemma inherent in contrastive losses. We introduce Survival Reinforcement Learning (SRL), an online classification-based alternative that extends the survival value learning framework by maximizing the agent's dwell time at target goals. SRL bypasses the structural constraints of CRL and mitigates the "bang-bang" control solutions inherent to survival frameworks, which often induce undesirable behavior in complex dynamical systems. Evaluated across diverse robotic benchmarks, scaled SRL matches state-of-the-art CRL on manipulation tasks and outperforms it by 2x to 8x on stable, long-horizon locomotion tasks. Our results provide strong additional evidence that classification-based methods may serve as a key primitive in the broader effort to scale reinforcement learning.
Accelerating trajectory optimization with Sobolev-trained diffusion policies
Apr 21, 2026Trajectory Optimization (TO) solvers exploit known system dynamics to compute locally optimal trajectories through iterative improvements. A downside is that each new problem instance is solved independently; therefore, convergence speed and quality of the solution found depend on the initial trajectory proposed. To improve efficiency, a natural approach is to warm-start TO with initial guesses produced by a learned policy trained on trajectories previously generated by the solver. Diffusion-based policies have recently emerged as expressive imitation learning models, making them promising candidates for this role. Yet, a counterintuitive challenge comes from the local optimality of TO demonstrations: when a policy is rolled out, small non-optimal deviations may push it into situations not represented in the training data, triggering compounding errors over long horizons. In this work, we focus on learning-based warm-starting for gradient-based TO solvers that also provide feedback gains. Exploiting this specificity, we derive a first-order loss for Sobolev learning of diffusion-based policies using both trajectories and feedback gains. Through comprehensive experiments, we demonstrate that the resulting policy avoids compounding errors, and so can learn from very few trajectories to provide initial guesses reducing solving time by $2\times$ to $20 \times$. Incorporating first-order information enables predictions with fewer diffusion steps, reducing inference latency.
SVL: Goal-Conditioned Reinforcement Learning as Survival Learning
Apr 19, 2026Standard approaches to goal-conditioned reinforcement learning (GCRL) that rely on temporal-difference learning can be unstable and sample-inefficient due to bootstrapping. While recent work has explored contrastive and supervised formulations to improve stability, we present a probabilistic alternative, called survival value learning (SVL), that reframes GCRL as a survival learning problem by modeling the time-to-goal from each state as a probability distribution. This structured distributional Monte Carlo perspective yields a closed-form identity that expresses the goal-conditioned value function as a discounted sum of survival probabilities, enabling value estimation via a hazard model trained via maximum likelihood on both event and right-censored trajectories. We introduce three practical value estimators, including finite-horizon truncation and two binned infinite-horizon approximations to capture long-horizon objectives. Experiments on offline GCRL benchmarks show that SVL combined with hierarchical actors matches or surpasses strong hierarchical TD and Monte Carlo baselines, excelling on complex, long-horizon tasks.
Constrained Sampling to Guide Universal Manipulation RL
Feb 09, 2026We consider how model-based solvers can be leveraged to guide training of a universal policy to control from any feasible start state to any feasible goal in a contact-rich manipulation setting. While Reinforcement Learning (RL) has demonstrated its strength in such settings, it may struggle to sufficiently explore and discover complex manipulation strategies, especially in sparse-reward settings. Our approach is based on the idea of a lower-dimensional manifold of feasible, likely-visited states during such manipulation and to guide RL with a sampler from this manifold. We propose Sample-Guided RL, which uses model-based constraint solvers to efficiently sample feasible configurations (satisfying differentiable collision, contact, and force constraints) and leverage them to guide RL for universal (goal-conditioned) manipulation policies. We study using this data directly to bias state visitation, as well as using black-box optimization of open-loop trajectories between random configurations to impose a state bias and optionally add a behavior cloning loss. In a minimalistic double sphere manipulation setting, Sample-Guided RL discovers complex manipulation strategies and achieves high success rates in reaching any statically stable state. In a more challenging panda arm setting, our approach achieves a significant success rate over a near-zero baseline, and demonstrates a breadth of complex whole-body-contact manipulation strategies.
Variance-Reduced Model Predictive Path Integral via Quadratic Model Approximation
Feb 03, 2026Sampling-based controllers, such as Model Predictive Path Integral (MPPI) methods, offer substantial flexibility but often suffer from high variance and low sample efficiency. To address these challenges, we introduce a hybrid variance-reduced MPPI framework that integrates a prior model into the sampling process. Our key insight is to decompose the objective function into a known approximate model and a residual term. Since the residual captures only the discrepancy between the model and the objective, it typically exhibits a smaller magnitude and lower variance than the original objective. Although this principle applies to general modeling choices, we demonstrate that adopting a quadratic approximation enables the derivation of a closed-form, model-guided prior that effectively concentrates samples in informative regions. Crucially, the framework is agnostic to the source of geometric information, allowing the quadratic model to be constructed from exact derivatives, structural approximations (e.g., Gauss- or Quasi-Newton), or gradient-free randomized smoothing. We validate the approach on standard optimization benchmarks, a nonlinear, underactuated cart-pole control task, and a contact-rich manipulation problem with non-smooth dynamics. Across these domains, we achieve faster convergence and superior performance in low-sample regimes compared to standard MPPI. These results suggest that the method can make sample-based control strategies more practical in scenarios where obtaining samples is expensive or limited.
Frictional Contact Solving for Material Point Method
Feb 02, 2026Accurately handling contact with friction remains a core bottleneck for Material Point Method (MPM), from reliable contact point detection to enforcing frictional contact laws (non-penetration, Coulomb friction, and maximum dissipation principle). In this paper, we introduce a frictional-contact pipeline for implicit MPM that is both precise and robust. During the collision detection phase, contact points are localized with particle-centric geometric primitives; during the contact resolution phase, we cast frictional contact as a Nonlinear Complementarity Problem (NCP) over contact impulses and solve it with an Alternating Direction Method of Multipliers (ADMM) scheme. Crucially, the formulation reuses the same implicit MPM linearization, yielding efficiency and numerical stability. The method integrates seamlessly into the implicit MPM loop and is agnostic to modeling choices, including material laws, interpolation functions, and transfer schemes. We evaluate it across seven representative scenes that span elastic and elasto-plastic responses, simple and complex deformable geometries, and a wide range of contact conditions. Overall, the proposed method enables accurate contact localization, reliable frictional handling, and broad generality, making it a practical solution for MPM-based simulations in robotics and related domains.
KernelSOS for Global Sampling-Based Optimal Control and Estimation via Semidefinite Programming
Jul 23, 2025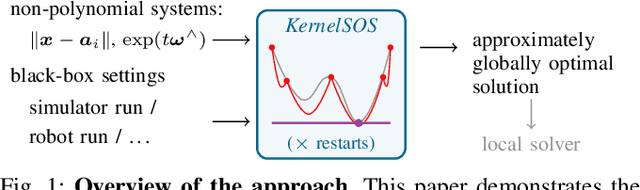
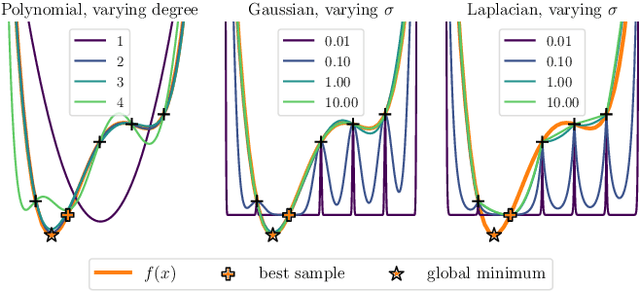
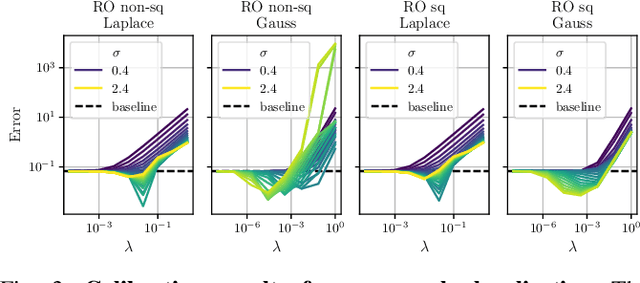
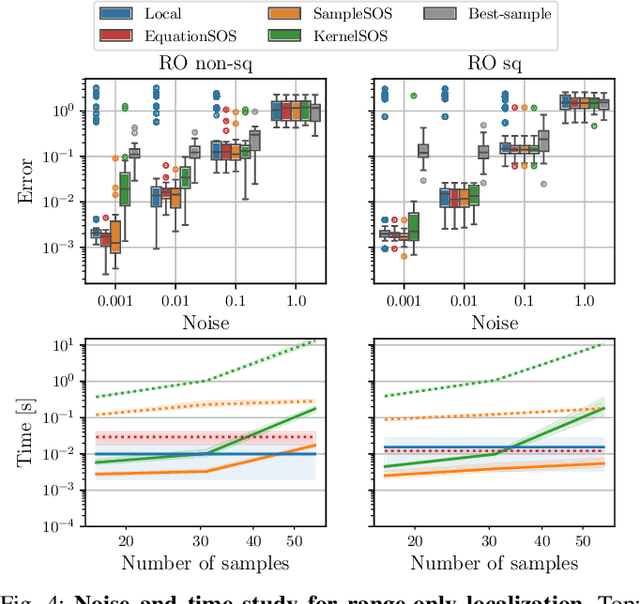
Global optimization has gained attraction over the past decades, thanks to the development of both theoretical foundations and efficient numerical routines to cope with optimization problems of various complexities. Among recent methods, Kernel Sum of Squares (KernelSOS) appears as a powerful framework, leveraging the potential of sum of squares methods from the polynomial optimization community with the expressivity of kernel methods widely used in machine learning. This paper applies the kernel sum of squares framework for solving control and estimation problems, which exhibit poor local minima. We demonstrate that KernelSOS performs well on a selection of problems from both domains. In particular, we show that KernelSOS is competitive with other sum of squares approaches on estimation problems, while being applicable to non-polynomial and non-parametric formulations. The sample-based nature of KernelSOS allows us to apply it to trajectory optimization problems with an integrated simulator treated as a black box, both as a standalone method and as a powerful initialization method for local solvers, facilitating the discovery of better solutions.
Multi-step manipulation task and motion planning guided by video demonstration
May 13, 2025


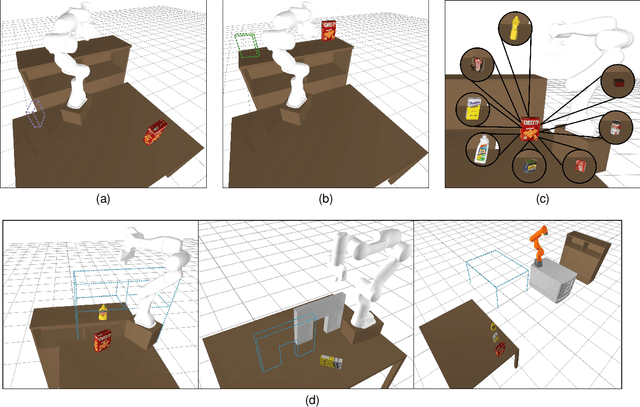
This work aims to leverage instructional video to solve complex multi-step task-and-motion planning tasks in robotics. Towards this goal, we propose an extension of the well-established Rapidly-Exploring Random Tree (RRT) planner, which simultaneously grows multiple trees around grasp and release states extracted from the guiding video. Our key novelty lies in combining contact states and 3D object poses extracted from the guiding video with a traditional planning algorithm that allows us to solve tasks with sequential dependencies, for example, if an object needs to be placed at a specific location to be grasped later. We also investigate the generalization capabilities of our approach to go beyond the scene depicted in the instructional video. To demonstrate the benefits of the proposed video-guided planning approach, we design a new benchmark with three challenging tasks: (I) 3D re-arrangement of multiple objects between a table and a shelf, (ii) multi-step transfer of an object through a tunnel, and (iii) transferring objects using a tray similar to a waiter transfers dishes. We demonstrate the effectiveness of our planning algorithm on several robots, including the Franka Emika Panda and the KUKA KMR iiwa. For a seamless transfer of the obtained plans to the real robot, we develop a trajectory refinement approach formulated as an optimal control problem (OCP).
Optimal Control of Walkers with Parallel Actuation
Apr 01, 2025
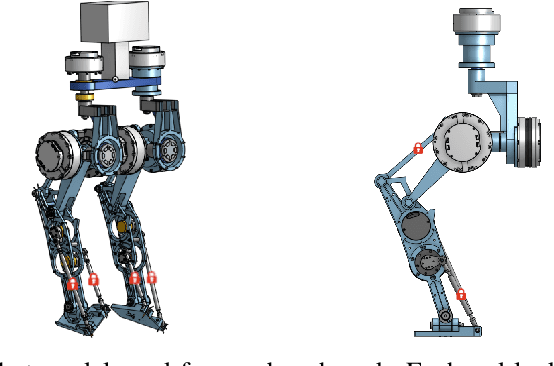

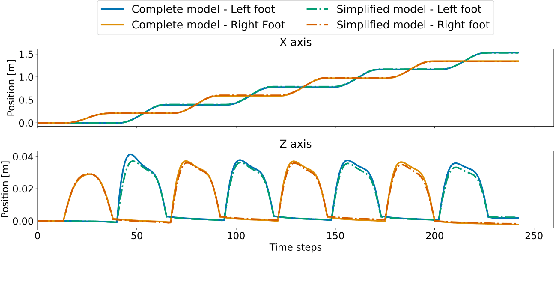
Legged robots with closed-loop kinematic chains are increasingly prevalent due to their increased mobility and efficiency. Yet, most motion generation methods rely on serial-chain approximations, sidestepping their specific constraints and dynamics. This leads to suboptimal motions and limits the adaptability of these methods to diverse kinematic structures. We propose a comprehensive motion generation method that explicitly incorporates closed-loop kinematics and their associated constraints in an optimal control problem, integrating kinematic closure conditions and their analytical derivatives. This allows the solver to leverage the non-linear transmission effects inherent to closed-chain mechanisms, reducing peak actuator efforts and expanding their effective operating range. Unlike previous methods, our framework does not require serial approximations, enabling more accurate and efficient motion strategies. We also are able to generate the motion of more complex robots for which an approximate serial chain does not exist. We validate our approach through simulations and experiments, demonstrating superior performance in complex tasks such as rapid locomotion and stair negotiation. This method enhances the capabilities of current closed-loop robots and broadens the design space for future kinematic architectures.