 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarm-Starting Collision-Free Model Predictive Control With Object-Centric Diffusion
Jan 06, 2026Acting in cluttered environments requires predicting and avoiding collisions while still achieving precise control. Conventional optimization-based controllers can enforce physical constraints, but they struggle to produce feasible solutions quickly when many obstacles are present. Diffusion models can generate diverse trajectories around obstacles, yet prior approaches lacked a general and efficient way to condition them on scene structure. In this paper, we show that combining diffusion-based warm-starting conditioned with a latent object-centric representation of the scene and with a collision-aware model predictive controller (MPC) yields reliable and efficient motion generation under strict time limits. Our approach conditions a diffusion transformer on the system state, task, and surroundings, using an object-centric slot attention mechanism to provide a compact obstacle representation suitable for control. The sampled trajectories are refined by an optimal control problem that enforces rigid-body dynamics and signed-distance collision constraints, producing feasible motions in real time. On benchmark tasks, this hybrid method achieved markedly higher success rates and lower latency than sampling-based planners or either component alone. Real-robot experiments with a torque-controlled Panda confirm reliable and safe execution with MPC.
Multi-step manipulation task and motion planning guided by video demonstration
May 13, 2025This work aims to leverage instructional video to solve complex multi-step task-and-motion planning tasks in robotics. Towards this goal, we propose an extension of the well-established Rapidly-Exploring Random Tree (RRT) planner, which simultaneously grows multiple trees around grasp and release states extracted from the guiding video. Our key novelty lies in combining contact states and 3D object poses extracted from the guiding video with a traditional planning algorithm that allows us to solve tasks with sequential dependencies, for example, if an object needs to be placed at a specific location to be grasped later. We also investigate the generalization capabilities of our approach to go beyond the scene depicted in the instructional video. To demonstrate the benefits of the proposed video-guided planning approach, we design a new benchmark with three challenging tasks: (I) 3D re-arrangement of multiple objects between a table and a shelf, (ii) multi-step transfer of an object through a tunnel, and (iii) transferring objects using a tray similar to a waiter transfers dishes. We demonstrate the effectiveness of our planning algorithm on several robots, including the Franka Emika Panda and the KUKA KMR iiwa. For a seamless transfer of the obtained plans to the real robot, we develop a trajectory refinement approach formulated as an optimal control problem (OCP).
Extended URDF: Accounting for parallel mechanism in robot description
Apr 10, 2025Robotic designs played an important role in recent advances by providing powerful robots with complex mechanics. Many recent systems rely on parallel actuation to provide lighter limbs and allow more complex motion. However, these emerging architectures fall outside the scope of most used description formats, leading to difficulties when designing, storing, and sharing the models of these systems. This paper introduces an extension to the widely used Unified Robot Description Format (URDF) to support closed-loop kinematic structures. Our approach relies on augmenting URDF with minimal additional information to allow more efficient modeling of complex robotic systems while maintaining compatibility with existing design and simulation frameworks. This method sets the basic requirement for a description format to handle parallel mechanisms efficiently. We demonstrate the applicability of our approach by providing an open-source collection of parallel robots, along with tools for generating and parsing this extended description format. The proposed extension simplifies robot modeling, reduces redundancy, and improves usability for advanced robotic applications.
Optimal Control of Walkers with Parallel Actuation
Apr 01, 2025Legged robots with closed-loop kinematic chains are increasingly prevalent due to their increased mobility and efficiency. Yet, most motion generation methods rely on serial-chain approximations, sidestepping their specific constraints and dynamics. This leads to suboptimal motions and limits the adaptability of these methods to diverse kinematic structures. We propose a comprehensive motion generation method that explicitly incorporates closed-loop kinematics and their associated constraints in an optimal control problem, integrating kinematic closure conditions and their analytical derivatives. This allows the solver to leverage the non-linear transmission effects inherent to closed-chain mechanisms, reducing peak actuator efforts and expanding their effective operating range. Unlike previous methods, our framework does not require serial approximations, enabling more accurate and efficient motion strategies. We also are able to generate the motion of more complex robots for which an approximate serial chain does not exist. We validate our approach through simulations and experiments, demonstrating superior performance in complex tasks such as rapid locomotion and stair negotiation. This method enhances the capabilities of current closed-loop robots and broadens the design space for future kinematic architectures.
Control of Humanoid Robots with Parallel Mechanisms using Kinematic Actuation Models
Mar 28, 2025Inspired by the mechanical design of Cassie, several recently released humanoid robots are using actuator configuration in which the motor is displaced from the joint location to optimize the leg inertia. This in turn induces a non linearity in the reduction ratio of the transmission which is often neglected when computing the robot motion (e.g. by trajectory optimization or reinforcement learning) and only accounted for at control time. This paper proposes an analytical method to efficiently handle this non-linearity. Using this actuation model, we demonstrate that we can leverage the dynamic abilities of the non-linear transmission while only modeling the inertia of the main serial chain of the leg, without approximating the motor capabilities nor the joint range. Based on analytical inverse kinematics, our method does not need any numerical routines dedicated to the closed-kinematics actuation, hence leading to very efficient computations. Our study focuses on two mechanisms widely used in recent humanoid robots; the four bar knee linkage as well as a parallel 2 DoF ankle mechanism. We integrate these models inside optimization based (DDP) and learning (PPO) control approaches. A comparison of our model against a simplified model that completely neglects closed chains is then shown in simulation.
Infinite-Horizon Value Function Approximation for Model Predictive Control
Feb 10, 2025Model Predictive Control has emerged as a popular tool for robots to generate complex motions. However, the real-time requirement has limited the use of hard constraints and large preview horizons, which are necessary to ensure safety and stability. In practice, practitioners have to carefully design cost functions that can imitate an infinite horizon formulation, which is tedious and often results in local minima. In this work, we study how to approximate the infinite horizon value function of constrained optimal control problems with neural networks using value iteration and trajectory optimization. Furthermore, we demonstrate how using this value function approximation as a terminal cost provides global stability to the model predictive controller. The approach is validated on two toy problems and a real-world scenario with online obstacle avoidance on an industrial manipulator where the value function is conditioned to the goal and obstacle.
Reinforcement Learning from Wild Animal Videos
Dec 05, 2024



We propose to learn legged robot locomotion skills by watching thousands of wild animal videos from the internet, such as those featured in nature documentaries. Indeed, such videos offer a rich and diverse collection of plausible motion examples, which could inform how robots should move. To achieve this, we introduce Reinforcement Learning from Wild Animal Videos (RLWAV), a method to ground these motions into physical robots. We first train a video classifier on a large-scale animal video dataset to recognize actions from RGB clips of animals in their natural habitats. We then train a multi-skill policy to control a robot in a physics simulator, using the classification score of a third-person camera capturing videos of the robot's movements as a reward for reinforcement learning. Finally, we directly transfer the learned policy to a real quadruped Solo. Remarkably, despite the extreme gap in both domain and embodiment between animals in the wild and robots, our approach enables the policy to learn diverse skills such as walking, jumping, and keeping still, without relying on reference trajectories nor skill-specific rewards.
Parallel and Proximal Linear-Quadratic Methods for Real-Time Constrained Model-Predictive Control
May 15, 2024


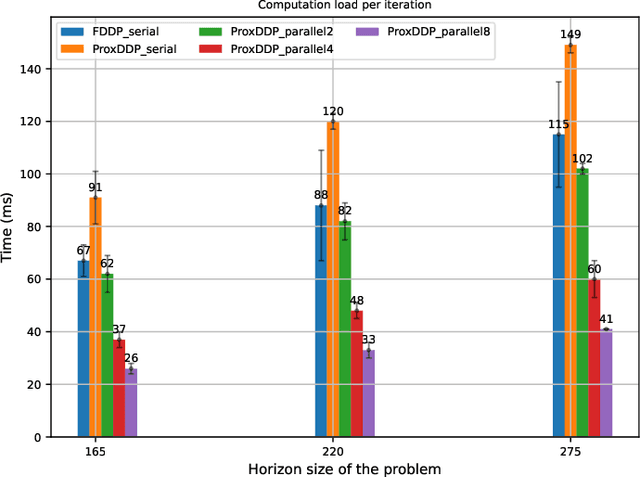
-Recent strides in model predictive control (MPC)underscore a dependence on numerical advancements to efficientlyand accurately solve large-scale problems. Given the substantialnumber of variables characterizing typical whole-body optimalcontrol (OC) problems -often numbering in the thousands-exploiting the sparse structure of the numerical problem becomescrucial to meet computational demands, typically in the range ofa few milliseconds. A fundamental building block for computingNewton or Sequential Quadratic Programming (SQP) steps indirect optimal control methods involves addressing the linearquadratic regulator (LQR) problem. This paper concentrateson equality-constrained problems featuring implicit systemdynamics and dual regularization, a characteristic found inadvanced interior-point or augmented Lagrangian solvers. Here,we introduce a parallel algorithm designed for solving an LQRproblem with dual regularization. Leveraging a rewriting of theLQR recursion through block elimination, we first enhanced theefficiency of the serial algorithm, then subsequently generalized itto handle parametric problems. This extension enables us to splitdecision variables and solve multiple subproblems concurrently.Our algorithm is implemented in our nonlinear numerical optimalcontrol library ALIGATOR. It showcases improved performanceover previous serial formulations and we validate its efficacy bydeploying it in the model predictive control of a real quadrupedrobot. This paper follows up from our prior work on augmentedLagrangian methods for numerical optimal control with implicitdynamics and constraints.
CaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning
Mar 27, 2024
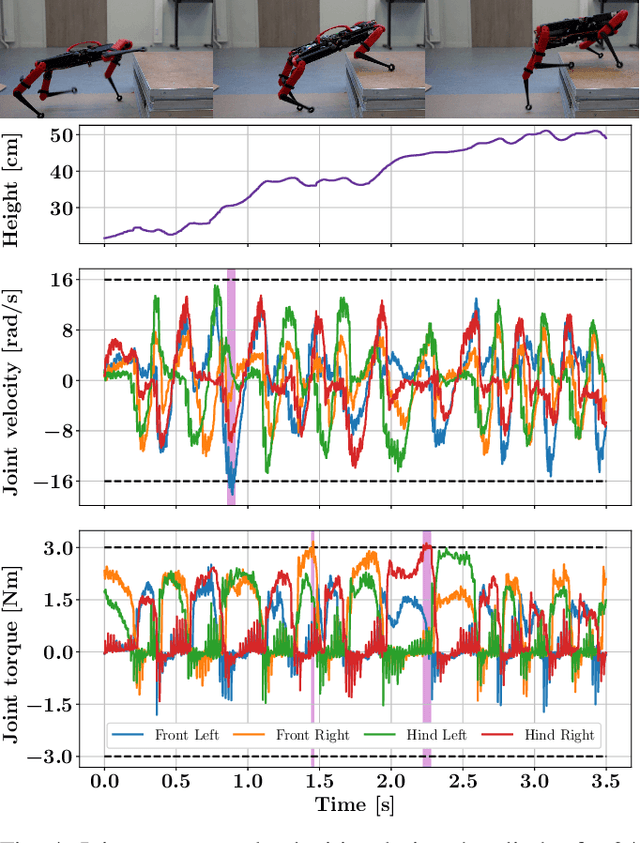


Deep Reinforcement Learning (RL) has demonstrated impressive results in solving complex robotic tasks such as quadruped locomotion. Yet, current solvers fail to produce efficient policies respecting hard constraints. In this work, we advocate for integrating constraints into robot learning and present Constraints as Terminations (CaT), a novel constrained RL algorithm. Departing from classical constrained RL formulations, we reformulate constraints through stochastic terminations during policy learning: any violation of a constraint triggers a probability of terminating potential future rewards the RL agent could attain. We propose an algorithmic approach to this formulation, by minimally modifying widely used off-the-shelf RL algorithms in robot learning (such as Proximal Policy Optimization). Our approach leads to excellent constraint adherence without introducing undue complexity and computational overhead, thus mitigating barriers to broader adoption. Through empirical evaluation on the real quadruped robot Solo crossing challenging obstacles, we demonstrate that CaT provides a compelling solution for incorporating constraints into RL frameworks. Videos and code are available at https://constraints-as-terminations.github.io.
Visually Guided Model Predictive Robot Control via 6D Object Pose Localization and Tracking
Nov 09, 2023



The objective of this work is to enable manipulation tasks with respect to the 6D pose of a dynamically moving object using a camera mounted on a robot. Examples include maintaining a constant relative 6D pose of the robot arm with respect to the object, grasping the dynamically moving object, or co-manipulating the object together with a human. Fast and accurate 6D pose estimation is crucial to achieve smooth and stable robot control in such situations. The contributions of this work are three fold. First, we propose a new visual perception module that asynchronously combines accurate learning-based 6D object pose localizer and a high-rate model-based 6D pose tracker. The outcome is a low-latency accurate and temporally consistent 6D object pose estimation from the input video stream at up to 120 Hz. Second, we develop a visually guided robot arm controller that combines the new visual perception module with a torque-based model predictive control algorithm. Asynchronous combination of the visual and robot proprioception signals at their corresponding frequencies results in stable and robust 6D object pose guided robot arm control. Third, we experimentally validate the proposed approach on a challenging 6D pose estimation benchmark and demonstrate 6D object pose-guided control with dynamically moving objects on a real 7 DoF Franka Emika Panda robot.