 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Reinforcement Learning from Wild Animal Videos
Dec 05, 2024



We propose to learn legged robot locomotion skills by watching thousands of wild animal videos from the internet, such as those featured in nature documentaries. Indeed, such videos offer a rich and diverse collection of plausible motion examples, which could inform how robots should move. To achieve this, we introduce Reinforcement Learning from Wild Animal Videos (RLWAV), a method to ground these motions into physical robots. We first train a video classifier on a large-scale animal video dataset to recognize actions from RGB clips of animals in their natural habitats. We then train a multi-skill policy to control a robot in a physics simulator, using the classification score of a third-person camera capturing videos of the robot's movements as a reward for reinforcement learning. Finally, we directly transfer the learned policy to a real quadruped Solo. Remarkably, despite the extreme gap in both domain and embodiment between animals in the wild and robots, our approach enables the policy to learn diverse skills such as walking, jumping, and keeping still, without relying on reference trajectories nor skill-specific rewards.
CaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning
Mar 27, 2024
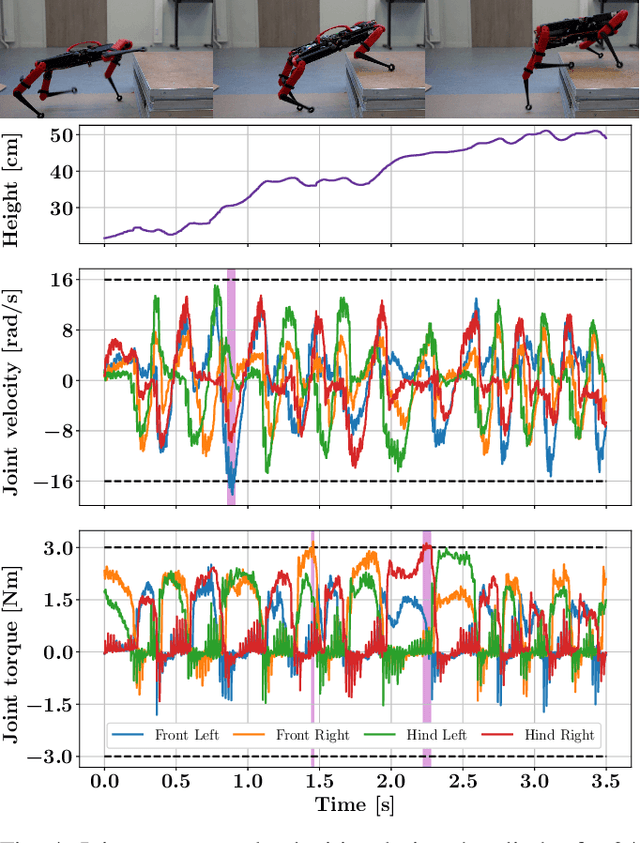


Deep Reinforcement Learning (RL) has demonstrated impressive results in solving complex robotic tasks such as quadruped locomotion. Yet, current solvers fail to produce efficient policies respecting hard constraints. In this work, we advocate for integrating constraints into robot learning and present Constraints as Terminations (CaT), a novel constrained RL algorithm. Departing from classical constrained RL formulations, we reformulate constraints through stochastic terminations during policy learning: any violation of a constraint triggers a probability of terminating potential future rewards the RL agent could attain. We propose an algorithmic approach to this formulation, by minimally modifying widely used off-the-shelf RL algorithms in robot learning (such as Proximal Policy Optimization). Our approach leads to excellent constraint adherence without introducing undue complexity and computational overhead, thus mitigating barriers to broader adoption. Through empirical evaluation on the real quadruped robot Solo crossing challenging obstacles, we demonstrate that CaT provides a compelling solution for incorporating constraints into RL frameworks. Videos and code are available at https://constraints-as-terminations.github.io.
Learning Video-Conditioned Policies for Unseen Manipulation Tasks
May 10, 2023The ability to specify robot commands by a non-expert user is critical for building generalist agents capable of solving a large variety of tasks. One convenient way to specify the intended robot goal is by a video of a person demonstrating the target task. While prior work typically aims to imitate human demonstrations performed in robot environments, here we focus on a more realistic and challenging setup with demonstrations recorded in natural and diverse human environments. We propose Video-conditioned Policy learning (ViP), a data-driven approach that maps human demonstrations of previously unseen tasks to robot manipulation skills. To this end, we learn our policy to generate appropriate actions given current scene observations and a video of the target task. To encourage generalization to new tasks, we avoid particular tasks during training and learn our policy from unlabelled robot trajectories and corresponding robot videos. Both robot and human videos in our framework are represented by video embeddings pre-trained for human action recognition. At test time we first translate human videos to robot videos in the common video embedding space, and then use resulting embeddings to condition our policies. Notably, our approach enables robot control by human demonstrations in a zero-shot manner, i.e., without using robot trajectories paired with human instructions during training. We validate our approach on a set of challenging multi-task robot manipulation environments and outperform state of the art. Our method also demonstrates excellent performance in a new challenging zero-shot setup where no paired data is used during training.
Goal-Conditioned Reinforcement Learning with Imagined Subgoals
Jul 01, 2021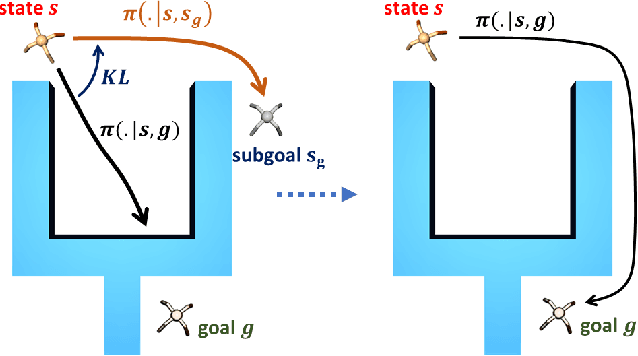
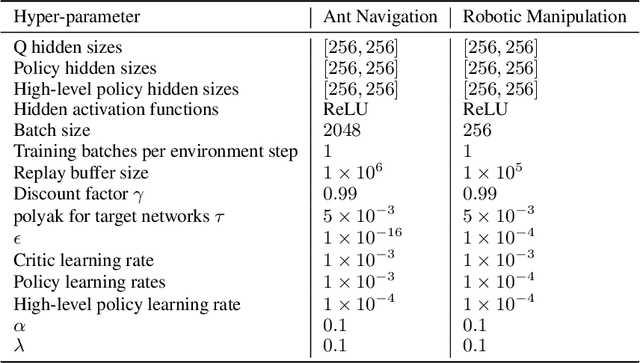
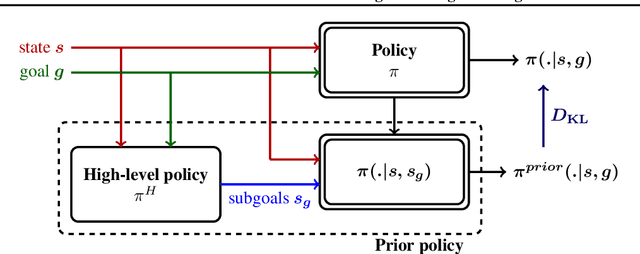

Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don't require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.