 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning
Mar 27, 2024
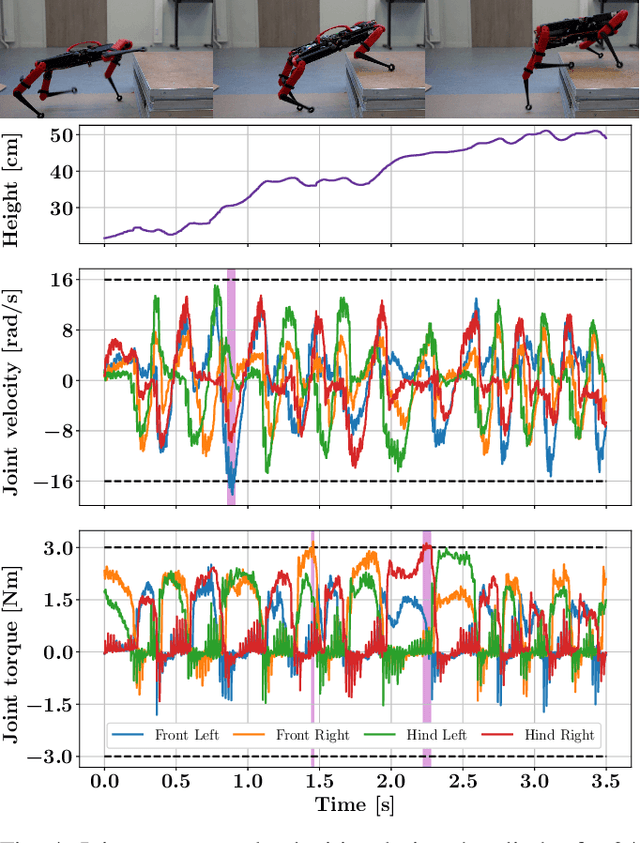


Deep Reinforcement Learning (RL) has demonstrated impressive results in solving complex robotic tasks such as quadruped locomotion. Yet, current solvers fail to produce efficient policies respecting hard constraints. In this work, we advocate for integrating constraints into robot learning and present Constraints as Terminations (CaT), a novel constrained RL algorithm. Departing from classical constrained RL formulations, we reformulate constraints through stochastic terminations during policy learning: any violation of a constraint triggers a probability of terminating potential future rewards the RL agent could attain. We propose an algorithmic approach to this formulation, by minimally modifying widely used off-the-shelf RL algorithms in robot learning (such as Proximal Policy Optimization). Our approach leads to excellent constraint adherence without introducing undue complexity and computational overhead, thus mitigating barriers to broader adoption. Through empirical evaluation on the real quadruped robot Solo crossing challenging obstacles, we demonstrate that CaT provides a compelling solution for incorporating constraints into RL frameworks. Videos and code are available at https://constraints-as-terminations.github.io.
Perceptive Locomotion through Whole-Body MPC and Optimal Region Selection
May 15, 2023


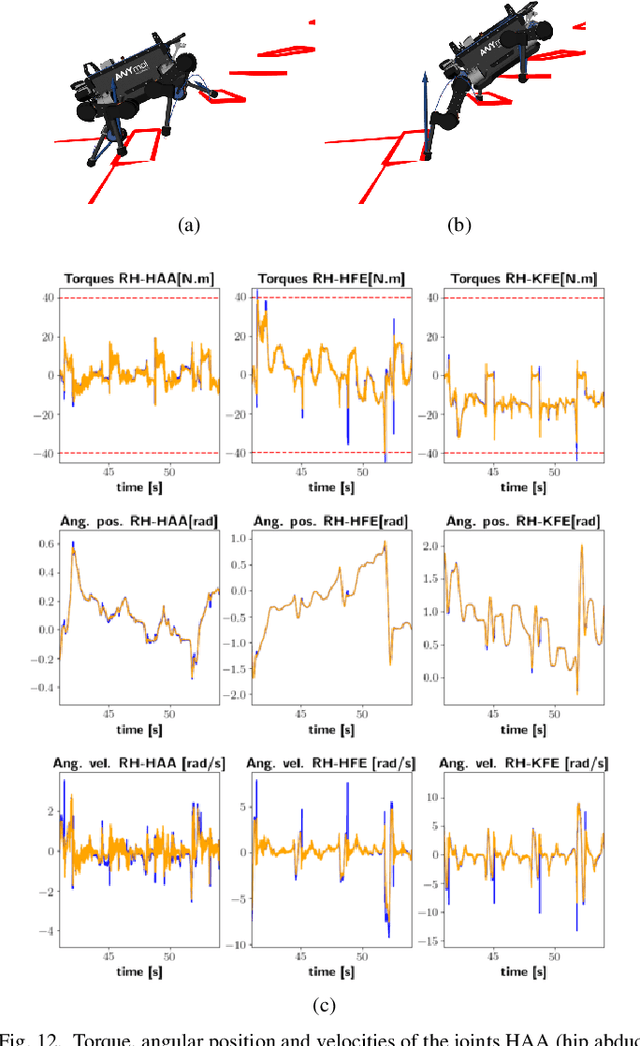
Real-time synthesis of legged locomotion maneuvers in challenging industrial settings is still an open problem, requiring simultaneous determination of footsteps locations several steps ahead while generating whole-body motions close to the robot's limits. State estimation and perception errors impose the practical constraint of fast re-planning motions in a model predictive control (MPC) framework. We first observe that the computational limitation of perceptive locomotion pipelines lies in the combinatorics of contact surface selection. Re-planning contact locations on selected surfaces can be accomplished at MPC frequencies (50-100 Hz). Then, whole-body motion generation typically follows a reference trajectory for the robot base to facilitate convergence. We propose removing this constraint to robustly address unforeseen events such as contact slipping, by leveraging a state-of-the-art whole-body MPC (Croccodyl). Our contributions are integrated into a complete framework for perceptive locomotion, validated under diverse terrain conditions, and demonstrated in challenging trials that push the robot's actuation limits, as well as in the ICRA 2023 quadruped challenge simulation.
Solving Footstep Planning as a Feasibility Problem using L1-norm Minimization
Nov 19, 2020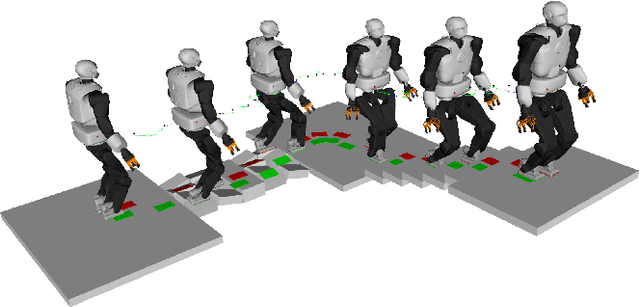
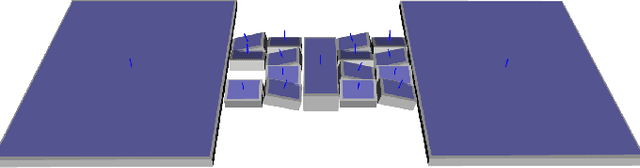
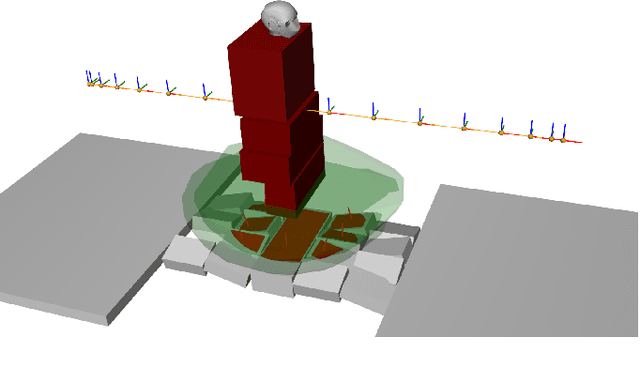
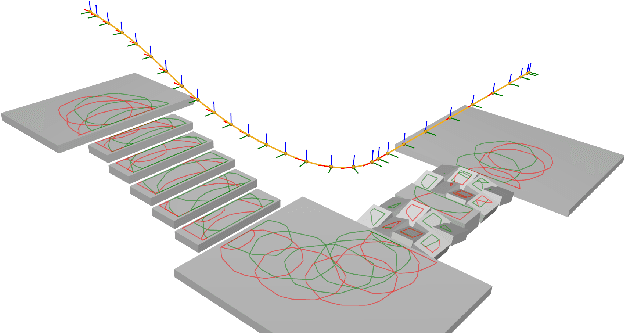
One challenge of legged locomotion on uneven terrains is to deal with both the discrete problem of selecting a contact surface for each footstep and the continuous problem of placing each footstep on the selected surface. Consequently, footstep planning can be addressed with a Mixed Integer Program (MIP), an elegant but computationally-demanding method, which can make it unsuitable for online planning. We reformulate the MIP into a cardinality problem, then approximate it as a computationally efficient l1-norm minimisation, called SL1M. Moreover, we improve the performance and convergence of SL1M by combining it with a sampling-based root trajectory planner to prune irrelevant surface candidates. Our tests on the humanoid Talos in four representative scenarios show that SL1M always converges faster than MIP. For scenarios when the combinatorial complexity is small (< 10 surfaces per step), SL1M converges at least two times faster than MIP with no need for pruning. In more complex cases, SL1M converges up to 100 times faster than MIP with the help of pruning. Moreover, pruning can also improve the MIP computation time. The versatility of the framework is shown with additional tests on the quadruped robot ANYmal.