 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Robot World Models: Stabilizing Multi-Step Rollouts via Reinforcement Learning
Mar 26, 2026Action-conditioned robot world models generate future video frames of the manipulated scene given a robot action sequence, offering a promising alternative for simulating tasks that are difficult to model with traditional physics engines. However, these models are optimized for short-term prediction and break down when deployed autoregressively: each predicted clip feeds back as context for the next, causing errors to compound and visual quality to rapidly degrade. We address this through the following contributions. First, we introduce a reinforcement learning (RL) post-training scheme that trains the world model on its own autoregressive rollouts rather than on ground-truth histories. We achieve this by adapting a recent contrastive RL objective for diffusion models to our setting and show that its convergence guarantees carry over exactly. Second, we design a training protocol that generates and compares multiple candidate variable-length futures from the same rollout state, reinforcing higher-fidelity predictions over lower-fidelity ones. Third, we develop efficient, multi-view visual fidelity rewards that combine complementary perceptual metrics across camera views and are aggregated at the clip level for dense, low-variance training signal. Fourth, we show that our approach establishes a new state-of-the-art for rollout fidelity on the DROID dataset, outperforming the strongest baseline on all metrics (e.g., LPIPS reduced by 14% on external cameras, SSIM improved by 9.1% on the wrist camera), winning 98% of paired comparisons, and achieving an 80% preference rate in a blind human study.
AlignPose: Generalizable 6D Pose Estimation via Multi-view Feature-metric Alignment
Dec 23, 2025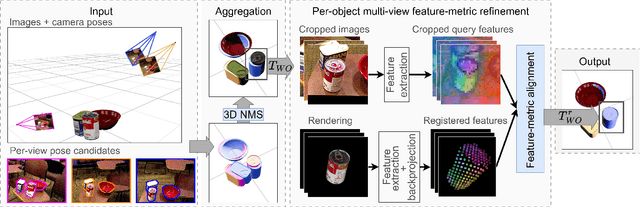
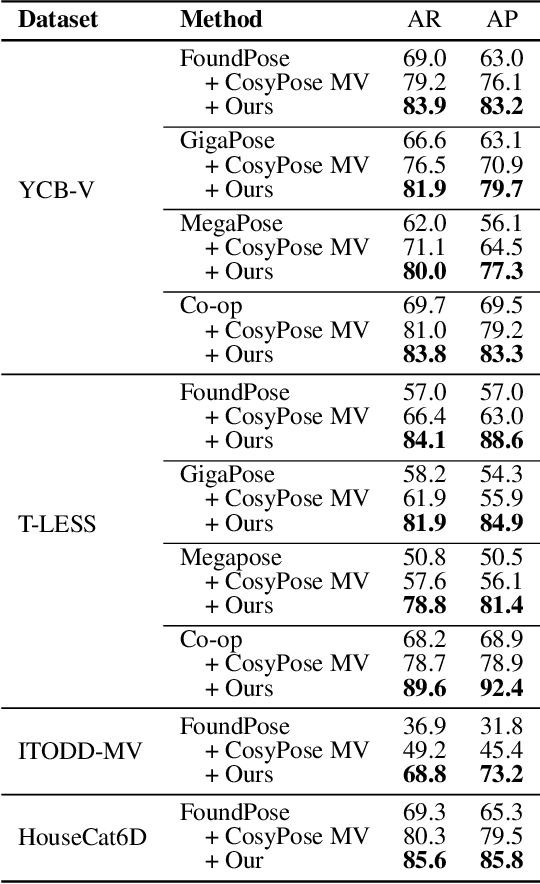
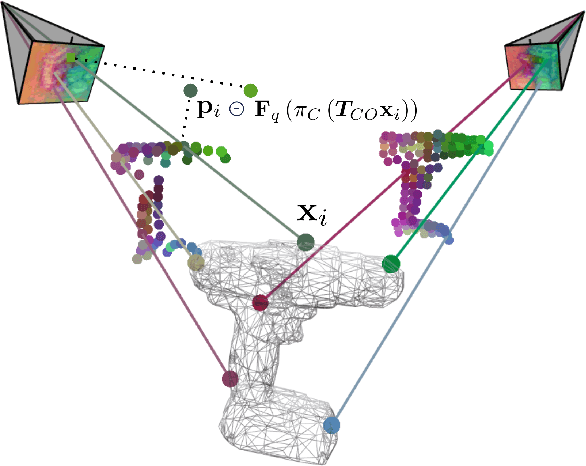
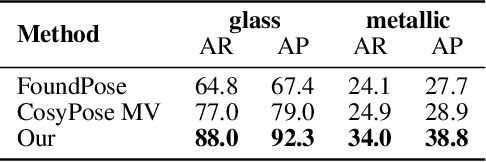
Single-view RGB model-based object pose estimation methods achieve strong generalization but are fundamentally limited by depth ambiguity, clutter, and occlusions. Multi-view pose estimation methods have the potential to solve these issues, but existing works rely on precise single-view pose estimates or lack generalization to unseen objects. We address these challenges via the following three contributions. First, we introduce AlignPose, a 6D object pose estimation method that aggregates information from multiple extrinsically calibrated RGB views and does not require any object-specific training or symmetry annotation. Second, the key component of this approach is a new multi-view feature-metric refinement specifically designed for object pose. It optimizes a single, consistent world-frame object pose minimizing the feature discrepancy between on-the-fly rendered object features and observed image features across all views simultaneously. Third, we report extensive experiments on four datasets (YCB-V, T-LESS, ITODD-MV, HouseCat6D) using the BOP benchmark evaluation and show that AlignPose outperforms other published methods, especially on challenging industrial datasets where multiple views are readily available in practice.
REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation
Dec 22, 2025Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the π_{0}, π_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs. Project page: https://martin-sedlacek.com/realm
De novo generation of functional terpene synthases using TpsGPT
Dec 15, 2025Terpene synthases (TPS) are a key family of enzymes responsible for generating the diverse terpene scaffolds that underpin many natural products, including front-line anticancer drugs such as Taxol. However, de novo TPS design through directed evolution is costly and slow. We introduce TpsGPT, a generative model for scalable TPS protein design, built by fine-tuning the protein language model ProtGPT2 on 79k TPS sequences mined from UniProt. TpsGPT generated de novo enzyme candidates in silico and we evaluated them using multiple validation metrics, including EnzymeExplorer classification, ESMFold structural confidence (pLDDT), sequence diversity, CLEAN classification, InterPro domain detection, and Foldseek structure alignment. From an initial pool of 28k generated sequences, we identified seven putative TPS enzymes that satisfied all validation criteria. Experimental validation confirmed TPS enzymatic activity in at least two of these sequences. Our results show that fine-tuning of a protein language model on a carefully curated, enzyme-class-specific dataset, combined with rigorous filtering, can enable the de novo generation of functional, evolutionarily distant enzymes.
ResidualViT for Efficient Temporally Dense Video Encoding
Sep 16, 2025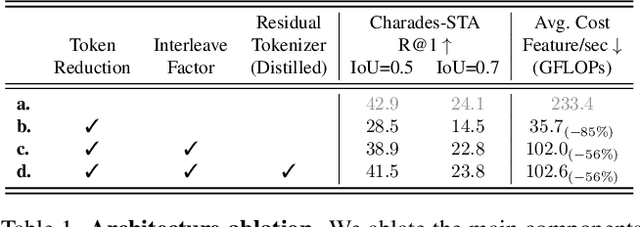
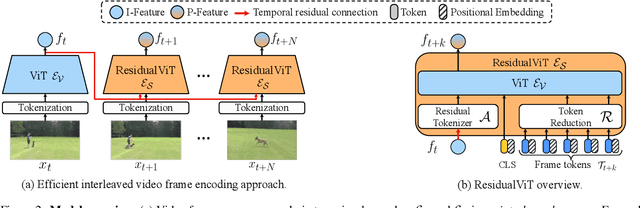
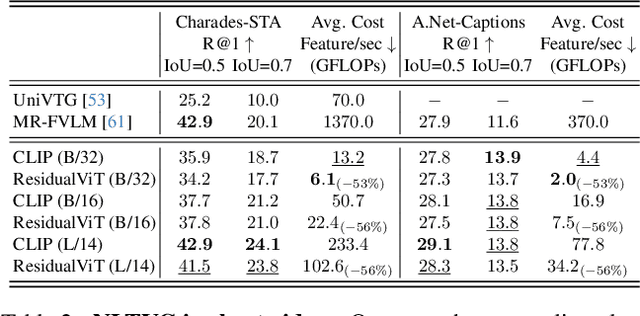

Several video understanding tasks, such as natural language temporal video grounding, temporal activity localization, and audio description generation, require "temporally dense" reasoning over frames sampled at high temporal resolution. However, computing frame-level features for these tasks is computationally expensive given the temporal resolution requirements. In this paper, we make three contributions to reduce the cost of computing features for temporally dense tasks. First, we introduce a vision transformer (ViT) architecture, dubbed ResidualViT, that leverages the large temporal redundancy in videos to efficiently compute temporally dense frame-level features. Our architecture incorporates (i) learnable residual connections that ensure temporal consistency across consecutive frames and (ii) a token reduction module that enhances processing speed by selectively discarding temporally redundant information while reusing weights of a pretrained foundation model. Second, we propose a lightweight distillation strategy to approximate the frame-level features of the original foundation model. Finally, we evaluate our approach across four tasks and five datasets, in both zero-shot and fully supervised settings, demonstrating significant reductions in computational cost (up to 60%) and improvements in inference speed (up to 2.5x faster), all while closely approximating the accuracy of the original foundation model.
Discovering Divergent Representations between Text-to-Image Models
Sep 10, 2025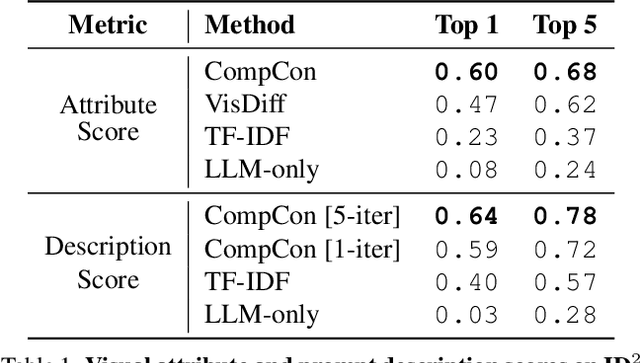
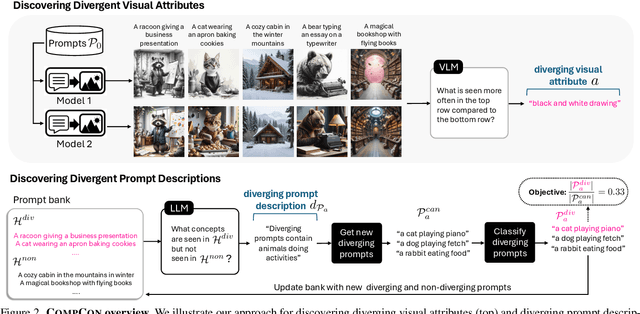


In this paper, we investigate when and how visual representations learned by two different generative models diverge. Given two text-to-image models, our goal is to discover visual attributes that appear in images generated by one model but not the other, along with the types of prompts that trigger these attribute differences. For example, "flames" might appear in one model's outputs when given prompts expressing strong emotions, while the other model does not produce this attribute given the same prompts. We introduce CompCon (Comparing Concepts), an evolutionary search algorithm that discovers visual attributes more prevalent in one model's output than the other, and uncovers the prompt concepts linked to these visual differences. To evaluate CompCon's ability to find diverging representations, we create an automated data generation pipeline to produce ID2, a dataset of 60 input-dependent differences, and compare our approach to several LLM- and VLM-powered baselines. Finally, we use CompCon to compare popular text-to-image models, finding divergent representations such as how PixArt depicts prompts mentioning loneliness with wet streets and Stable Diffusion 3.5 depicts African American people in media professions. Code at: https://github.com/adobe-research/CompCon
Improving Personalized Search with Regularized Low-Rank Parameter Updates
Jun 11, 2025Personalized vision-language retrieval seeks to recognize new concepts (e.g. "my dog Fido") from only a few examples. This task is challenging because it requires not only learning a new concept from a few images, but also integrating the personal and general knowledge together to recognize the concept in different contexts. In this paper, we show how to effectively adapt the internal representation of a vision-language dual encoder model for personalized vision-language retrieval. We find that regularized low-rank adaption of a small set of parameters in the language encoder's final layer serves as a highly effective alternative to textual inversion for recognizing the personal concept while preserving general knowledge. Additionally, we explore strategies for combining parameters of multiple learned personal concepts, finding that parameter addition is effective. To evaluate how well general knowledge is preserved in a finetuned representation, we introduce a metric that measures image retrieval accuracy based on captions generated by a vision language model (VLM). Our approach achieves state-of-the-art accuracy on two benchmarks for personalized image retrieval with natural language queries - DeepFashion2 and ConCon-Chi - outperforming the prior art by 4%-22% on personal retrievals.
Multi-step manipulation task and motion planning guided by video demonstration
May 13, 2025


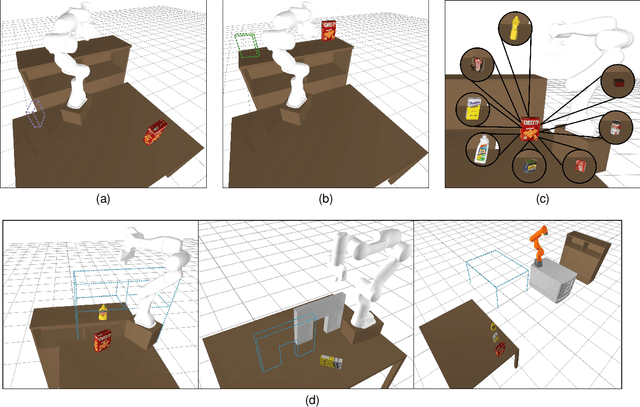
This work aims to leverage instructional video to solve complex multi-step task-and-motion planning tasks in robotics. Towards this goal, we propose an extension of the well-established Rapidly-Exploring Random Tree (RRT) planner, which simultaneously grows multiple trees around grasp and release states extracted from the guiding video. Our key novelty lies in combining contact states and 3D object poses extracted from the guiding video with a traditional planning algorithm that allows us to solve tasks with sequential dependencies, for example, if an object needs to be placed at a specific location to be grasped later. We also investigate the generalization capabilities of our approach to go beyond the scene depicted in the instructional video. To demonstrate the benefits of the proposed video-guided planning approach, we design a new benchmark with three challenging tasks: (I) 3D re-arrangement of multiple objects between a table and a shelf, (ii) multi-step transfer of an object through a tunnel, and (iii) transferring objects using a tray similar to a waiter transfers dishes. We demonstrate the effectiveness of our planning algorithm on several robots, including the Franka Emika Panda and the KUKA KMR iiwa. For a seamless transfer of the obtained plans to the real robot, we develop a trajectory refinement approach formulated as an optimal control problem (OCP).
PhysPose: Refining 6D Object Poses with Physical Constraints
Mar 30, 2025
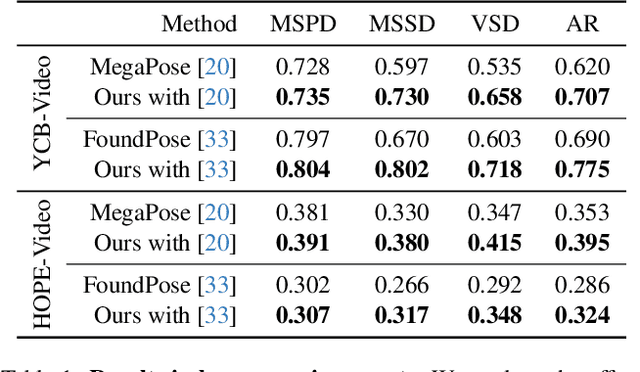
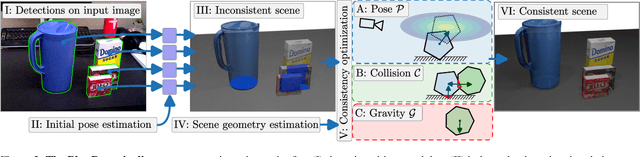
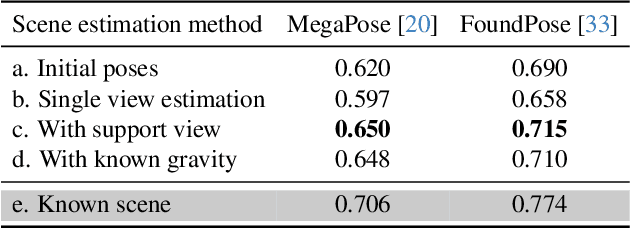
Accurate 6D object pose estimation from images is a key problem in object-centric scene understanding, enabling applications in robotics, augmented reality, and scene reconstruction. Despite recent advances, existing methods often produce physically inconsistent pose estimates, hindering their deployment in real-world scenarios. We introduce PhysPose, a novel approach that integrates physical reasoning into pose estimation through a postprocessing optimization enforcing non-penetration and gravitational constraints. By leveraging scene geometry, PhysPose refines pose estimates to ensure physical plausibility. Our approach achieves state-of-the-art accuracy on the YCB-Video dataset from the BOP benchmark and improves over the state-of-the-art pose estimation methods on the HOPE-Video dataset. Furthermore, we demonstrate its impact in robotics by significantly improving success rates in a challenging pick-and-place task, highlighting the importance of physical consistency in real-world applications.
6D Object Pose Tracking in Internet Videos for Robotic Manipulation
Mar 13, 2025



We seek to extract a temporally consistent 6D pose trajectory of a manipulated object from an Internet instructional video. This is a challenging set-up for current 6D pose estimation methods due to uncontrolled capturing conditions, subtle but dynamic object motions, and the fact that the exact mesh of the manipulated object is not known. To address these challenges, we present the following contributions. First, we develop a new method that estimates the 6D pose of any object in the input image without prior knowledge of the object itself. The method proceeds by (i) retrieving a CAD model similar to the depicted object from a large-scale model database, (ii) 6D aligning the retrieved CAD model with the input image, and (iii) grounding the absolute scale of the object with respect to the scene. Second, we extract smooth 6D object trajectories from Internet videos by carefully tracking the detected objects across video frames. The extracted object trajectories are then retargeted via trajectory optimization into the configuration space of a robotic manipulator. Third, we thoroughly evaluate and ablate our 6D pose estimation method on YCB-V and HOPE-Video datasets as well as a new dataset of instructional videos manually annotated with approximate 6D object trajectories. We demonstrate significant improvements over existing state-of-the-art RGB 6D pose estimation methods. Finally, we show that the 6D object motion estimated from Internet videos can be transferred to a 7-axis robotic manipulator both in a virtual simulator as well as in a real world set-up. We also successfully apply our method to egocentric videos taken from the EPIC-KITCHENS dataset, demonstrating potential for Embodied AI applications.