 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidualViT for Efficient Temporally Dense Video Encoding
Sep 16, 2025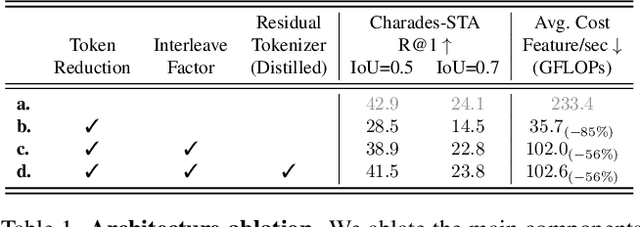
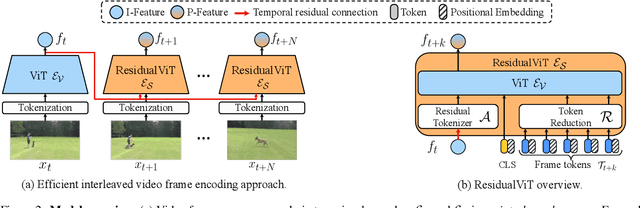
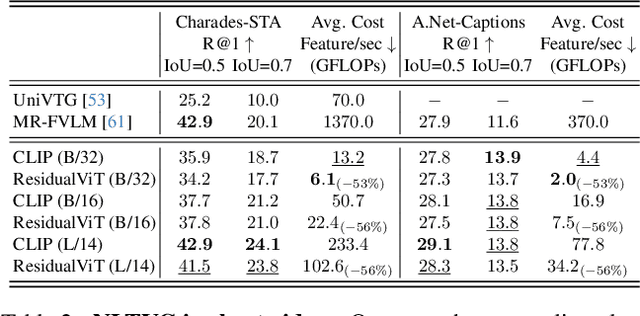

Several video understanding tasks, such as natural language temporal video grounding, temporal activity localization, and audio description generation, require "temporally dense" reasoning over frames sampled at high temporal resolution. However, computing frame-level features for these tasks is computationally expensive given the temporal resolution requirements. In this paper, we make three contributions to reduce the cost of computing features for temporally dense tasks. First, we introduce a vision transformer (ViT) architecture, dubbed ResidualViT, that leverages the large temporal redundancy in videos to efficiently compute temporally dense frame-level features. Our architecture incorporates (i) learnable residual connections that ensure temporal consistency across consecutive frames and (ii) a token reduction module that enhances processing speed by selectively discarding temporally redundant information while reusing weights of a pretrained foundation model. Second, we propose a lightweight distillation strategy to approximate the frame-level features of the original foundation model. Finally, we evaluate our approach across four tasks and five datasets, in both zero-shot and fully supervised settings, demonstrating significant reductions in computational cost (up to 60%) and improvements in inference speed (up to 2.5x faster), all while closely approximating the accuracy of the original foundation model.
Discovering Divergent Representations between Text-to-Image Models
Sep 10, 2025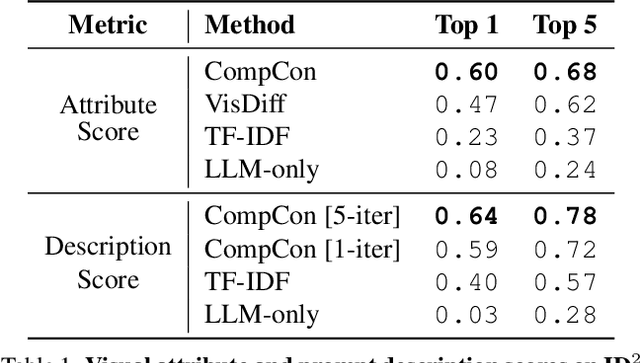
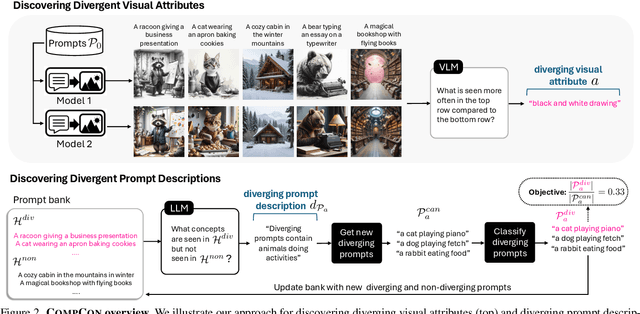


In this paper, we investigate when and how visual representations learned by two different generative models diverge. Given two text-to-image models, our goal is to discover visual attributes that appear in images generated by one model but not the other, along with the types of prompts that trigger these attribute differences. For example, "flames" might appear in one model's outputs when given prompts expressing strong emotions, while the other model does not produce this attribute given the same prompts. We introduce CompCon (Comparing Concepts), an evolutionary search algorithm that discovers visual attributes more prevalent in one model's output than the other, and uncovers the prompt concepts linked to these visual differences. To evaluate CompCon's ability to find diverging representations, we create an automated data generation pipeline to produce ID2, a dataset of 60 input-dependent differences, and compare our approach to several LLM- and VLM-powered baselines. Finally, we use CompCon to compare popular text-to-image models, finding divergent representations such as how PixArt depicts prompts mentioning loneliness with wet streets and Stable Diffusion 3.5 depicts African American people in media professions. Code at: https://github.com/adobe-research/CompCon
Improving Personalized Search with Regularized Low-Rank Parameter Updates
Jun 11, 2025Personalized vision-language retrieval seeks to recognize new concepts (e.g. "my dog Fido") from only a few examples. This task is challenging because it requires not only learning a new concept from a few images, but also integrating the personal and general knowledge together to recognize the concept in different contexts. In this paper, we show how to effectively adapt the internal representation of a vision-language dual encoder model for personalized vision-language retrieval. We find that regularized low-rank adaption of a small set of parameters in the language encoder's final layer serves as a highly effective alternative to textual inversion for recognizing the personal concept while preserving general knowledge. Additionally, we explore strategies for combining parameters of multiple learned personal concepts, finding that parameter addition is effective. To evaluate how well general knowledge is preserved in a finetuned representation, we introduce a metric that measures image retrieval accuracy based on captions generated by a vision language model (VLM). Our approach achieves state-of-the-art accuracy on two benchmarks for personalized image retrieval with natural language queries - DeepFashion2 and ConCon-Chi - outperforming the prior art by 4%-22% on personal retrievals.
Generative Timelines for Instructed Visual Assembly
Nov 19, 2024The objective of this work is to manipulate visual timelines (e.g. a video) through natural language instructions, making complex timeline editing tasks accessible to non-expert or potentially even disabled users. We call this task Instructed visual assembly. This task is challenging as it requires (i) identifying relevant visual content in the input timeline as well as retrieving relevant visual content in a given input (video) collection, (ii) understanding the input natural language instruction, and (iii) performing the desired edits of the input visual timeline to produce an output timeline. To address these challenges, we propose the Timeline Assembler, a generative model trained to perform instructed visual assembly tasks. The contributions of this work are three-fold. First, we develop a large multimodal language model, which is designed to process visual content, compactly represent timelines and accurately interpret timeline editing instructions. Second, we introduce a novel method for automatically generating datasets for visual assembly tasks, enabling efficient training of our model without the need for human-labeled data. Third, we validate our approach by creating two novel datasets for image and video assembly, demonstrating that the Timeline Assembler substantially outperforms established baseline models, including the recent GPT-4o, in accurately executing complex assembly instructions across various real-world inspired scenarios.
Sync from the Sea: Retrieving Alignable Videos from Large-Scale Datasets
Sep 02, 2024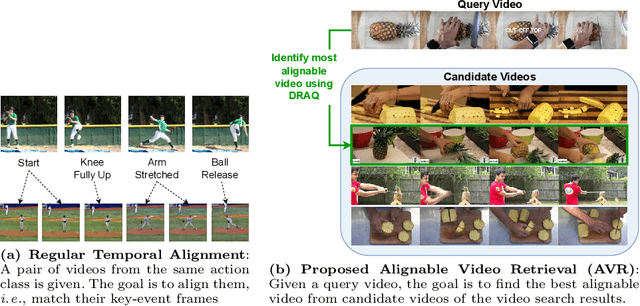

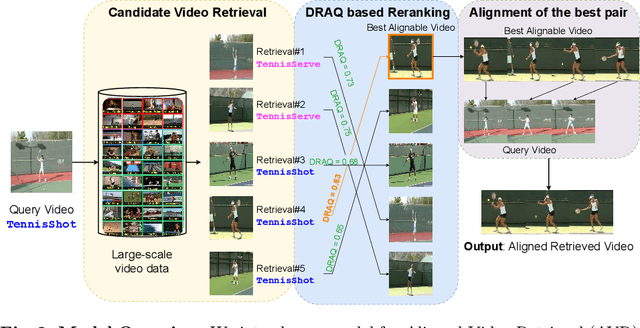

Temporal video alignment aims to synchronize the key events like object interactions or action phase transitions in two videos. Such methods could benefit various video editing, processing, and understanding tasks. However, existing approaches operate under the restrictive assumption that a suitable video pair for alignment is given, significantly limiting their broader applicability. To address this, we re-pose temporal alignment as a search problem and introduce the task of Alignable Video Retrieval (AVR). Given a query video, our approach can identify well-alignable videos from a large collection of clips and temporally synchronize them to the query. To achieve this, we make three key contributions: 1) we introduce DRAQ, a video alignability indicator to identify and re-rank the best alignable video from a set of candidates; 2) we propose an effective and generalizable frame-level video feature design to improve the alignment performance of several off-the-shelf feature representations, and 3) we propose a novel benchmark and evaluation protocol for AVR using cycle-consistency metrics. Our experiments on 3 datasets, including large-scale Kinetics700, demonstrate the effectiveness of our approach in identifying alignable video pairs from diverse datasets. Project Page: https://daveishan.github.io/avr-webpage/.
Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
May 06, 2024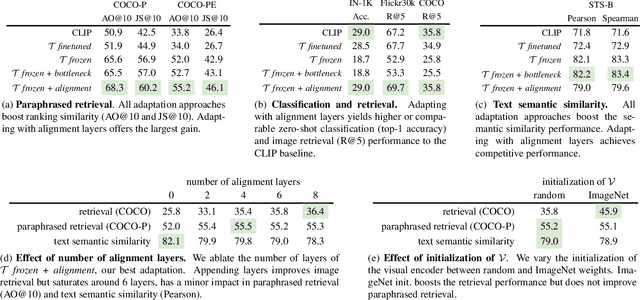
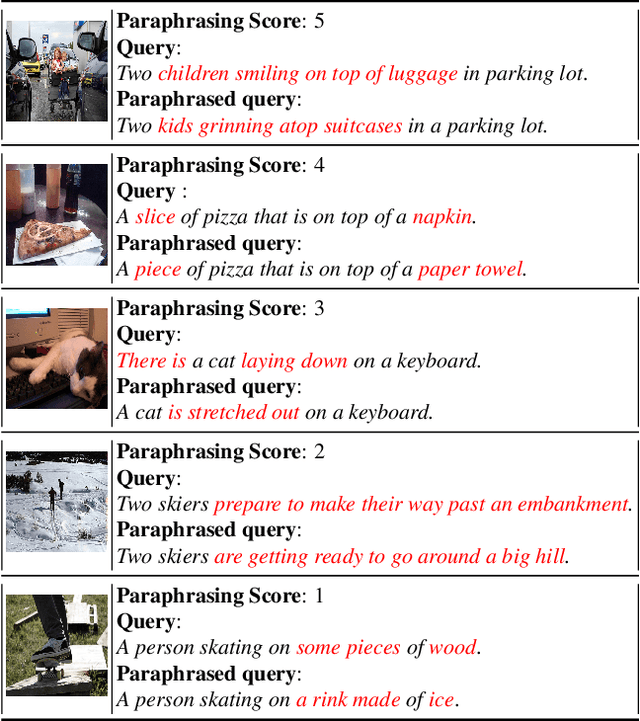
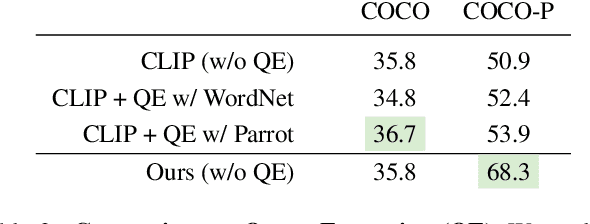
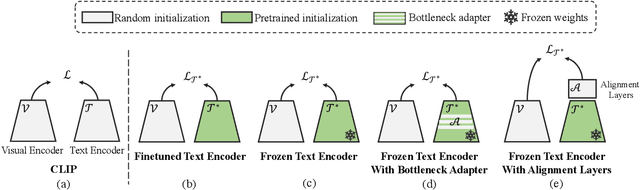
In the recent years, the dual-encoder vision-language models (\eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Apr 05, 2024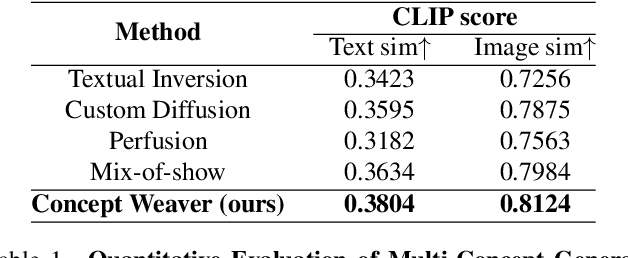
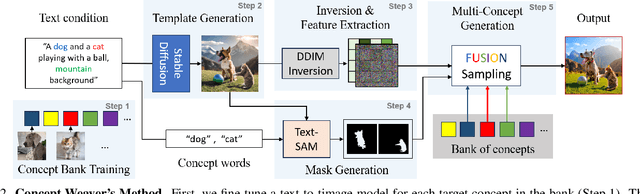
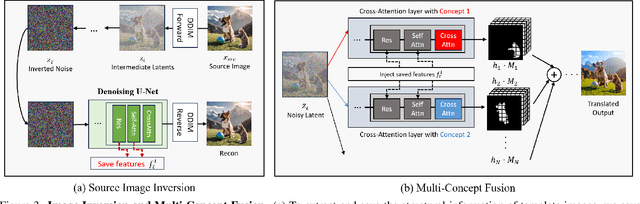
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
Towards Automated Movie Trailer Generation
Apr 04, 2024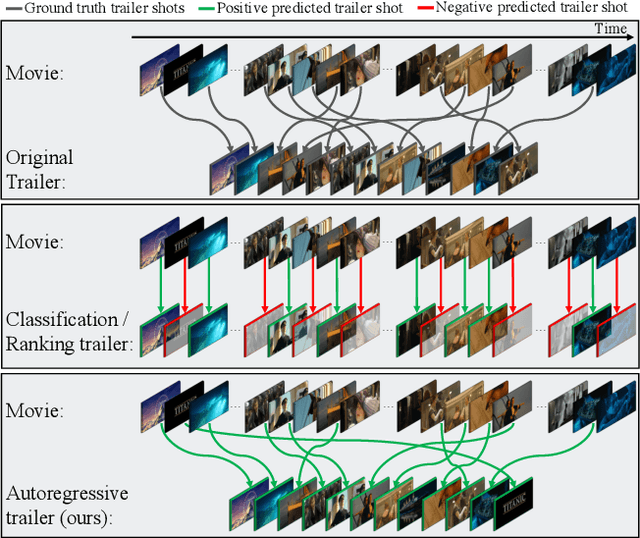

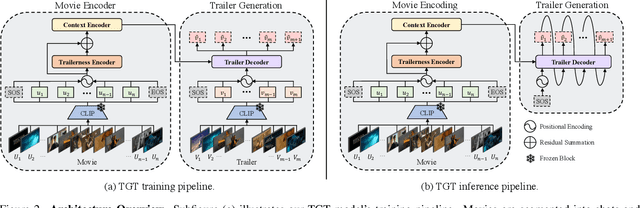
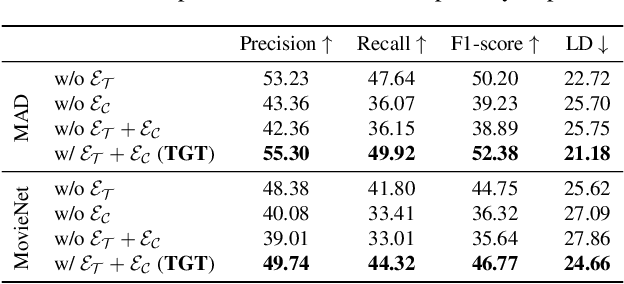
Movie trailers are an essential tool for promoting films and attracting audiences. However, the process of creating trailers can be time-consuming and expensive. To streamline this process, we propose an automatic trailer generation framework that generates plausible trailers from a full movie by automating shot selection and composition. Our approach draws inspiration from machine translation techniques and models the movies and trailers as sequences of shots, thus formulating the trailer generation problem as a sequence-to-sequence task. We introduce Trailer Generation Transformer (TGT), a deep-learning framework utilizing an encoder-decoder architecture. TGT movie encoder is tasked with contextualizing each movie shot representation via self-attention, while the autoregressive trailer decoder predicts the feature representation of the next trailer shot, accounting for the relevance of shots' temporal order in trailers. Our TGT significantly outperforms previous methods on a comprehensive suite of metrics.
Scaling Up Video Summarization Pretraining with Large Language Models
Apr 04, 2024Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Long-range Multimodal Pretraining for Movie Understanding
Aug 18, 2023Learning computer vision models from (and for) movies has a long-standing history. While great progress has been attained, there is still a need for a pretrained multimodal model that can perform well in the ever-growing set of movie understanding tasks the community has been establishing. In this work, we introduce Long-range Multimodal Pretraining, a strategy, and a model that leverages movie data to train transferable multimodal and cross-modal encoders. Our key idea is to learn from all modalities in a movie by observing and extracting relationships over a long-range. After pretraining, we run ablation studies on the LVU benchmark and validate our modeling choices and the importance of learning from long-range time spans. Our model achieves state-of-the-art on several LVU tasks while being much more data efficient than previous works. Finally, we evaluate our model's transferability by setting a new state-of-the-art in five different benchmarks.