 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Dual-encoder Vision-language Models for Paraphrased Retrieval
Paper and Code
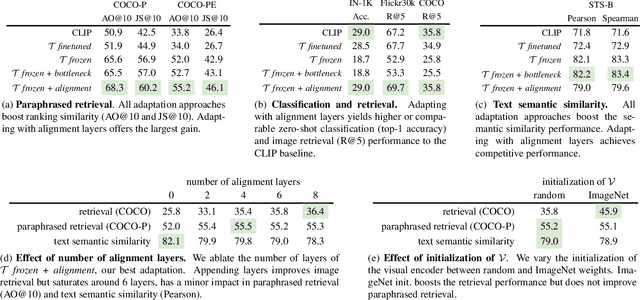
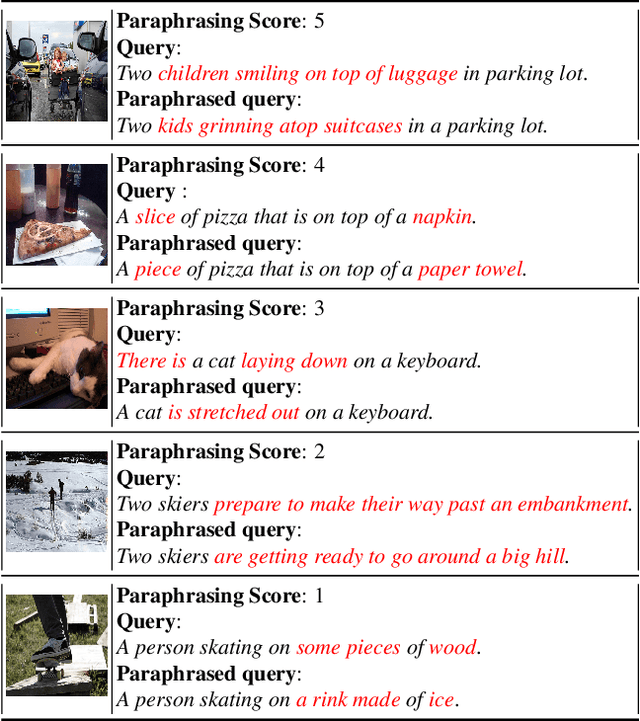
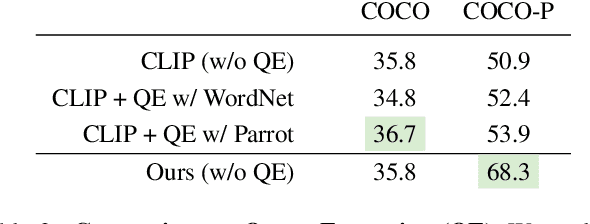
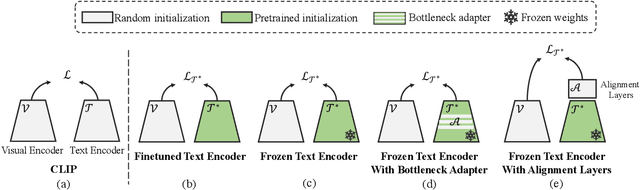
In the recent years, the dual-encoder vision-language models (\eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.