 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Dual-encoder Vision-language Models for Paraphrased Retrieval
May 06, 2024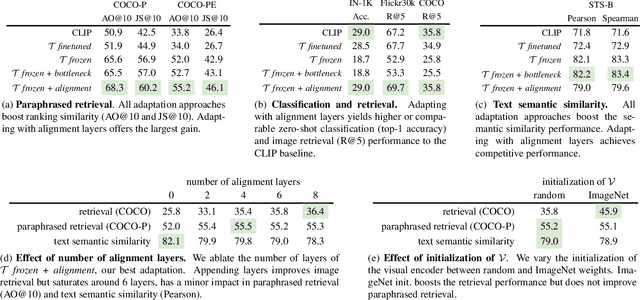
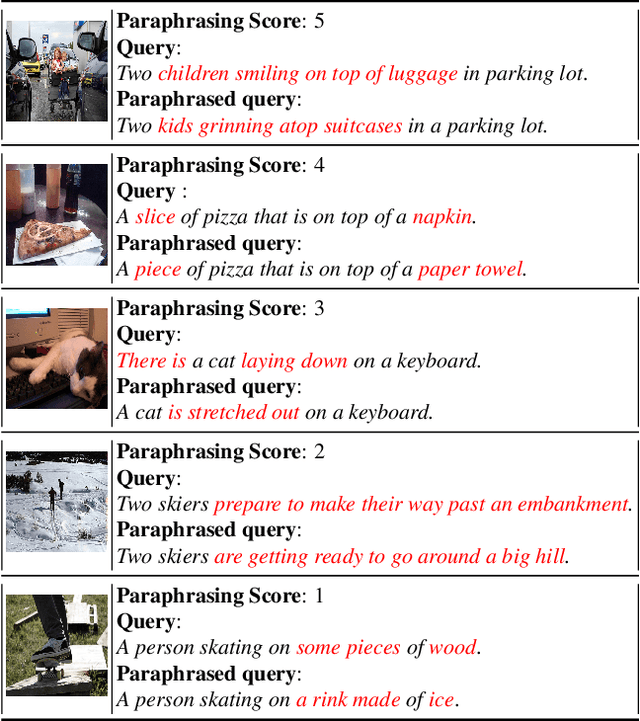
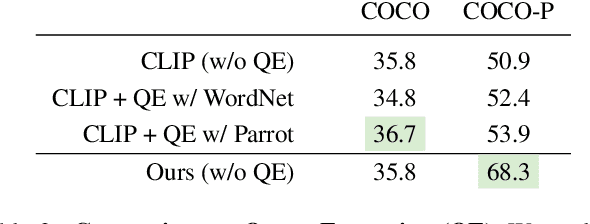
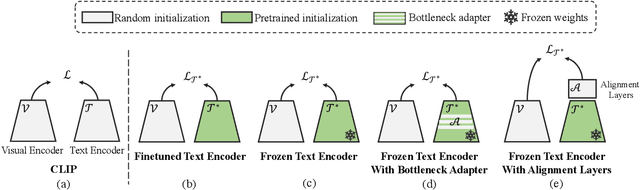
In the recent years, the dual-encoder vision-language models (\eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.
Automated Conversion of Music Videos into Lyric Videos
Aug 28, 2023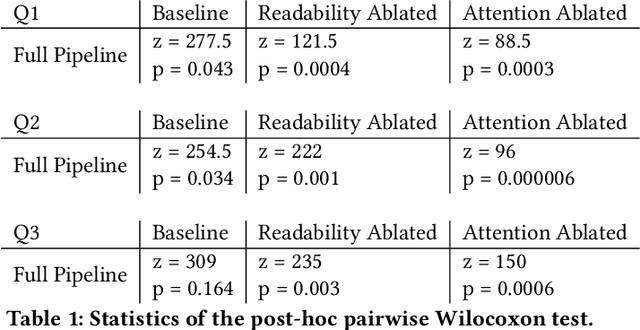



Musicians and fans often produce lyric videos, a form of music videos that showcase the song's lyrics, for their favorite songs. However, making such videos can be challenging and time-consuming as the lyrics need to be added in synchrony and visual harmony with the video. Informed by prior work and close examination of existing lyric videos, we propose a set of design guidelines to help creators make such videos. Our guidelines ensure the readability of the lyric text while maintaining a unified focus of attention. We instantiate these guidelines in a fully automated pipeline that converts an input music video into a lyric video. We demonstrate the robustness of our pipeline by generating lyric videos from a diverse range of input sources. A user study shows that lyric videos generated by our pipeline are effective in maintaining text readability and unifying the focus of attention.
B-Script: Transcript-based B-roll Video Editing with Recommendations
Feb 28, 2019

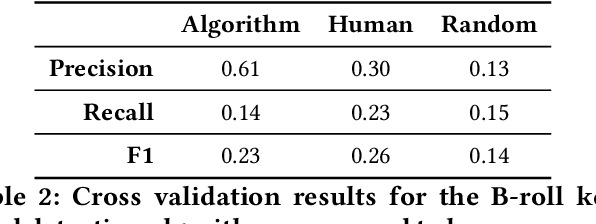

In video production, inserting B-roll is a widely used technique to enrich the story and make a video more engaging. However, determining the right content and positions of B-roll and actually inserting it within the main footage can be challenging, and novice producers often struggle to get both timing and content right. We present B-Script, a system that supports B-roll video editing via interactive transcripts. B-Script has a built-in recommendation system trained on expert-annotated data, recommending users B-roll position and content. To evaluate the system, we conducted a within-subject user study with 110 participants, and compared three interface variations: a timeline-based editor, a transcript-based editor, and a transcript-based editor with recommendations. Users found it easier and were faster to insert B-roll using the transcript-based interface, and they created more engaging videos when recommendations were provided.
On Learning Associations of Faces and Voices
Nov 02, 2018
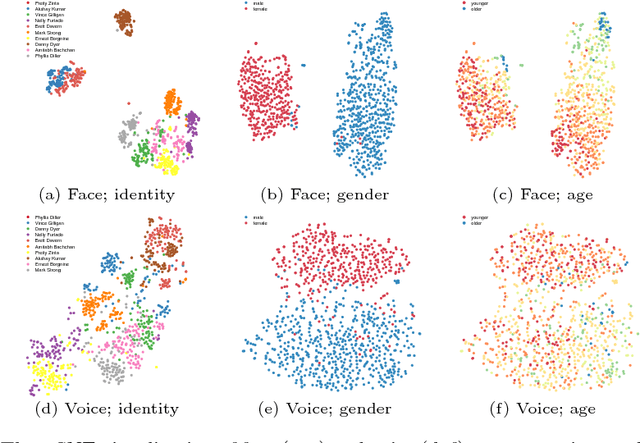


In this paper, we study the associations between human faces and voices. Audiovisual integration, specifically the integration of facial and vocal information is a well-researched area in neuroscience. It is shown that the overlapping information between the two modalities plays a significant role in perceptual tasks such as speaker identification. Through an online study on a new dataset we created, we confirm previous findings that people can associate unseen faces with corresponding voices and vice versa with greater than chance accuracy. We computationally model the overlapping information between faces and voices and show that the learned cross-modal representation contains enough information to identify matching faces and voices with performance similar to that of humans. Our representation exhibits correlations to certain demographic attributes and features obtained from either visual or aural modality alone. We release our dataset of audiovisual recordings and demographic annotations of people reading out short text used in our studies.