 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Embedding Spaces for Matching Music to Stories
Nov 26, 2021
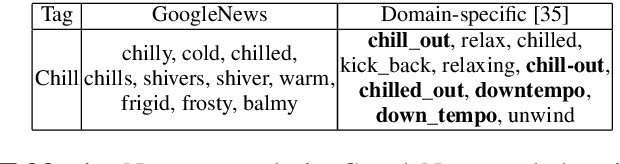

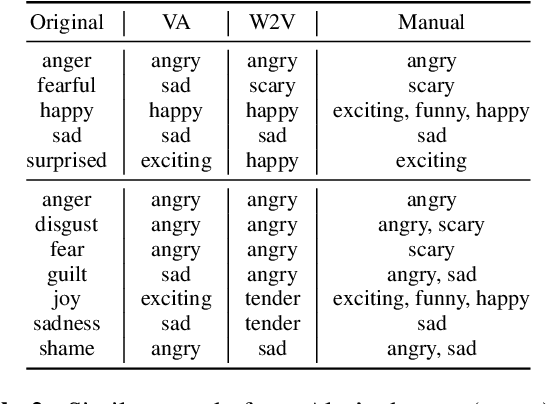
Content creators often use music to enhance their stories, as it can be a powerful tool to convey emotion. In this paper, our goal is to help creators find music to match the emotion of their story. We focus on text-based stories that can be auralized (e.g., books), use multiple sentences as input queries, and automatically retrieve matching music. We formalize this task as a cross-modal text-to-music retrieval problem. Both the music and text domains have existing datasets with emotion labels, but mismatched emotion vocabularies prevent us from using mood or emotion annotations directly for matching. To address this challenge, we propose and investigate several emotion embedding spaces, both manually defined (e.g., valence/arousal) and data-driven (e.g., Word2Vec and metric learning) to bridge this gap. Our experiments show that by leveraging these embedding spaces, we are able to successfully bridge the gap between modalities to facilitate cross modal retrieval. We show that our method can leverage the well established valence-arousal space, but that it can also achieve our goal via data-driven embedding spaces. By leveraging data-driven embeddings, our approach has the potential of being generalized to other retrieval tasks that require broader or completely different vocabularies.
Controllable Neural Prosody Synthesis
Aug 11, 2020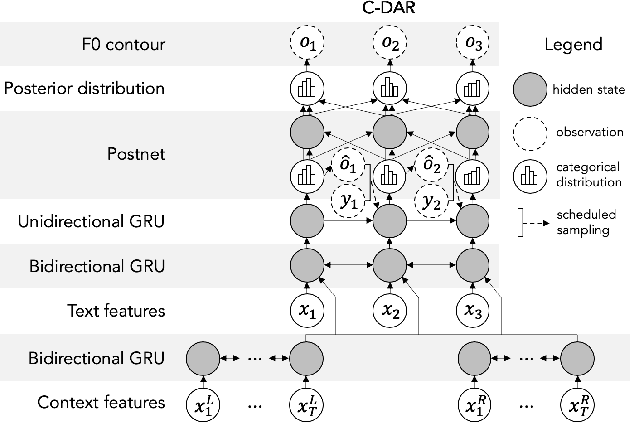

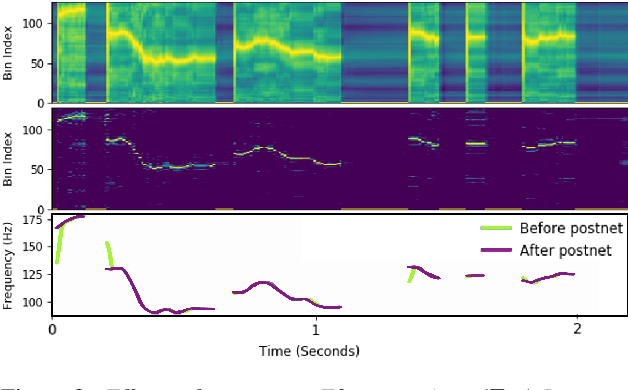
Speech synthesis has recently seen significant improvements in fidelity, driven by the advent of neural vocoders and neural prosody generators. However, these systems lack intuitive user controls over prosody, making them unable to rectify prosody errors (e.g., misplaced emphases and contextually inappropriate emotions) or generate prosodies with diverse speaker excitement levels and emotions. We address these limitations with a user-controllable, context-aware neural prosody generator. Given a real or synthesized speech recording, our model allows a user to input prosody constraints for certain time frames and generates the remaining time frames from input text and contextual prosody. We also propose a pitch-shifting neural vocoder to modify input speech to match the synthesized prosody. Through objective and subjective evaluations we show that we can successfully incorporate user control into our prosody generation model without sacrificing the overall naturalness of the synthesized speech.
F0-consistent many-to-many non-parallel voice conversion via conditional autoencoder
Apr 15, 2020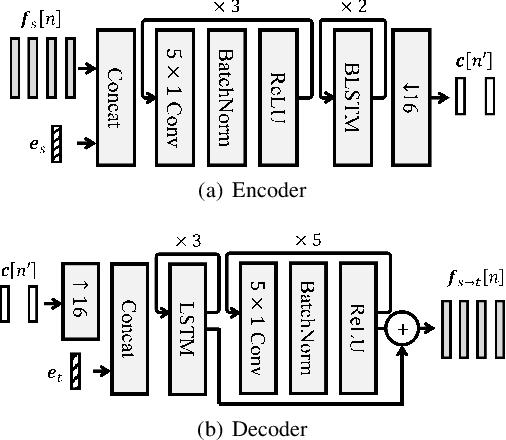
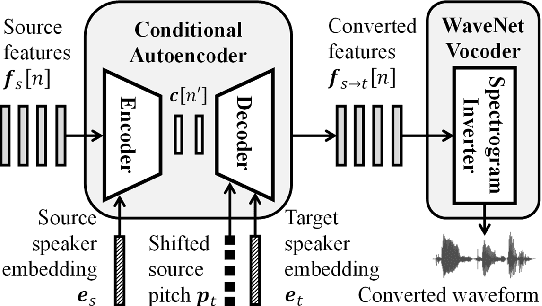
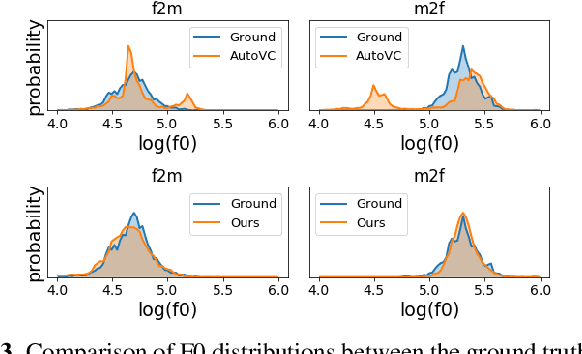
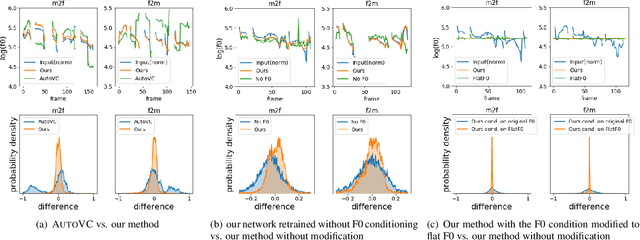
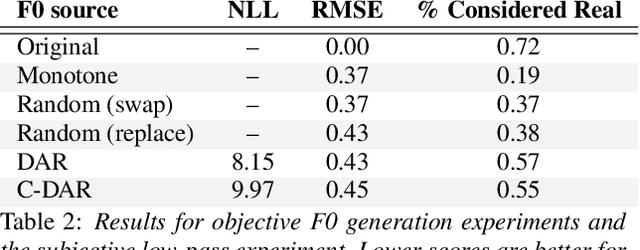
Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Many style-transfer-inspired methods such as generative adversarial networks (GANs) and variational autoencoders (VAEs) have been proposed. Recently, AutoVC, a conditional autoencoders (CAEs) based method achieved state-of-the-art results by disentangling the speaker identity and speech content using information-constraining bottlenecks, and it achieves zero-shot conversion by swapping in a different speaker's identity embedding to synthesize a new voice. However, we found that while speaker identity is disentangled from speech content, a significant amount of prosodic information, such as source F0, leaks through the bottleneck, causing target F0 to fluctuate unnaturally. Furthermore, AutoVC has no control of the converted F0 and thus unsuitable for many applications. In the paper, we modified and improved autoencoder-based voice conversion to disentangle content, F0, and speaker identity at the same time. Therefore, we can control the F0 contour, generate speech with F0 consistent with the target speaker, and significantly improve quality and similarity. We support our improvement through quantitative and qualitative analysis.
B-Script: Transcript-based B-roll Video Editing with Recommendations
Feb 28, 2019

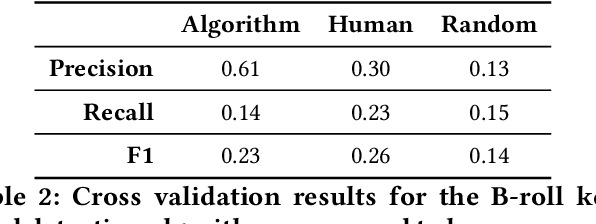

In video production, inserting B-roll is a widely used technique to enrich the story and make a video more engaging. However, determining the right content and positions of B-roll and actually inserting it within the main footage can be challenging, and novice producers often struggle to get both timing and content right. We present B-Script, a system that supports B-roll video editing via interactive transcripts. B-Script has a built-in recommendation system trained on expert-annotated data, recommending users B-roll position and content. To evaluate the system, we conducted a within-subject user study with 110 participants, and compared three interface variations: a timeline-based editor, a transcript-based editor, and a transcript-based editor with recommendations. Users found it easier and were faster to insert B-roll using the transcript-based interface, and they created more engaging videos when recommendations were provided.
A Generative Product-of-Filters Model of Audio
Nov 25, 2014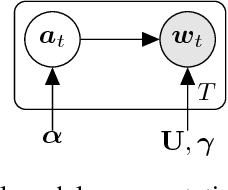
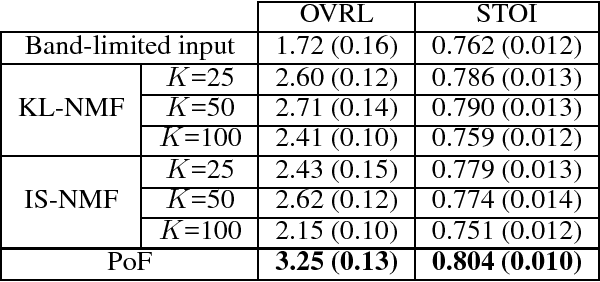
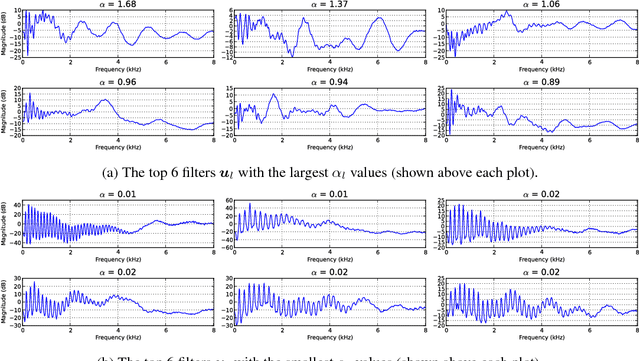

We propose the product-of-filters (PoF) model, a generative model that decomposes audio spectra as sparse linear combinations of "filters" in the log-spectral domain. PoF makes similar assumptions to those used in the classic homomorphic filtering approach to signal processing, but replaces hand-designed decompositions built of basic signal processing operations with a learned decomposition based on statistical inference. This paper formulates the PoF model and derives a mean-field method for posterior inference and a variational EM algorithm to estimate the model's free parameters. We demonstrate PoF's potential for audio processing on a bandwidth expansion task, and show that PoF can serve as an effective unsupervised feature extractor for a speaker identification task.