 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiFFPO: Training Diffusion LLMs to Reason Fast and Furious via Reinforcement Learning
Oct 02, 2025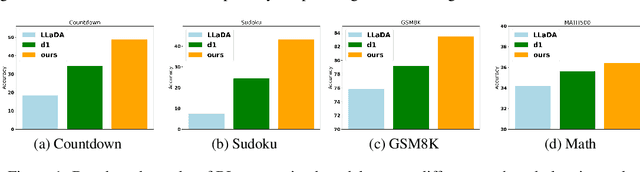

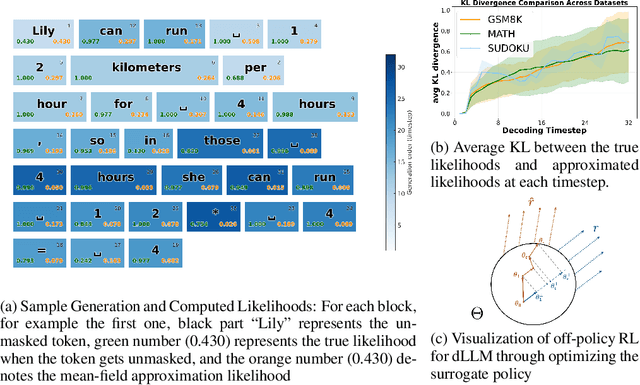

We propose DiFFPO, Diffusion Fast and Furious Policy Optimization, a unified framework for training masked diffusion large language models (dLLMs) to reason not only better (furious), but also faster via reinforcement learning (RL). We first unify the existing baseline approach such as d1 by proposing to train surrogate policies via off-policy RL, whose likelihood is much more tractable as an approximation to the true dLLM policy. This naturally motivates a more accurate and informative two-stage likelihood approximation combined with importance sampling correction, which leads to generalized RL algorithms with better sample efficiency and superior task performance. Second, we propose a new direction of joint training efficient samplers/controllers of dLLMs policy. Via RL, we incentivize dLLMs' natural multi-token prediction capabilities by letting the model learn to adaptively allocate an inference threshold for each prompt. By jointly training the sampler, we yield better accuracies with lower number of function evaluations (NFEs) compared to training the model only, obtaining the best performance in improving the Pareto frontier of the inference-time compute of dLLMs. We showcase the effectiveness of our pipeline by training open source large diffusion language models over benchmark math and planning tasks.
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025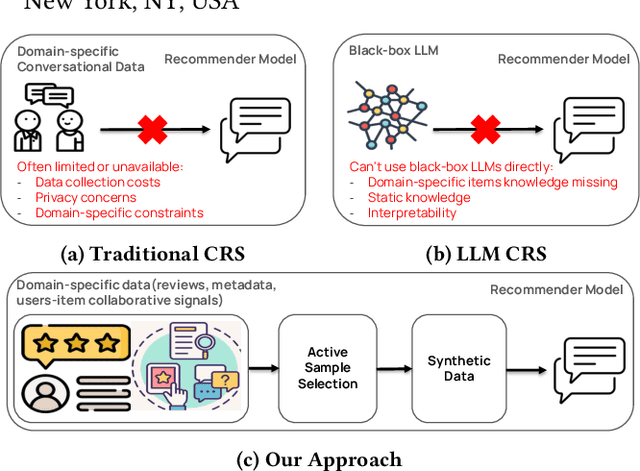
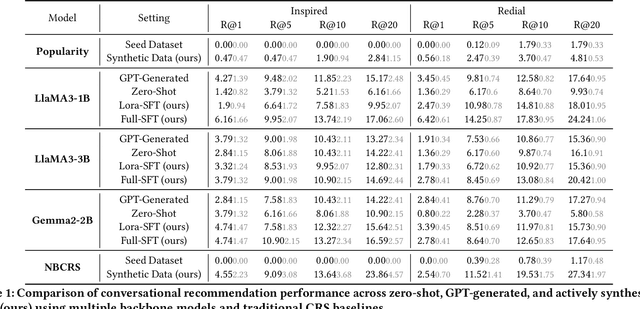
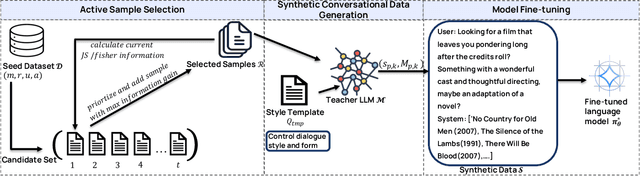
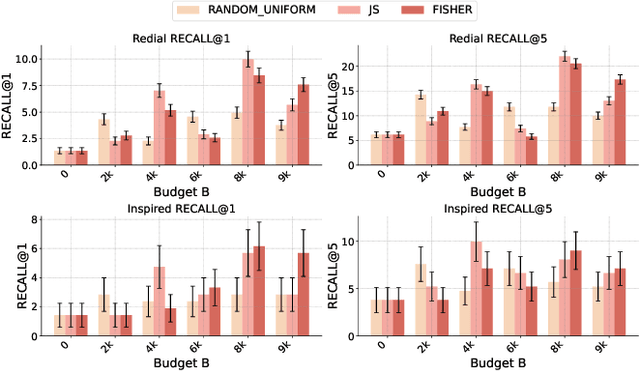
Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.
Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems
Feb 19, 2025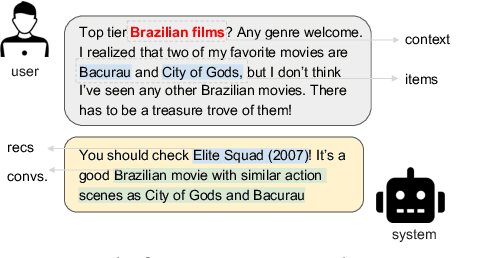
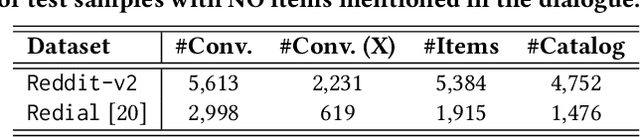
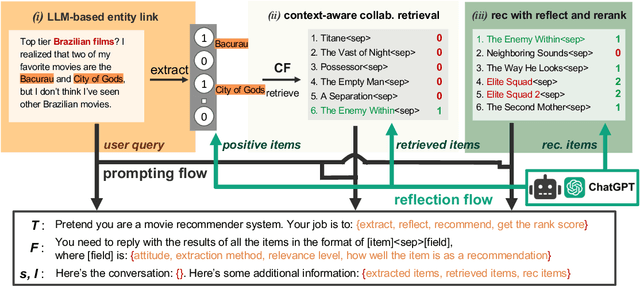

Conversational recommender systems (CRS) aim to provide personalized recommendations via interactive dialogues with users. While large language models (LLMs) enhance CRS with their superior understanding of context-aware user preferences, they typically struggle to leverage behavioral data, which have proven to be important for classical collaborative filtering (CF)-based approaches. For this reason, we propose CRAG, Collaborative Retrieval Augmented Generation for LLM-based CRS. To the best of our knowledge, CRAG is the first approach that combines state-of-the-art LLMs with CF for conversational recommendations. Our experiments on two publicly available movie conversational recommendation datasets, i.e., a refined Reddit dataset (which we name Reddit-v2) as well as the Redial dataset, demonstrate the superior item coverage and recommendation performance of CRAG, compared to several CRS baselines. Moreover, we observe that the improvements are mainly due to better recommendation accuracy on recently released movies. The code and data are available at https://github.com/yaochenzhu/CRAG.
Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
May 20, 2024Large language models (LLMs) are revolutionizing conversational recommender systems by adeptly indexing item content, understanding complex conversational contexts, and generating relevant item titles. However, controlling the distribution of recommended items remains a challenge. This leads to suboptimal performance due to the failure to capture rapidly changing data distributions, such as item popularity, on targeted conversational recommendation platforms. In conversational recommendation, LLMs recommend items by generating the titles (as multiple tokens) autoregressively, making it difficult to obtain and control the recommendations over all items. Thus, we propose a Reindex-Then-Adapt (RTA) framework, which converts multi-token item titles into single tokens within LLMs, and then adjusts the probability distributions over these single-token item titles accordingly. The RTA framework marries the benefits of both LLMs and traditional recommender systems (RecSys): understanding complex queries as LLMs do; while efficiently controlling the recommended item distributions in conversational recommendations as traditional RecSys do. Our framework demonstrates improved accuracy metrics across three different conversational recommendation datasets and two adaptation settings
Switching the Loss Reduces the Cost in Batch Reinforcement Learning
Mar 12, 2024
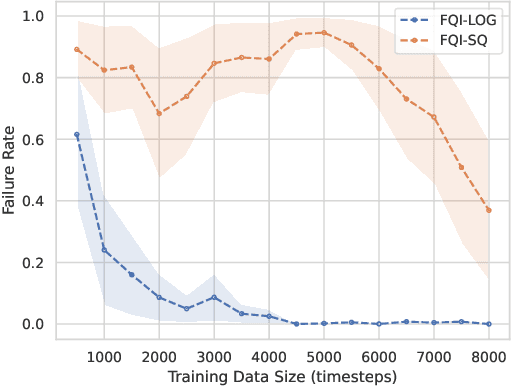
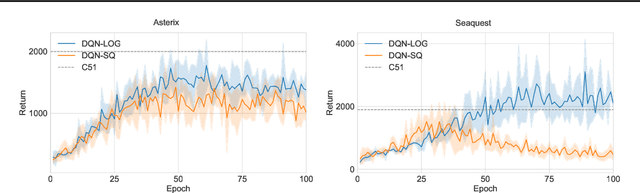
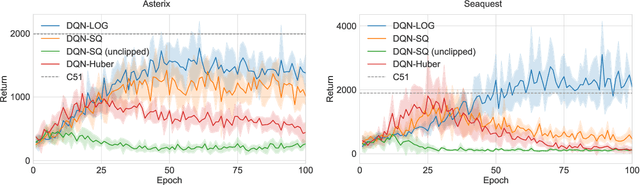
We propose training fitted Q-iteration with log-loss (FQI-LOG) for batch reinforcement learning (RL). We show that the number of samples needed to learn a near-optimal policy with FQI-LOG scales with the accumulated cost of the optimal policy, which is zero in problems where acting optimally achieves the goal and incurs no cost. In doing so, we provide a general framework for proving $\textit{small-cost}$ bounds, i.e. bounds that scale with the optimal achievable cost, in batch RL. Moreover, we empirically verify that FQI-LOG uses fewer samples than FQI trained with squared loss on problems where the optimal policy reliably achieves the goal.
Risk-Sensitive RL with Optimized Certainty Equivalents via Reduction to Standard RL
Mar 10, 2024We study Risk-Sensitive Reinforcement Learning (RSRL) with the Optimized Certainty Equivalent (OCE) risk, which generalizes Conditional Value-at-risk (CVaR), entropic risk and Markowitz's mean-variance. Using an augmented Markov Decision Process (MDP), we propose two general meta-algorithms via reductions to standard RL: one based on optimistic algorithms and another based on policy optimization. Our optimistic meta-algorithm generalizes almost all prior RSRL theory with entropic risk or CVaR. Under discrete rewards, our optimistic theory also certifies the first RSRL regret bounds for MDPs with bounded coverability, e.g., exogenous block MDPs. Under discrete rewards, our policy optimization meta-algorithm enjoys both global convergence and local improvement guarantees in a novel metric that lower bounds the true OCE risk. Finally, we instantiate our framework with PPO, construct an MDP, and show that it learns the optimal risk-sensitive policy while prior algorithms provably fail.
Off-Policy Evaluation for Large Action Spaces via Policy Convolution
Oct 24, 2023Developing accurate off-policy estimators is crucial for both evaluating and optimizing for new policies. The main challenge in off-policy estimation is the distribution shift between the logging policy that generates data and the target policy that we aim to evaluate. Typically, techniques for correcting distribution shift involve some form of importance sampling. This approach results in unbiased value estimation but often comes with the trade-off of high variance, even in the simpler case of one-step contextual bandits. Furthermore, importance sampling relies on the common support assumption, which becomes impractical when the action space is large. To address these challenges, we introduce the Policy Convolution (PC) family of estimators. These methods leverage latent structure within actions -- made available through action embeddings -- to strategically convolve the logging and target policies. This convolution introduces a unique bias-variance trade-off, which can be controlled by adjusting the amount of convolution. Our experiments on synthetic and benchmark datasets demonstrate remarkable mean squared error (MSE) improvements when using PC, especially when either the action space or policy mismatch becomes large, with gains of up to 5 - 6 orders of magnitude over existing estimators.
Large Language Models as Zero-Shot Conversational Recommenders
Aug 19, 2023



In this paper, we present empirical studies on conversational recommendation tasks using representative large language models in a zero-shot setting with three primary contributions. (1) Data: To gain insights into model behavior in "in-the-wild" conversational recommendation scenarios, we construct a new dataset of recommendation-related conversations by scraping a popular discussion website. This is the largest public real-world conversational recommendation dataset to date. (2) Evaluation: On the new dataset and two existing conversational recommendation datasets, we observe that even without fine-tuning, large language models can outperform existing fine-tuned conversational recommendation models. (3) Analysis: We propose various probing tasks to investigate the mechanisms behind the remarkable performance of large language models in conversational recommendation. We analyze both the large language models' behaviors and the characteristics of the datasets, providing a holistic understanding of the models' effectiveness, limitations and suggesting directions for the design of future conversational recommenders
Local Policy Improvement for Recommender Systems
Dec 22, 2022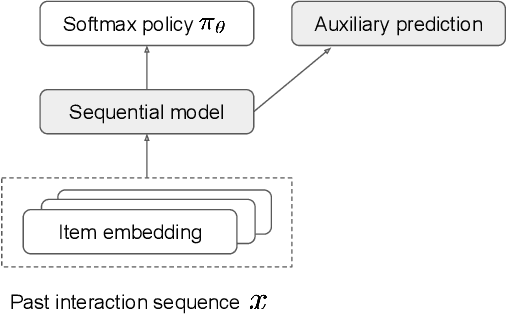
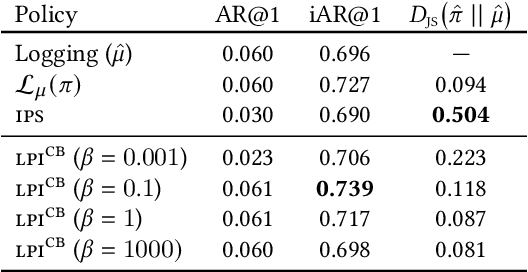
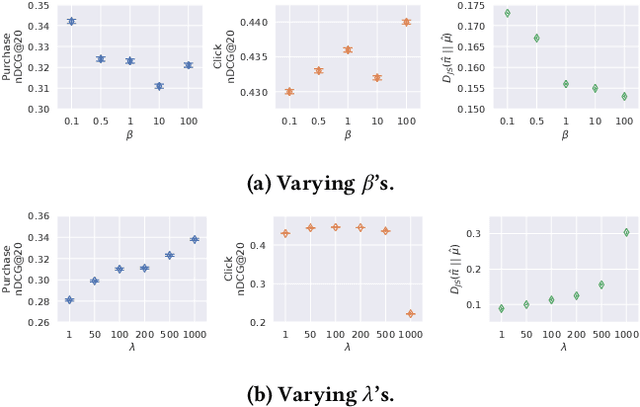
Recommender systems aim to answer the following question: given the items that a user has interacted with, what items will this user likely interact with next? Historically this problem is often framed as a predictive task via (self-)supervised learning. In recent years, we have seen more emphasis placed on approaching the recommendation problem from a policy optimization perspective: learning a policy that maximizes some reward function (e.g., user engagement). However, it is commonly the case in recommender systems that we are only able to train a new policy given data collected from a previously-deployed policy. The conventional way to address such a policy mismatch is through importance sampling correction, which unfortunately comes with its own limitations. In this paper, we suggest an alternative approach, which involves the use of local policy improvement without off-policy correction. Drawing from a number of related results in the fields of causal inference, bandits, and reinforcement learning, we present a suite of methods that compute and optimize a lower bound of the expected reward of the target policy. Crucially, this lower bound is a function that is easy to estimate from data, and which does not involve density ratios (such as those appearing in importance sampling correction). We argue that this local policy improvement paradigm is particularly well suited for recommender systems, given that in practice the previously-deployed policy is typically of reasonably high quality, and furthermore it tends to be re-trained frequently and gets continuously updated. We discuss some practical recipes on how to apply some of the proposed techniques in a sequential recommendation setting.
Learning Correlated Latent Representations with Adaptive Priors
Jul 16, 2019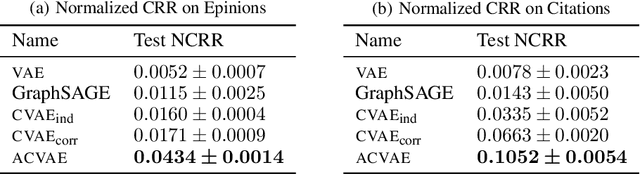
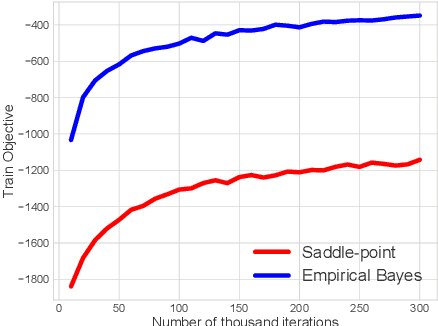
Variational Auto-Encoders (VAEs) have been widely applied for learning compact low-dimensional latent representations for high-dimensional data. When the correlation structure among data points is available, previous work proposed Correlated Variational Auto-Encoders (CVAEs) which employ a structured mixture model as prior and a structured variational posterior for each mixture component to enforce the learned latent representations to follow the same correlation structure. However, as we demonstrate in this paper, such a choice can not guarantee that CVAEs can capture all of the correlations. Furthermore, it prevents us from obtaining a tractable joint and marginal variational distribution. To address these issues, we propose Adaptive Correlated Variational Auto-Encoders (ACVAEs), which apply an adaptive prior distribution that can be adjusted during training, and learn a tractable joint distribution via a saddle-point optimization procedure. Its tractable form also enables further refinement with belief propagation. Experimental results on two real datasets show that ACVAEs outperform other benchmarks significantly.