 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Selectively Contextual Bandits
May 09, 2022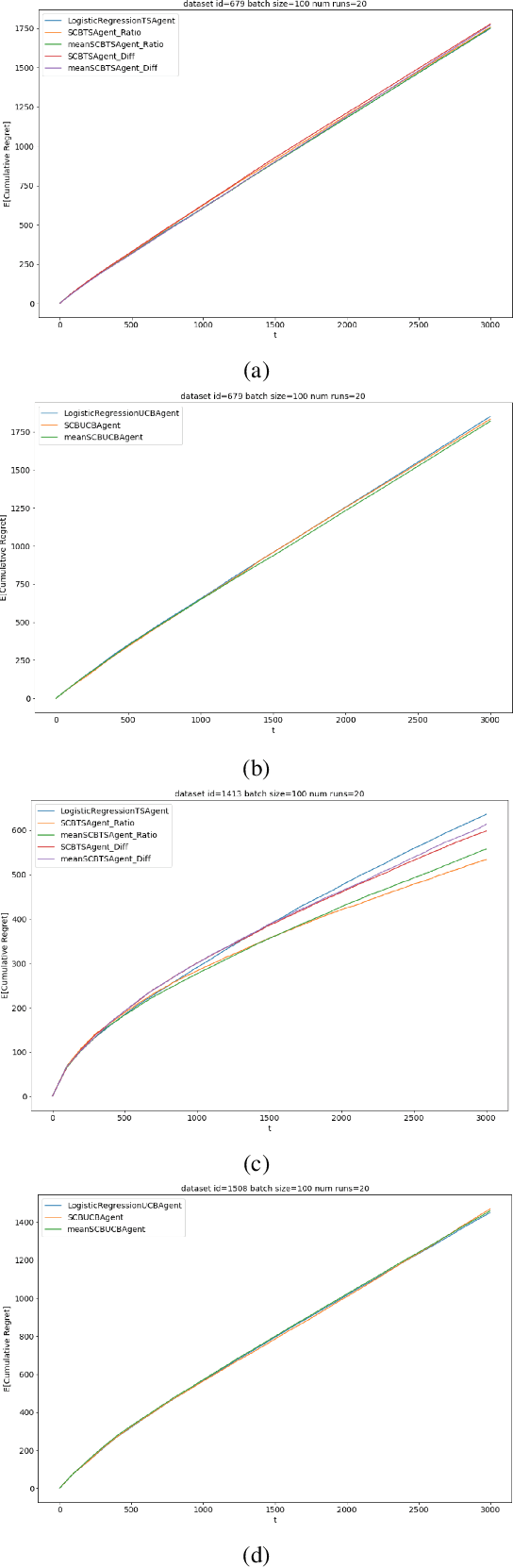
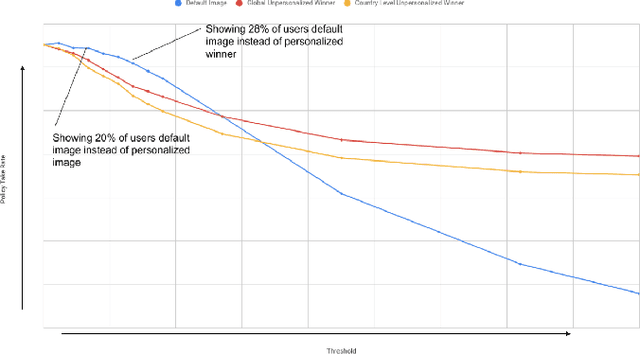
Contextual bandits are widely used in industrial personalization systems. These online learning frameworks learn a treatment assignment policy in the presence of treatment effects that vary with the observed contextual features of the users. While personalization creates a rich user experience that reflect individual interests, there are benefits of a shared experience across a community that enable participation in the zeitgeist. Such benefits are emergent through network effects and are not captured in regret metrics typically employed in evaluating bandits. To balance these needs, we propose a new online learning algorithm that preserves benefits of personalization while increasing the commonality in treatments across users. Our approach selectively interpolates between a contextual bandit algorithm and a context-free multi-arm bandit and leverages the contextual information for a treatment decision only if it promises significant gains. Apart from helping users of personalization systems balance their experience between the individualized and shared, simplifying the treatment assignment policy by making it selectively reliant on the context can help improve the rate of learning in some cases. We evaluate our approach in a classification setting using public datasets and show the benefits of the hybrid policy.
Active Multitask Learning with Committees
Mar 24, 2021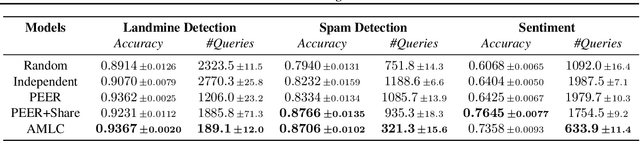
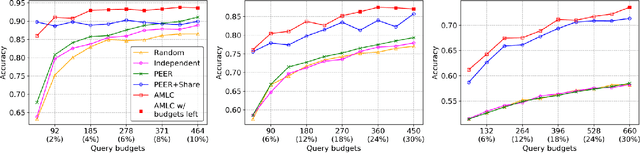
The cost of annotating training data has traditionally been a bottleneck for supervised learning approaches. The problem is further exacerbated when supervised learning is applied to a number of correlated tasks simultaneously since the amount of labels required scales with the number of tasks. To mitigate this concern, we propose an active multitask learning algorithm that achieves knowledge transfer between tasks. The approach forms a so-called committee for each task that jointly makes decisions and directly shares data across similar tasks. Our approach reduces the number of queries needed during training while maintaining high accuracy on test data. Empirical results on benchmark datasets show significant improvements on both accuracy and number of query requests.
Learning Correlated Latent Representations with Adaptive Priors
Jul 16, 2019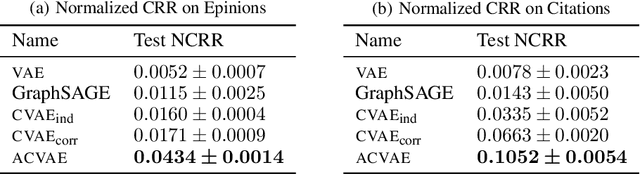
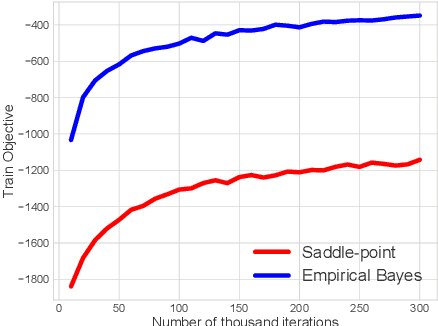
Variational Auto-Encoders (VAEs) have been widely applied for learning compact low-dimensional latent representations for high-dimensional data. When the correlation structure among data points is available, previous work proposed Correlated Variational Auto-Encoders (CVAEs) which employ a structured mixture model as prior and a structured variational posterior for each mixture component to enforce the learned latent representations to follow the same correlation structure. However, as we demonstrate in this paper, such a choice can not guarantee that CVAEs can capture all of the correlations. Furthermore, it prevents us from obtaining a tractable joint and marginal variational distribution. To address these issues, we propose Adaptive Correlated Variational Auto-Encoders (ACVAEs), which apply an adaptive prior distribution that can be adjusted during training, and learn a tractable joint distribution via a saddle-point optimization procedure. Its tractable form also enables further refinement with belief propagation. Experimental results on two real datasets show that ACVAEs outperform other benchmarks significantly.
A New Distribution on the Simplex with Auto-Encoding Applications
May 28, 2019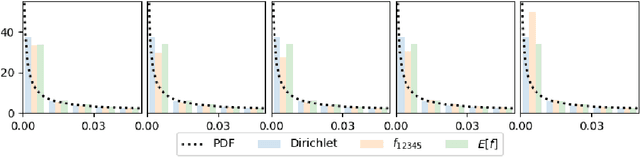
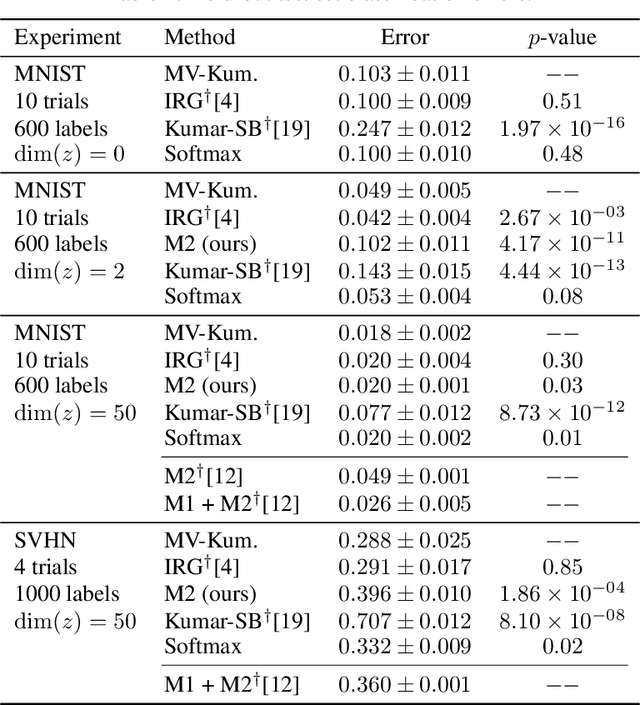
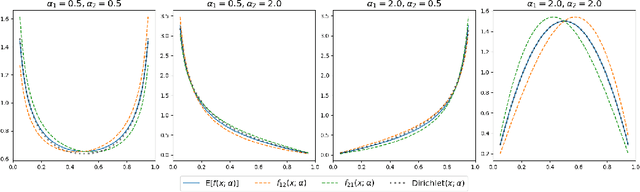
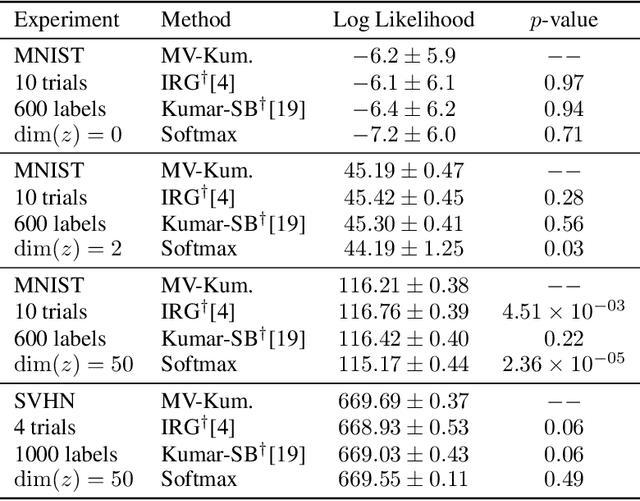
We construct a new distribution for the simplex using the Kumaraswamy distribution and an ordered stick-breaking process. We explore and develop the theoretical properties of this new distribution and prove that it exhibits symmetry under the same conditions as the well-known Dirichlet. Like the Dirichlet, the new distribution is adept at capturing sparsity but, unlike the Dirichlet, has an exact and closed form reparameterization--making it well suited for deep variational Bayesian modeling. We demonstrate the distribution's utility in a variety of semi-supervised auto-encoding tasks. In all cases, the resulting models achieve competitive performance commensurate with their simplicity, use of explicit probability models, and abstinence from adversarial training.
Correlated Variational Auto-Encoders
May 16, 2019
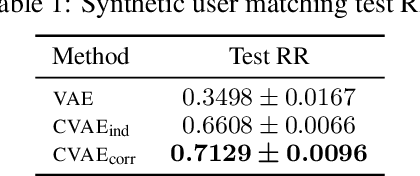

Variational Auto-Encoders (VAEs) are capable of learning latent representations for high dimensional data. However, due to the i.i.d. assumption, VAEs only optimize the singleton variational distributions and fail to account for the correlations between data points, which might be crucial for learning latent representations from dataset where a priori we know correlations exist. We propose Correlated Variational Auto-Encoders (CVAEs) that can take the correlation structure into consideration when learning latent representations with VAEs. CVAEs apply a prior based on the correlation structure. To address the intractability introduced by the correlated prior, we develop an approximation by average of a set of tractable lower bounds over all maximal acyclic subgraphs of the undirected correlation graph. Experimental results on matching and link prediction on public benchmark rating datasets and spectral clustering on a synthetic dataset show the effectiveness of the proposed method over baseline algorithms.
Beta Survival Models
May 09, 2019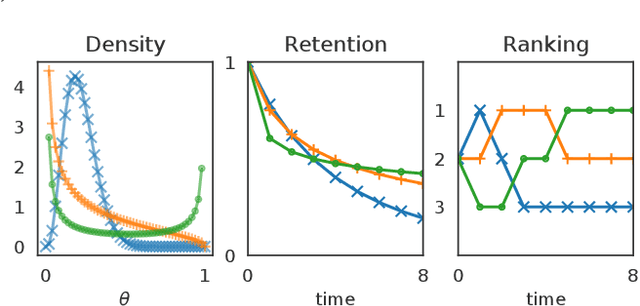
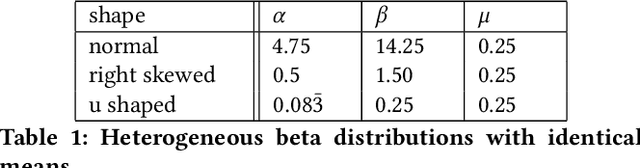
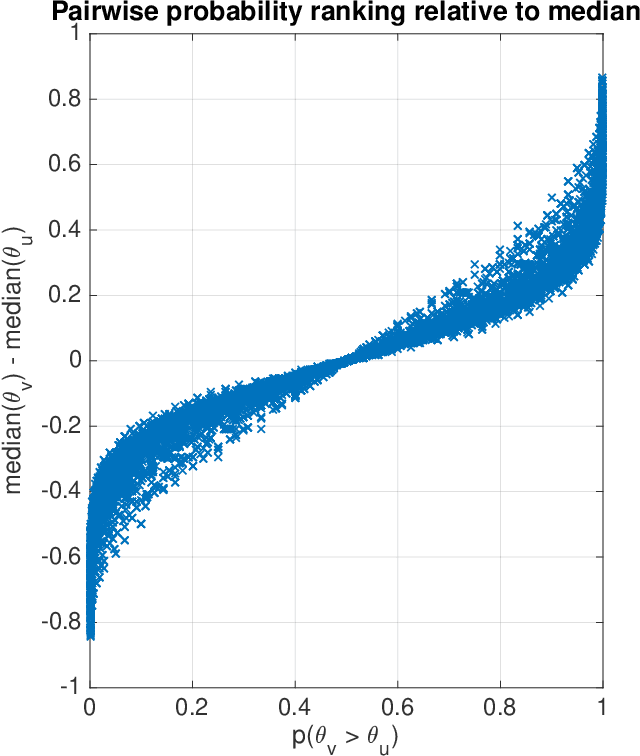
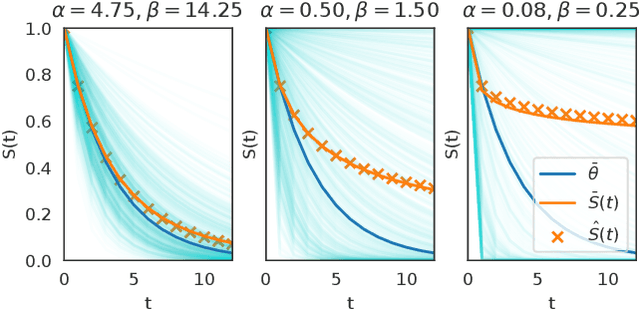
This article analyzes the problem of estimating the time until an event occurs, also known as survival modeling. We observe through substantial experiments on large real-world datasets and use-cases that populations are largely heterogeneous. Sub-populations have different mean and variance in their survival rates requiring flexible models that capture heterogeneity. We leverage a classical extension of the logistic function into the survival setting to characterize unobserved heterogeneity using the beta distribution. This yields insights into the geometry of the problem as well as efficient estimation methods for linear, tree and neural network models that adjust the beta distribution based on observed covariates. We also show that the additional information captured by the beta distribution leads to interesting ranking implications as we determine who is most-at-risk. We show theoretically that the ranking is variable as we forecast forward in time and prove that pairwise comparisons of survival remain transitive. Empirical results using large-scale datasets across two use-cases (online conversions and retention modeling), demonstrate the competitiveness of the method. The simplicity of the method and its ability to capture skew in the data makes it a viable alternative to standard techniques particularly when we are interested in the time to event and when the underlying probabilities are heterogeneous.
Thompson Sampling for Noncompliant Bandits
Dec 03, 2018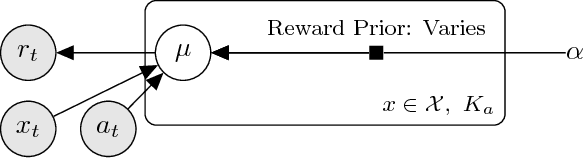
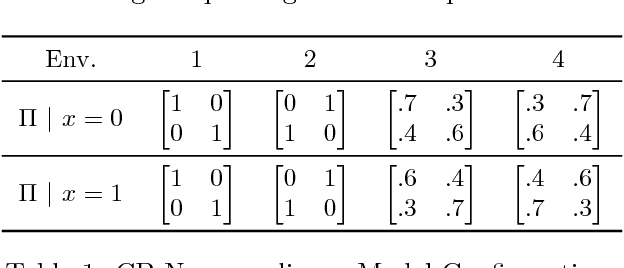
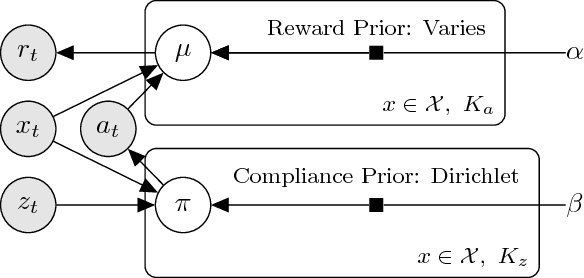
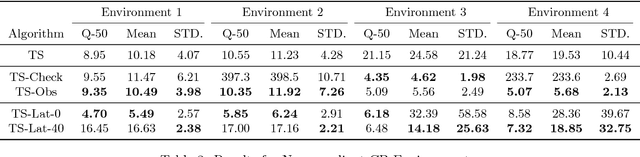
Thompson sampling, a Bayesian method for balancing exploration and exploitation in bandit problems, has theoretical guarantees and exhibits strong empirical performance in many domains. Traditional Thompson sampling, however, assumes perfect compliance, where an agent's chosen action is treated as the implemented action. This article introduces a stochastic noncompliance model that relaxes this assumption. We prove that any noncompliance in a 2-armed Bernoulli bandit increases existing regret bounds. With our noncompliance model, we derive Thompson sampling variants that explicitly handle both observed and latent noncompliance. With extensive empirical analysis, we demonstrate that our algorithms either match or outperform traditional Thompson sampling in both compliant and noncompliant environments.
Item Recommendation with Variational Autoencoders and Heterogenous Priors
Oct 07, 2018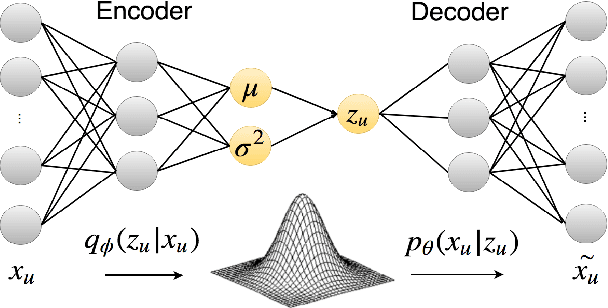
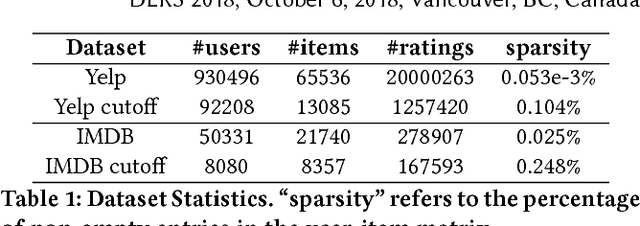
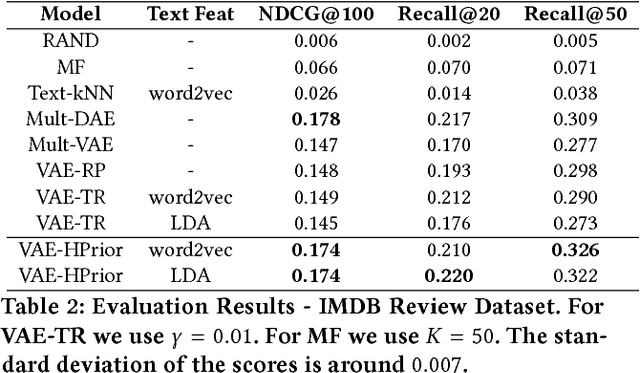
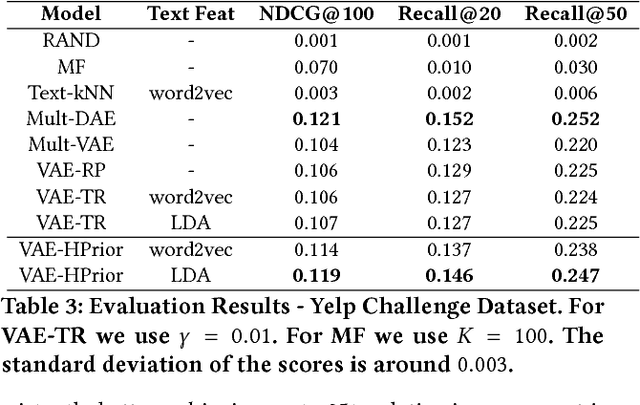
In recent years, Variational Autoencoders (VAEs) have been shown to be highly effective in both standard collaborative filtering applications and extensions such as incorporation of implicit feedback. We extend VAEs to collaborative filtering with side information, for instance when ratings are combined with explicit text feedback from the user. Instead of using a user-agnostic standard Gaussian prior, we incorporate user-dependent priors in the latent VAE space to encode users' preferences as functions of the review text. Taking into account both the rating and the text information to represent users in this multimodal latent space is promising to improve recommendation quality. Our proposed model is shown to outperform the existing VAE models for collaborative filtering (up to 29.41% relative improvement in ranking metric) along with other baselines that incorporate both user ratings and text for item recommendation.
Subgoal Discovery for Hierarchical Dialogue Policy Learning
Sep 22, 2018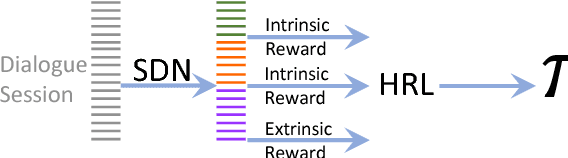
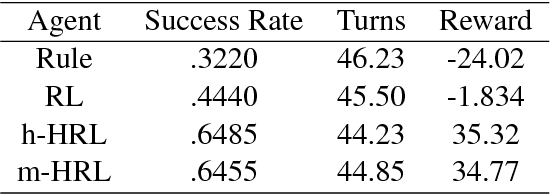
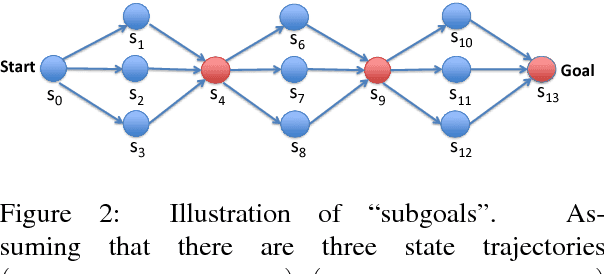

Developing agents to engage in complex goal-oriented dialogues is challenging partly because the main learning signals are very sparse in long conversations. In this paper, we propose a divide-and-conquer approach that discovers and exploits the hidden structure of the task to enable efficient policy learning. First, given successful example dialogues, we propose the Subgoal Discovery Network (SDN) to divide a complex goal-oriented task into a set of simpler subgoals in an unsupervised fashion. We then use these subgoals to learn a multi-level policy by hierarchical reinforcement learning. We demonstrate our method by building a dialogue agent for the composite task of travel planning. Experiments with simulated and real users show that our approach performs competitively against a state-of-the-art method that requires human-defined subgoals. Moreover, we show that the learned subgoals are often human comprehensible.