 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for Noncompliant Bandits
Paper and Code
Dec 03, 2018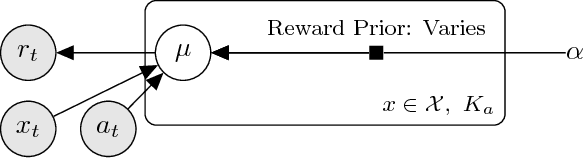
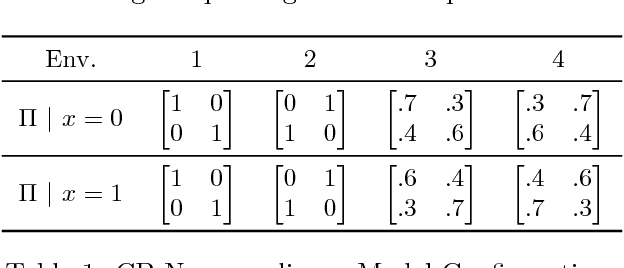
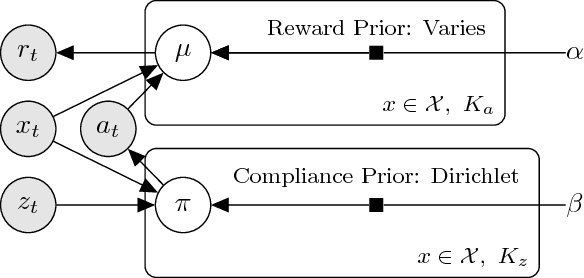
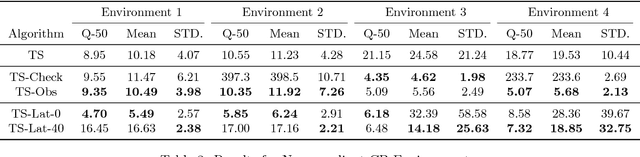
Thompson sampling, a Bayesian method for balancing exploration and exploitation in bandit problems, has theoretical guarantees and exhibits strong empirical performance in many domains. Traditional Thompson sampling, however, assumes perfect compliance, where an agent's chosen action is treated as the implemented action. This article introduces a stochastic noncompliance model that relaxes this assumption. We prove that any noncompliance in a 2-armed Bernoulli bandit increases existing regret bounds. With our noncompliance model, we derive Thompson sampling variants that explicitly handle both observed and latent noncompliance. With extensive empirical analysis, we demonstrate that our algorithms either match or outperform traditional Thompson sampling in both compliant and noncompliant environments.