 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnability-Driven Submodular Optimization for Active Roadside 3D Detection
Jan 04, 2026Roadside perception datasets are typically constructed via cooperative labeling between synchronized vehicle and roadside frame pairs. However, real deployment often requires annotation of roadside-only data due to hardware and privacy constraints. Even human experts struggle to produce accurate labels without vehicle-side data (image, LIDAR), which not only increases annotation difficulty and cost, but also reveals a fundamental learnability problem: many roadside-only scenes contain distant, blurred, or occluded objects whose 3D properties are ambiguous from a single view and can only be reliably annotated by cross-checking paired vehicle--roadside frames. We refer to such cases as inherently ambiguous samples. To reduce wasted annotation effort on inherently ambiguous samples while still obtaining high-performing models, we turn to active learning. This work focuses on active learning for roadside monocular 3D object detection and proposes a learnability-driven framework that selects scenes which are both informative and reliably labelable, suppressing inherently ambiguous samples while ensuring coverage. Experiments demonstrate that our method, LH3D, achieves 86.06%, 67.32%, and 78.67% of full-performance for vehicles, pedestrians, and cyclists respectively, using only 25% of the annotation budget on DAIR-V2X-I, significantly outperforming uncertainty-based baselines. This confirms that learnability, not uncertainty, matters for roadside 3D perception.
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
May 28, 2024



Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize the Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilize foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting. This methodology enables a straightforward matching strategy, resulting in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements of 22.3, 46.2, 10.3, and 24.0 in average precision (AP) across four detection datasets. In instance segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the top RGB methods by 3.6 AP and remains competitive with the best RGB-D method. Code is available at: https://github.com/YoungSean/NIDS-Net
CaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023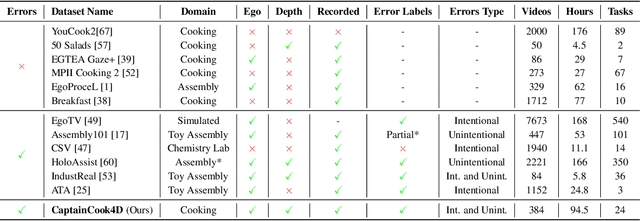


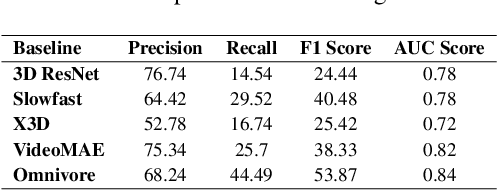
Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning
Self-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction
Feb 07, 2023



We introduce a novel robotic system for improving unseen object instance segmentation in the real world by leveraging long-term robot interaction with objects. Previous approaches either grasp or push an object and then obtain the segmentation mask of the grasped or pushed object after one action. Instead, our system defers the decision on segmenting objects after a sequence of robot pushing actions. By applying multi-object tracking and video object segmentation on the images collected via robot pushing, our system can generate segmentation masks of all the objects in these images in a self-supervised way. These include images where objects are very close to each other, and segmentation errors usually occur on these images for existing object segmentation networks. We demonstrate the usefulness of our system by fine-tuning segmentation networks trained on synthetic data with real-world data collected by our system. We show that, after fine-tuning, the segmentation accuracy of the networks is significantly improved both in the same domain and across different domains. In addition, we verify that the fine-tuned networks improve top-down robotic grasping of unseen objects in the real world.
Mean Shift Mask Transformer for Unseen Object Instance Segmentation
Nov 21, 2022
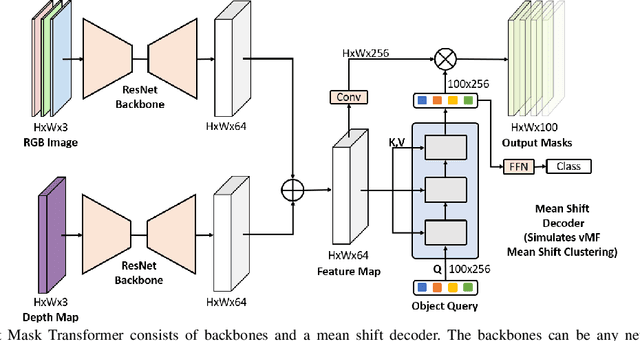
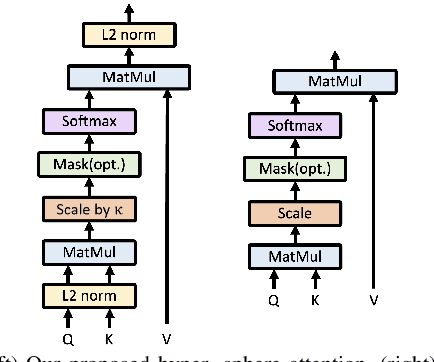
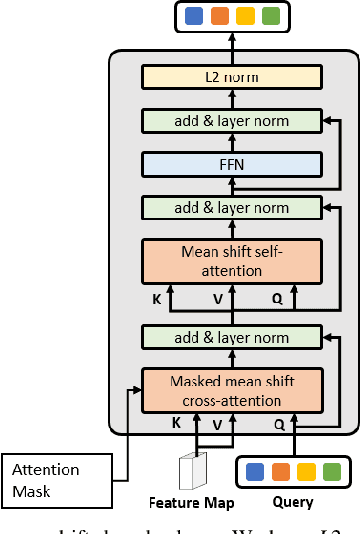
Segmenting unseen objects is a critical task in many different domains. For example, a robot may need to grasp an unseen object, which means it needs to visually separate this object from the background and/or other objects. Mean shift clustering is a common method in object segmentation tasks. However, the traditional mean shift clustering algorithm is not easily integrated into an end-to-end neural network training pipeline. In this work, we propose the Mean Shift Mask Transformer (MSMFormer), a new transformer architecture that simulates the von Mises-Fisher (vMF) mean shift clustering algorithm, allowing for the joint training and inference of both the feature extractor and the clustering. Its central component is a hypersphere attention mechanism, which updates object queries on a hypersphere. To illustrate the effectiveness of our method, we apply MSMFormer to Unseen Object Instance Segmentation, which yields a new state-of-the-art of 87.3 Boundary F-meansure on the real-world Object Clutter Indoor Dataset (OCID). Code is available at https://github.com/YoungSean/UnseenObjectsWithMeanShift
Relational Neural Markov Random Fields
Oct 18, 2021


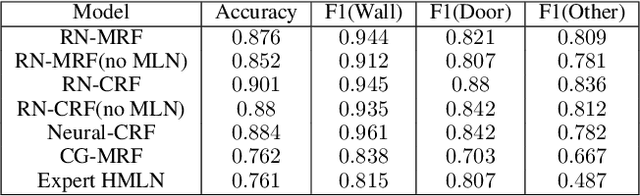
Statistical Relational Learning (SRL) models have attracted significant attention due to their ability to model complex data while handling uncertainty. However, most of these models have been limited to discrete domains due to their limited potential functions. We introduce Relational Neural Markov Random Fields (RN-MRFs) which allow for handling of complex relational hybrid domains. The key advantage of our model is that it makes minimal data distributional assumptions and can seamlessly allow for human knowledge through potentials or relational rules. We propose a maximum pseudolikelihood estimation-based learning algorithm with importance sampling for training the neural potential parameters. Our empirical evaluations across diverse domains such as image processing and relational object mapping, clearly demonstrate its effectiveness against non-neural counterparts.
Don't Explain without Verifying Veracity: An Evaluation of Explainable AI with Video Activity Recognition
May 05, 2020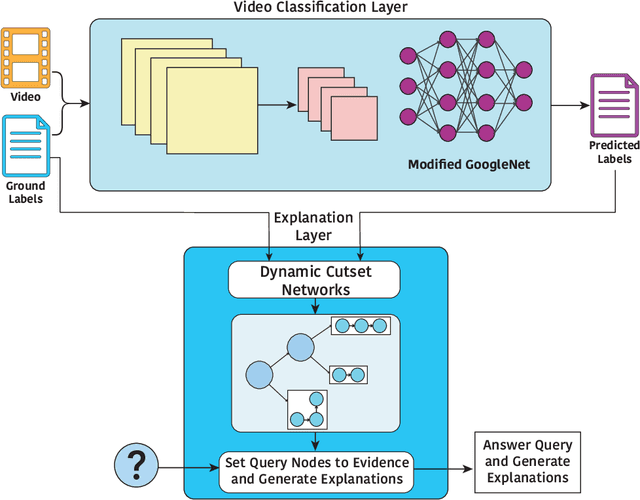
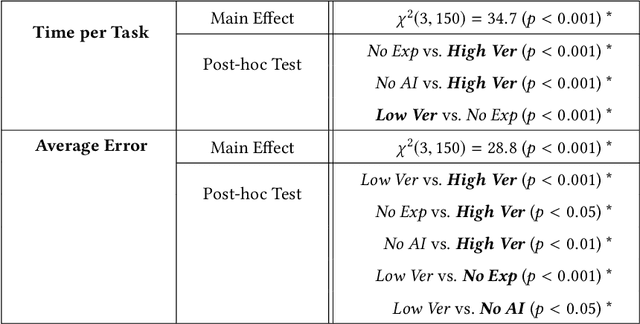

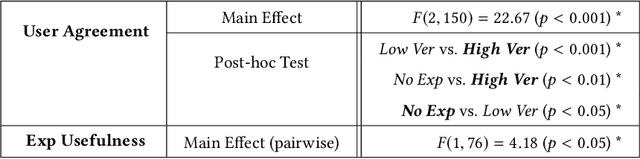
Explainable machine learning and artificial intelligence models have been used to justify a model's decision-making process. This added transparency aims to help improve user performance and understanding of the underlying model. However, in practice, explainable systems face many open questions and challenges. Specifically, designers might reduce the complexity of deep learning models in order to provide interpretability. The explanations generated by these simplified models, however, might not accurately justify and be truthful to the model. This can further add confusion to the users as they might not find the explanations meaningful with respect to the model predictions. Understanding how these explanations affect user behavior is an ongoing challenge. In this paper, we explore how explanation veracity affects user performance and agreement in intelligent systems. Through a controlled user study with an explainable activity recognition system, we compare variations in explanation veracity for a video review and querying task. The results suggest that low veracity explanations significantly decrease user performance and agreement compared to both accurate explanations and a system without explanations. These findings demonstrate the importance of accurate and understandable explanations and caution that poor explanations can sometimes be worse than no explanations with respect to their effect on user performance and reliance on an AI system.
Lifted Hybrid Variational Inference
Feb 08, 2020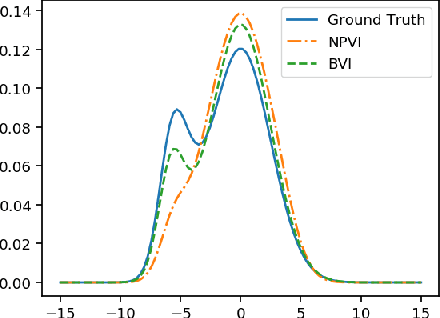
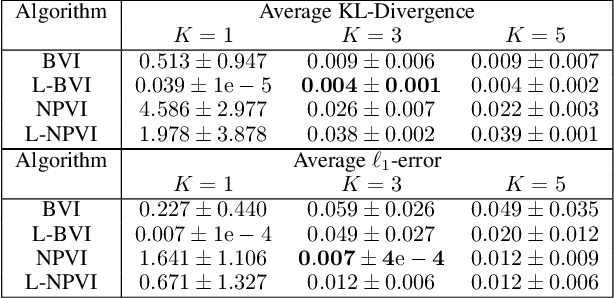
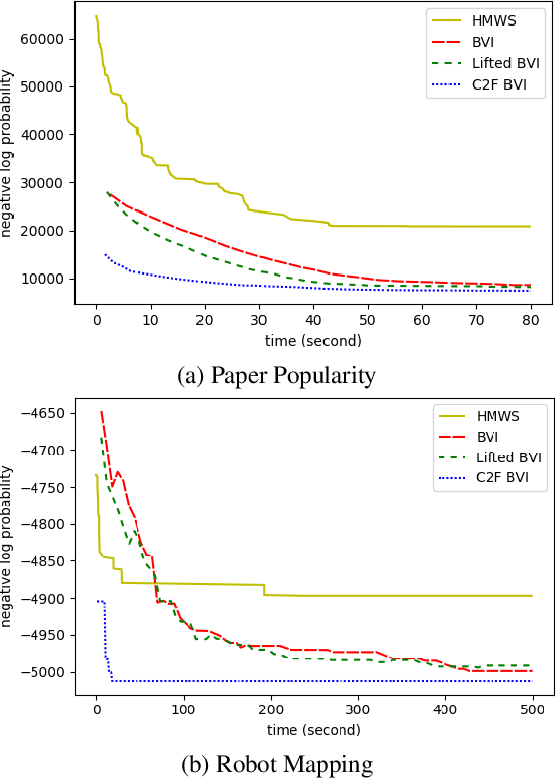
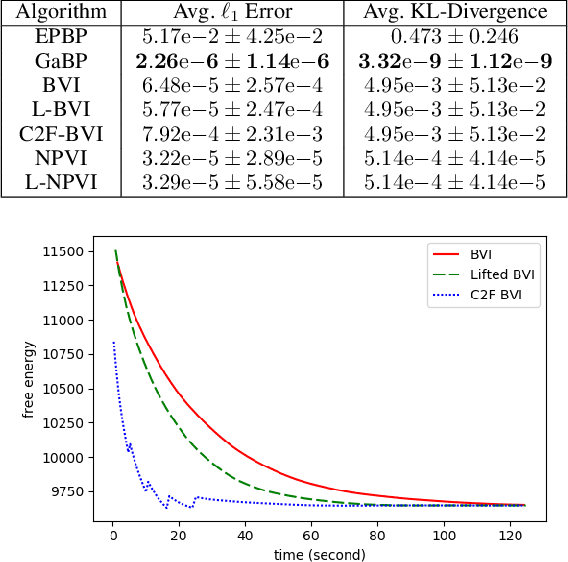
A variety of lifted inference algorithms, which exploit model symmetry to reduce computational cost, have been proposed to render inference tractable in probabilistic relational models. Most existing lifted inference algorithms operate only over discrete domains or continuous domains with restricted potential functions, e.g., Gaussian. We investigate two approximate lifted variational approaches that are applicable to hybrid domains and expressive enough to capture multi-modality. We demonstrate that the proposed variational methods are both scalable and can take advantage of approximate model symmetries, even in the presence of a large amount of continuous evidence. We demonstrate that our approach compares favorably against existing message-passing based approaches in a variety of settings. Finally, we present a sufficient condition for the Bethe approximation to yield a non-trivial estimate over the marginal polytope.
Learning Correlated Latent Representations with Adaptive Priors
Jul 16, 2019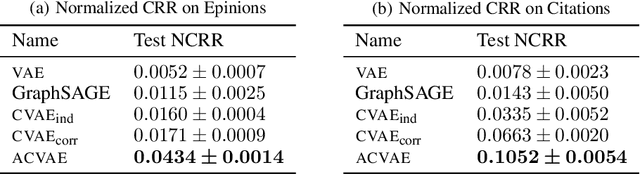
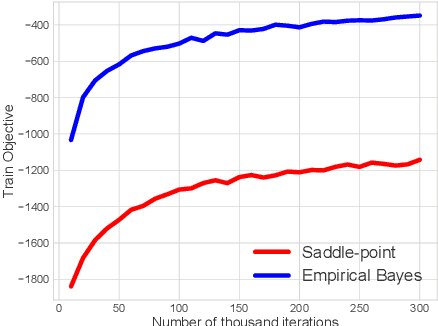
Variational Auto-Encoders (VAEs) have been widely applied for learning compact low-dimensional latent representations for high-dimensional data. When the correlation structure among data points is available, previous work proposed Correlated Variational Auto-Encoders (CVAEs) which employ a structured mixture model as prior and a structured variational posterior for each mixture component to enforce the learned latent representations to follow the same correlation structure. However, as we demonstrate in this paper, such a choice can not guarantee that CVAEs can capture all of the correlations. Furthermore, it prevents us from obtaining a tractable joint and marginal variational distribution. To address these issues, we propose Adaptive Correlated Variational Auto-Encoders (ACVAEs), which apply an adaptive prior distribution that can be adjusted during training, and learn a tractable joint distribution via a saddle-point optimization procedure. Its tractable form also enables further refinement with belief propagation. Experimental results on two real datasets show that ACVAEs outperform other benchmarks significantly.
Correlated Variational Auto-Encoders
May 16, 2019
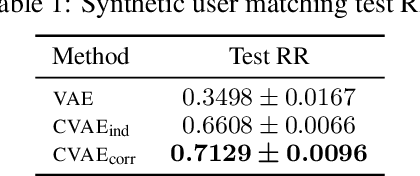

Variational Auto-Encoders (VAEs) are capable of learning latent representations for high dimensional data. However, due to the i.i.d. assumption, VAEs only optimize the singleton variational distributions and fail to account for the correlations between data points, which might be crucial for learning latent representations from dataset where a priori we know correlations exist. We propose Correlated Variational Auto-Encoders (CVAEs) that can take the correlation structure into consideration when learning latent representations with VAEs. CVAEs apply a prior based on the correlation structure. To address the intractability introduced by the correlated prior, we develop an approximation by average of a set of tractable lower bounds over all maximal acyclic subgraphs of the undirected correlation graph. Experimental results on matching and link prediction on public benchmark rating datasets and spectral clustering on a synthetic dataset show the effectiveness of the proposed method over baseline algorithms.