 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-entries: Encouraging Deeper Evaluation of Mental Models Over Time for Interactive Data Systems
Sep 02, 2020


Many interactive data systems combine visual representations of data with embedded algorithmic support for automation and data exploration. To effectively support transparent and explainable data systems, it is important for researchers and designers to know how users understand the system. We discuss the evaluation of users' mental models of system logic. Mental models are challenging to capture and analyze. While common evaluation methods aim to approximate the user's final mental model after a period of system usage, user understanding continuously evolves as users interact with a system over time. In this paper, we review many common mental model measurement techniques, discuss tradeoffs, and recommend methods for deeper, more meaningful evaluation of mental models when using interactive data analysis and visualization systems. We present guidelines for evaluating mental models over time that reveal the evolution of specific model updates and how they may map to the particular use of interface features and data queries. By asking users to describe what they know and how they know it, researchers can collect structured, time-ordered insight into a user's conceptualization process while also helping guide users to their own discoveries.
Soliciting Human-in-the-Loop User Feedback for Interactive Machine Learning Reduces User Trust and Impressions of Model Accuracy
Aug 28, 2020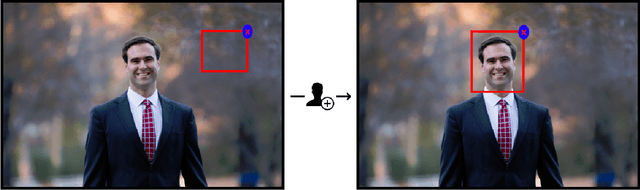
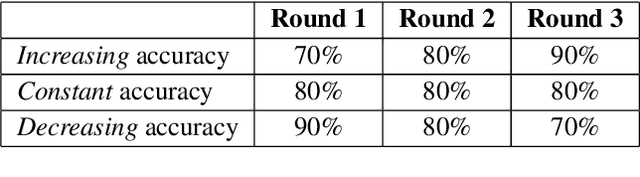
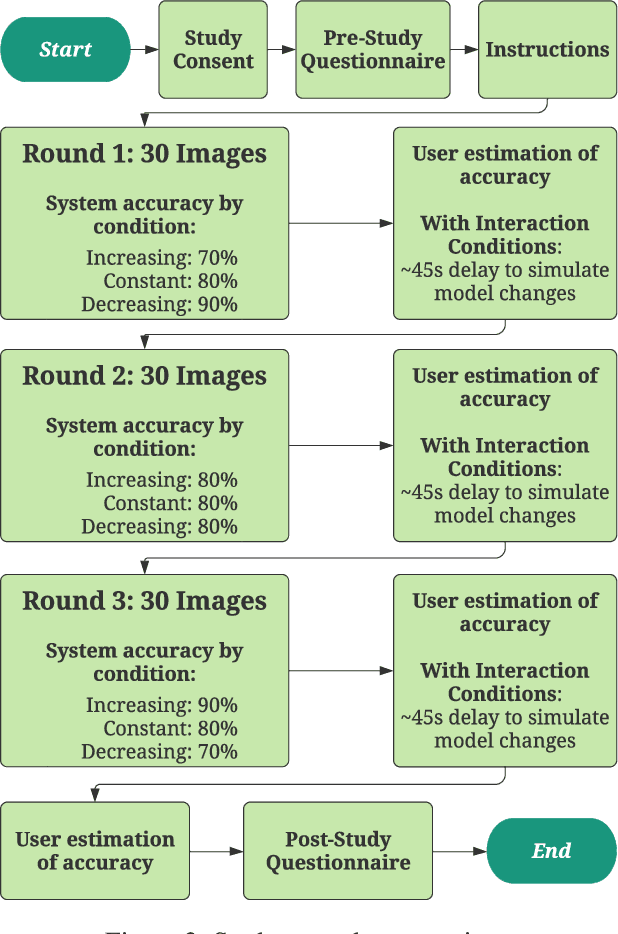
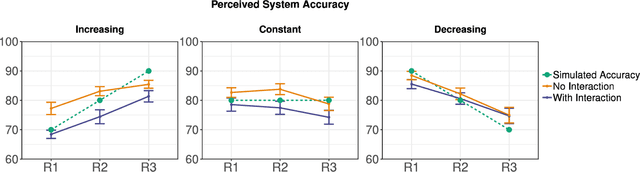
Mixed-initiative systems allow users to interactively provide feedback to potentially improve system performance. Human feedback can correct model errors and update model parameters to dynamically adapt to changing data. Additionally, many users desire the ability to have a greater level of control and fix perceived flaws in systems they rely on. However, how the ability to provide feedback to autonomous systems influences user trust is a largely unexplored area of research. Our research investigates how the act of providing feedback can affect user understanding of an intelligent system and its accuracy. We present a controlled experiment using a simulated object detection system with image data to study the effects of interactive feedback collection on user impressions. The results show that providing human-in-the-loop feedback lowered both participants' trust in the system and their perception of system accuracy, regardless of whether the system accuracy improved in response to their feedback. These results highlight the importance of considering the effects of allowing end-user feedback on user trust when designing intelligent systems.
The Role of Domain Expertise in User Trust and the Impact of First Impressions with Intelligent Systems
Aug 20, 2020
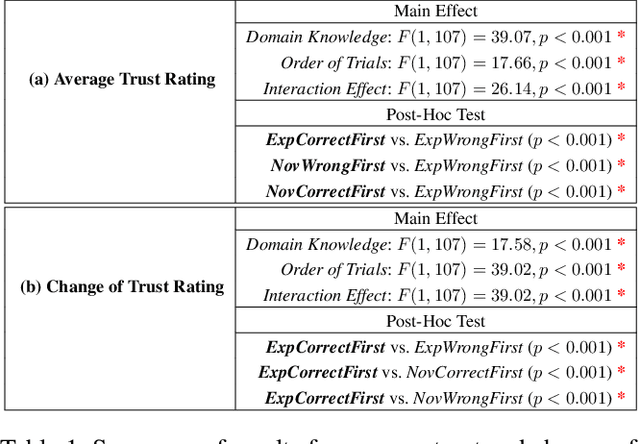


Domain-specific intelligent systems are meant to help system users in their decision-making process. Many systems aim to simultaneously support different users with varying levels of domain expertise, but prior domain knowledge can affect user trust and confidence in detecting system errors. While it is also known that user trust can be influenced by first impressions with intelligent systems, our research explores the relationship between ordering bias and domain expertise when encountering errors in intelligent systems. In this paper, we present a controlled user study to explore the role of domain knowledge in establishing trust and susceptibility to the influence of first impressions on user trust. Participants reviewed an explainable image classifier with a constant accuracy and two different orders of observing system errors (observing errors in the beginning of usage vs. in the end). Our findings indicate that encountering errors early-on can cause negative first impressions for domain experts, negatively impacting their trust over the course of interactions. However, encountering correct outputs early helps more knowledgable users to dynamically adjust their trust based on their observations of system performance. In contrast, novice users suffer from over-reliance due to their lack of proper knowledge to detect errors.
Don't Explain without Verifying Veracity: An Evaluation of Explainable AI with Video Activity Recognition
May 05, 2020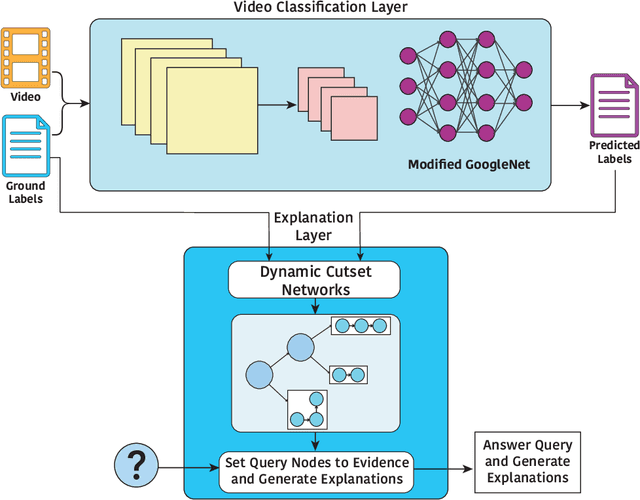
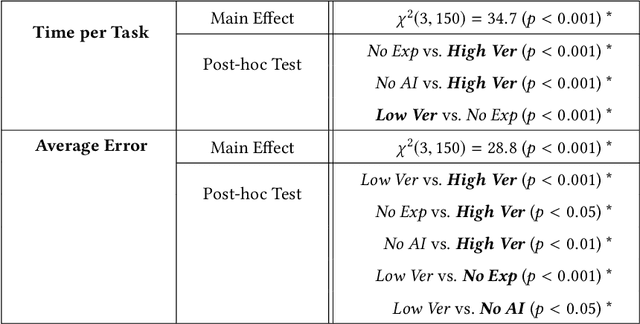

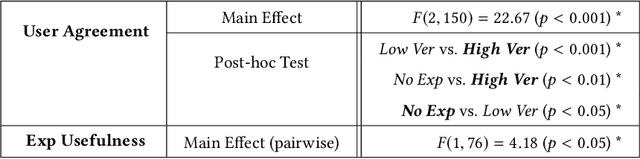
Explainable machine learning and artificial intelligence models have been used to justify a model's decision-making process. This added transparency aims to help improve user performance and understanding of the underlying model. However, in practice, explainable systems face many open questions and challenges. Specifically, designers might reduce the complexity of deep learning models in order to provide interpretability. The explanations generated by these simplified models, however, might not accurately justify and be truthful to the model. This can further add confusion to the users as they might not find the explanations meaningful with respect to the model predictions. Understanding how these explanations affect user behavior is an ongoing challenge. In this paper, we explore how explanation veracity affects user performance and agreement in intelligent systems. Through a controlled user study with an explainable activity recognition system, we compare variations in explanation veracity for a video review and querying task. The results suggest that low veracity explanations significantly decrease user performance and agreement compared to both accurate explanations and a system without explanations. These findings demonstrate the importance of accurate and understandable explanations and caution that poor explanations can sometimes be worse than no explanations with respect to their effect on user performance and reliance on an AI system.
XFake: Explainable Fake News Detector with Visualizations
Jul 08, 2019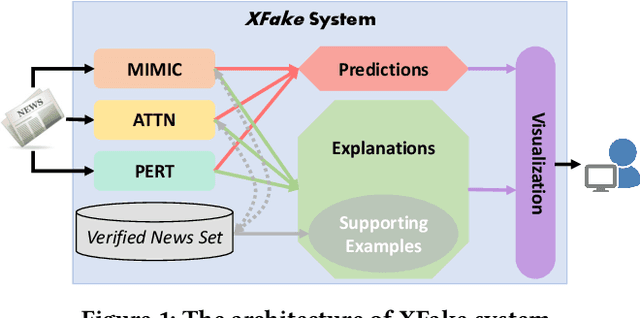
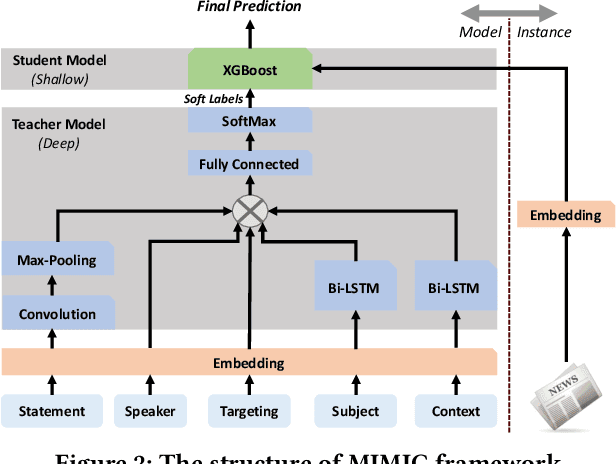
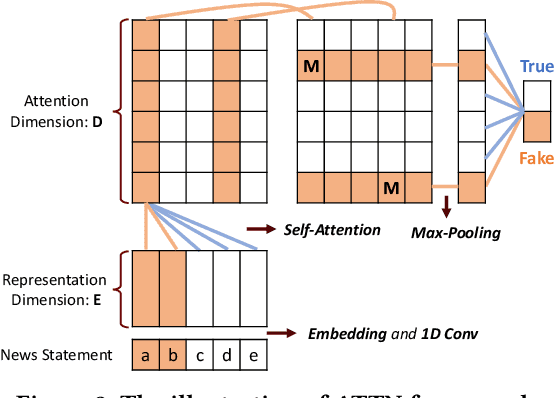
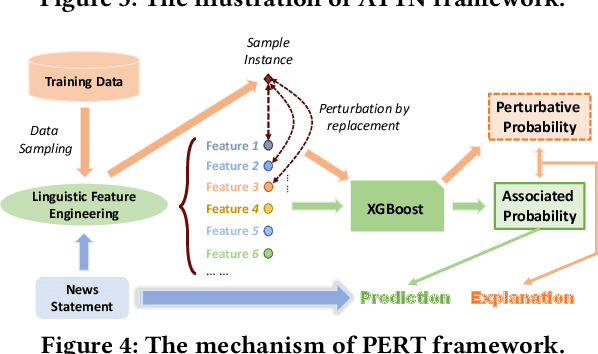
In this demo paper, we present the XFake system, an explainable fake news detector that assists end-users to identify news credibility. To effectively detect and interpret the fakeness of news items, we jointly consider both attributes (e.g., speaker) and statements. Specifically, MIMIC, ATTN and PERT frameworks are designed, where MIMIC is built for attribute analysis, ATTN is for statement semantic analysis and PERT is for statement linguistic analysis. Beyond the explanations extracted from the designed frameworks, relevant supporting examples as well as visualization are further provided to facilitate the interpretation. Our implemented system is demonstrated on a real-world dataset crawled from PolitiFact, where thousands of verified political news have been collected.
A Human-Grounded Evaluation Benchmark for Local Explanations of Machine Learning
Jan 16, 2018
In order for people to be able to trust and take advantage of the results of advanced machine learning and artificial intelligence solutions for real decision making, people need to be able to understand the machine rationale for given output. Research in explain artificial intelligence (XAI) addresses the aim, but there is a need for evaluation of human relevance and understandability of explanations. Our work contributes a novel methodology for evaluating the quality or human interpretability of explanations for machine learning models. We present an evaluation benchmark for instance explanations from text and image classifiers. The explanation meta-data in this benchmark is generated from user annotations of image and text samples. We describe the benchmark and demonstrate its utility by a quantitative evaluation on explanations generated from a recent machine learning algorithm. This research demonstrates how human-grounded evaluation could be used as a measure to qualify local machine-learning explanations.