 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Explain without Verifying Veracity: An Evaluation of Explainable AI with Video Activity Recognition
May 05, 2020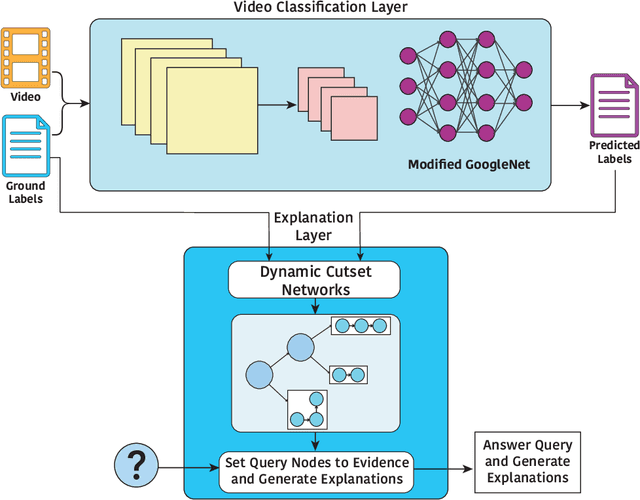
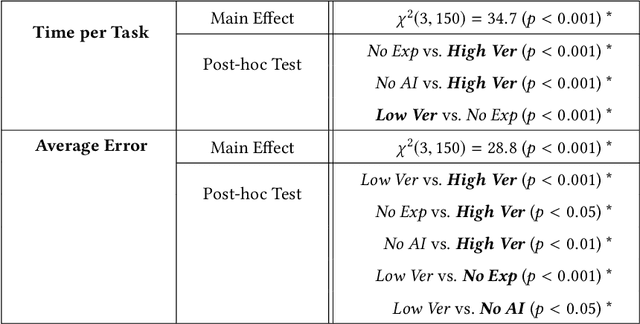

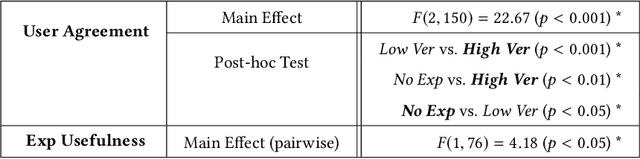
Explainable machine learning and artificial intelligence models have been used to justify a model's decision-making process. This added transparency aims to help improve user performance and understanding of the underlying model. However, in practice, explainable systems face many open questions and challenges. Specifically, designers might reduce the complexity of deep learning models in order to provide interpretability. The explanations generated by these simplified models, however, might not accurately justify and be truthful to the model. This can further add confusion to the users as they might not find the explanations meaningful with respect to the model predictions. Understanding how these explanations affect user behavior is an ongoing challenge. In this paper, we explore how explanation veracity affects user performance and agreement in intelligent systems. Through a controlled user study with an explainable activity recognition system, we compare variations in explanation veracity for a video review and querying task. The results suggest that low veracity explanations significantly decrease user performance and agreement compared to both accurate explanations and a system without explanations. These findings demonstrate the importance of accurate and understandable explanations and caution that poor explanations can sometimes be worse than no explanations with respect to their effect on user performance and reliance on an AI system.
Structure Learning Using Forced Pruning
Dec 03, 2018

Markov networks are widely used in many Machine Learning applications including natural language processing, computer vision, and bioinformatics . Learning Markov networks have many complications ranging from intractable computations involved to the possibility of learning a model with a huge number of parameters. In this report, we provide a computationally tractable greedy heuristic for learning Markov networks structure. The proposed heuristic results in a model with a limited predefined number of parameters. We ran our method on 3 fully-observed real datasets, and we observed that our method is doing comparably good to the state of the art methods.